AWS Redshift Query editor
AWS RedshiftのQuery editorはコンソール上から作成済みのredshiftに対してクエリを直接実行できるサービスです。
JDBC/ODBCクライアントを利用せずともクエリを実行でき、その場で実行結果を確認、結果をファイルとして取得することが可能です。
また、クエリを保存しておく機能もあり、クエリの再利用が可能です。
2019/02/25現在、ノードタイプがdc1.8xlarge, dc2.large, dc2.8xlarge, ds2.8xlargeのものに限り利用することができます。
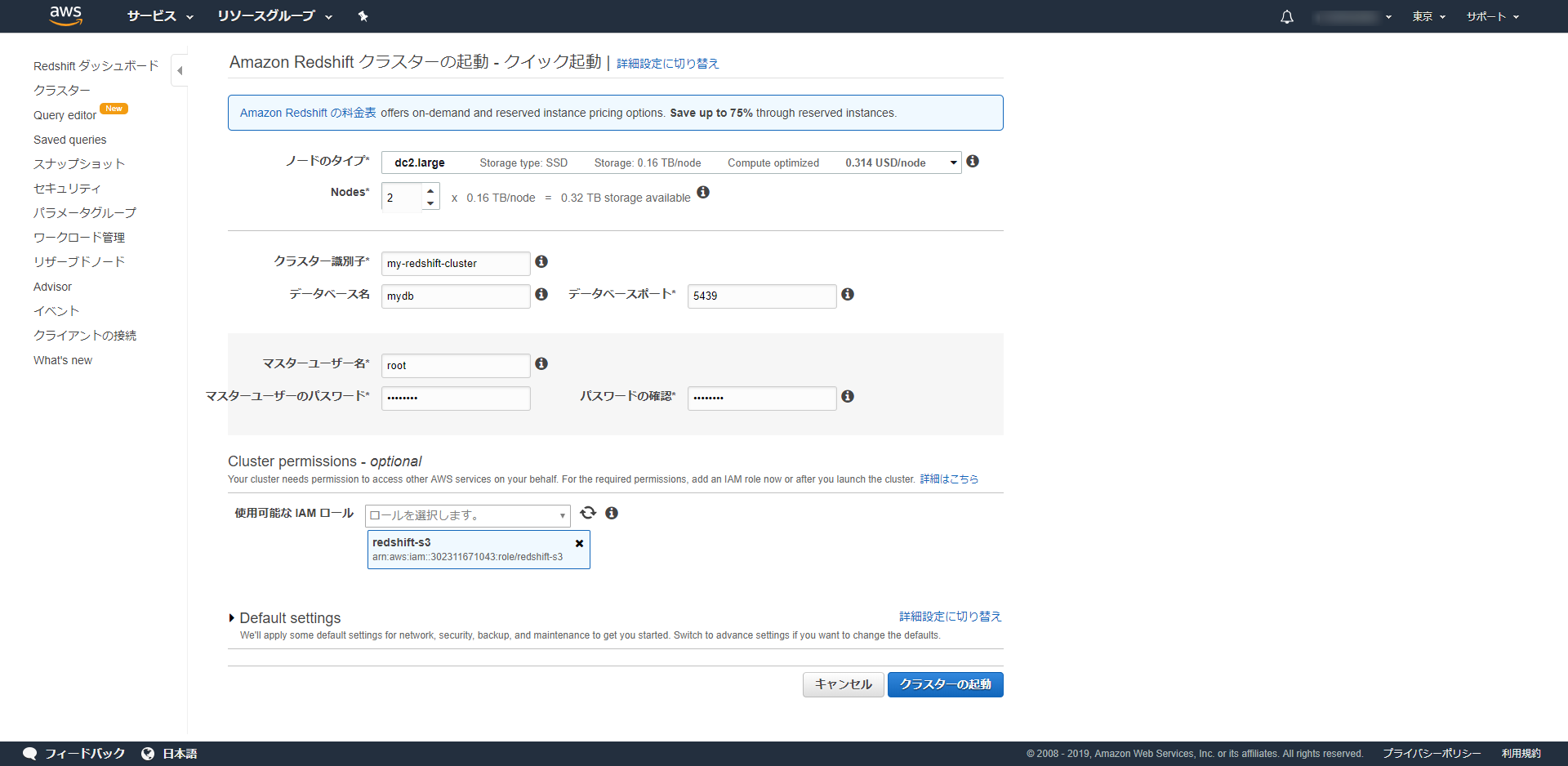
クラスターの準備
今回はQuery editorで対応しているノードタイプの中で一番小さいdc2.largeを選択しました。
Query editorの準備
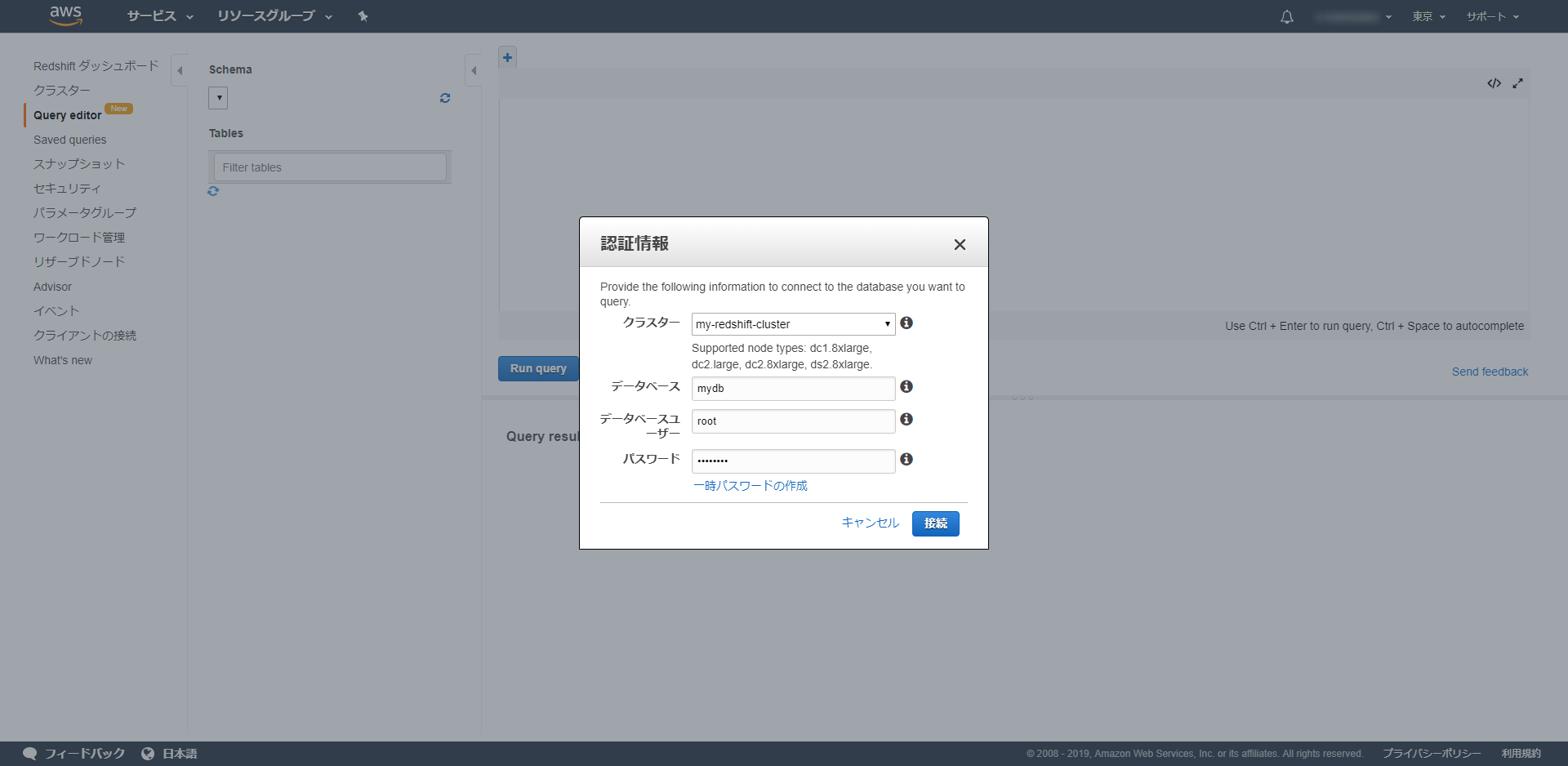
Query editorへ移動し先程作成したクラスター名とDB名、ユーザー、パスワードを入力します。
これだけで準備は完了です。
Query editorの使用
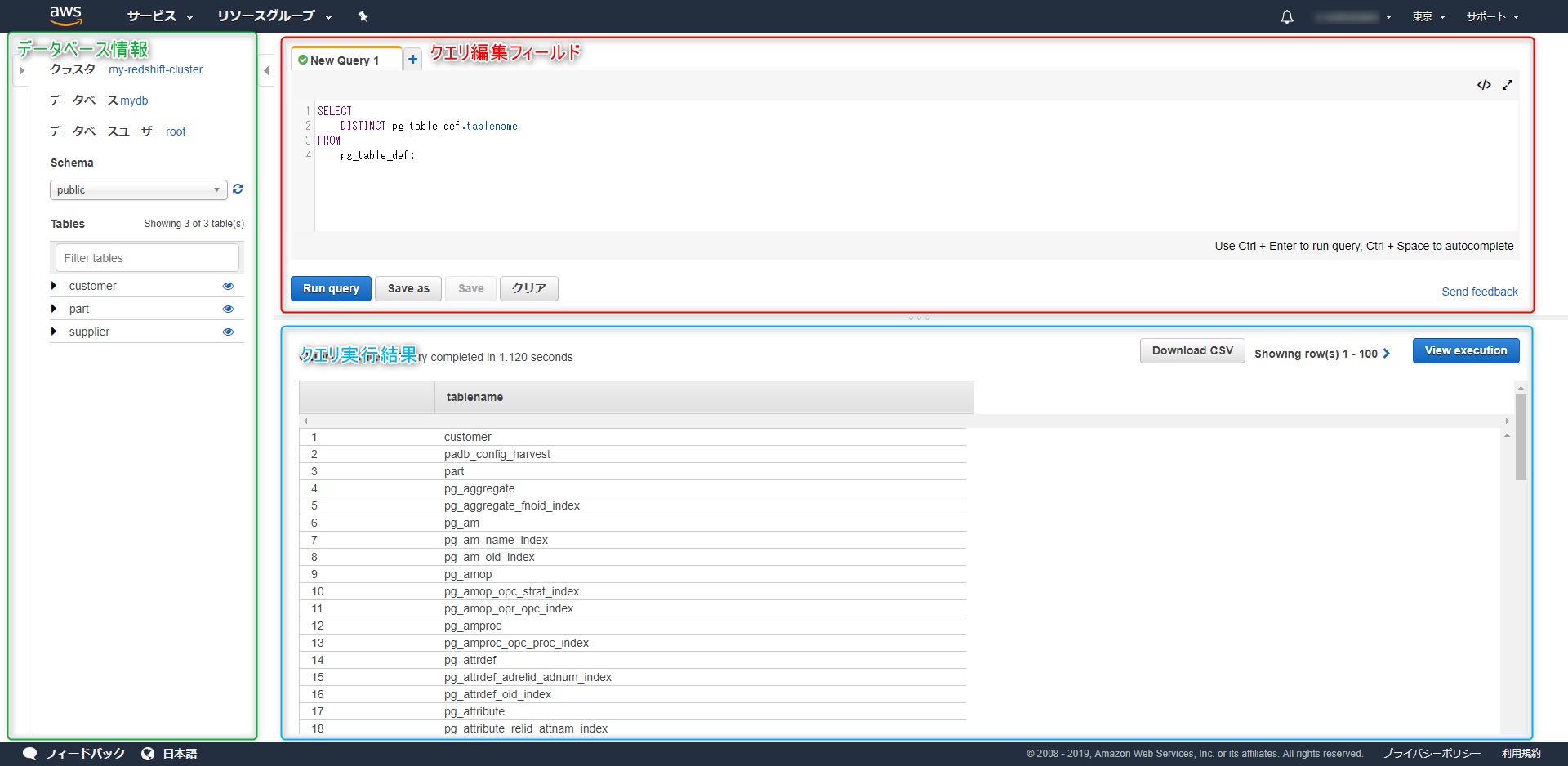
Query editorはデータベース情報のフィールド、クエリ編集のフィールド、クエリ実行結果のフィールドで構成されています。
以下はテーブルの一覧取得を試した結果となります。
「Download CSV」からクエリの実行結果をCSVファイルとして取得できます。
「View execution」からは各ステップの実行にかかった時間をグラフとして確認することができます。
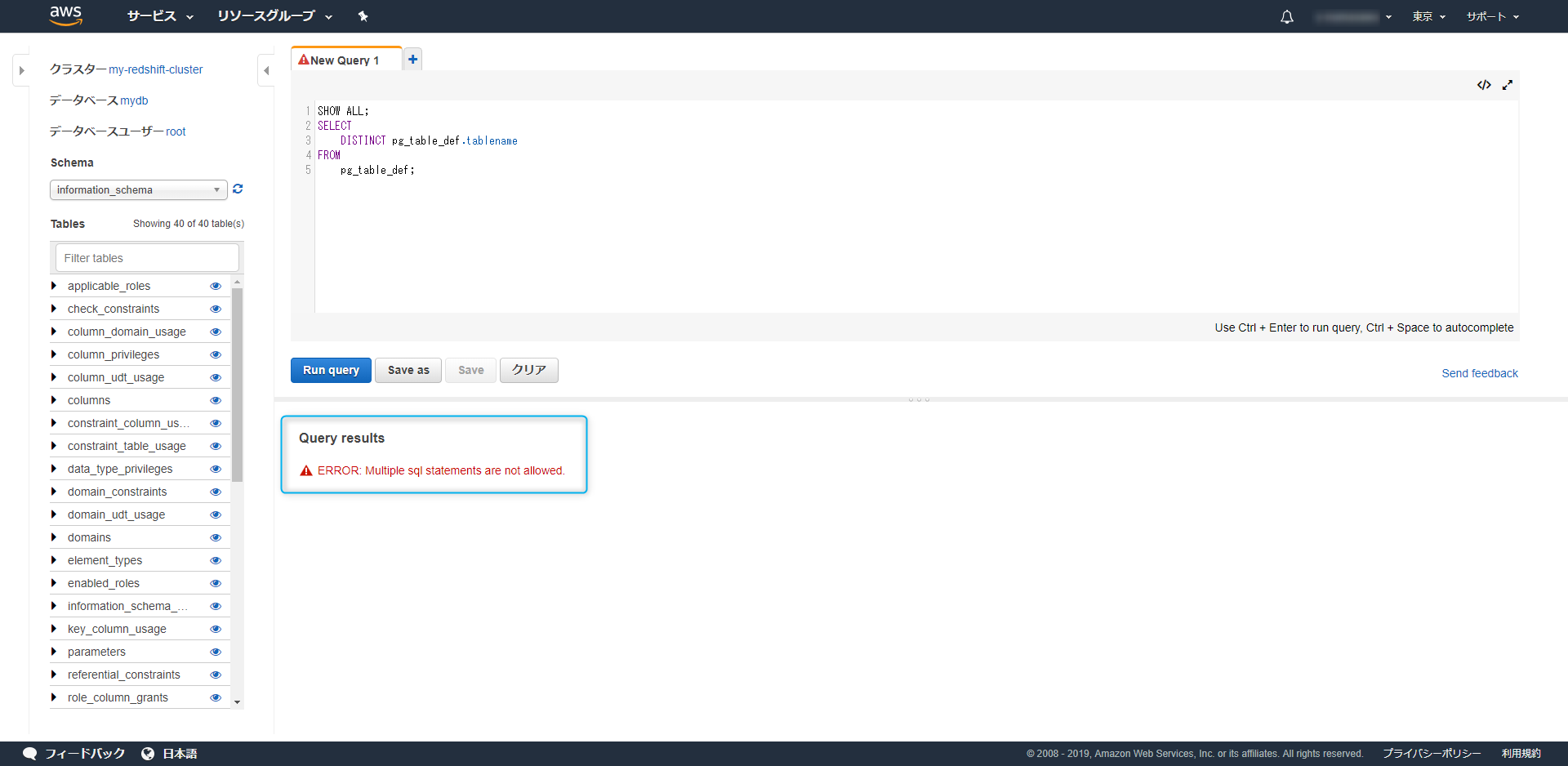
クエリは1回の実行につき1行までで、複数行実行しようとするとエラーになります。
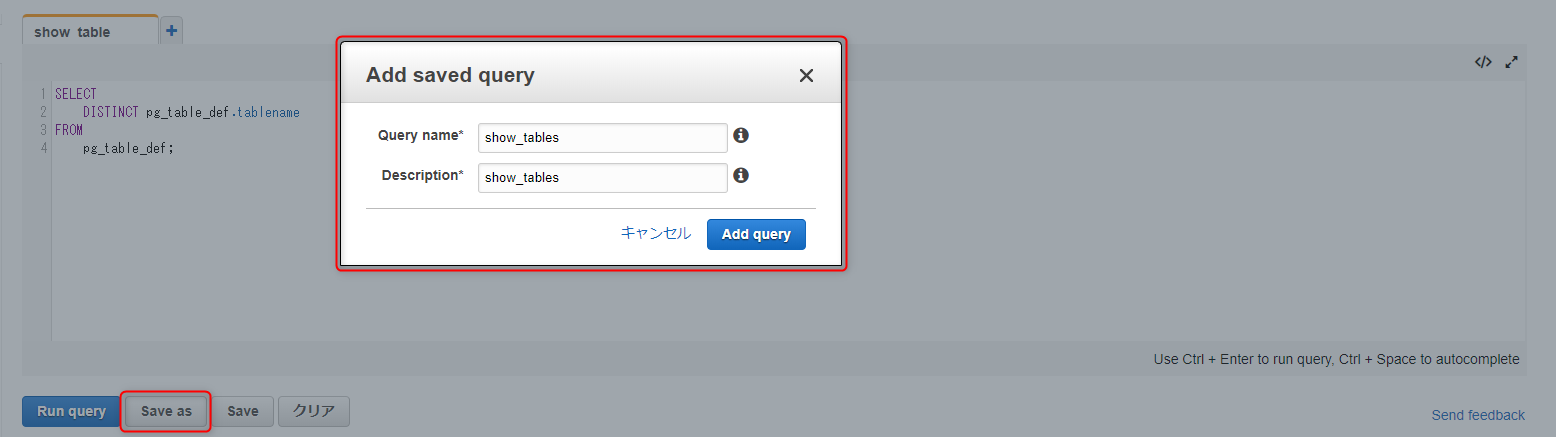
「Save as」からクエリを保存することができます。
名前と説明の入力が必要です。
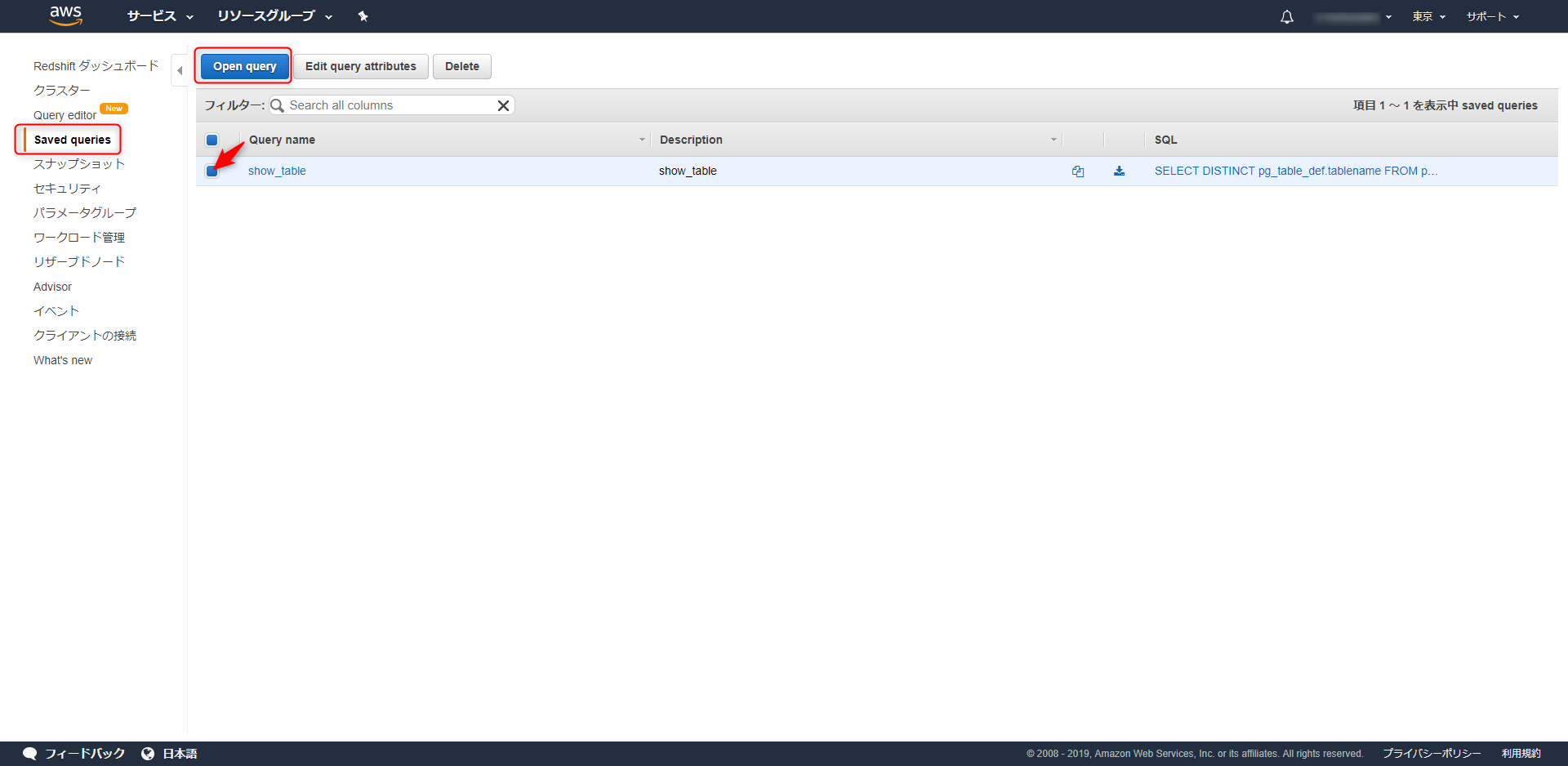
保存したクエリは「Saved queries」に一覧で表示されます。
使用したいクエリを選択し「Open query」をクリックすると自動的にデータベースへ接続され実行可能な状態となります。
クライアントのインストールや設定など行う必要がなく、コンソールから直接クエリを実行できるQuery editor
1回で1行までの実行など制約はあるもののちょっと試したい時など役に立つのではないでしょうか。
