今回は Udemy で Python のデータサイエンス入門をやったので、その内容を記事にまとめました。
受講した Udemy のコース
【ゼロから始めるデータ分析】 ビジネスケースで学ぶ Python データサイエンス入門
Udemy のコースの内容は、3つの記事に分けて投稿します(今回は、その1)。
・その1. Amazon SageMaker の環境構築、事前準備、基礎分析と可視化について ←【本稿】
・その2. 線形回帰を用いたお弁当の売り上げ予測
・その3. 決定木を用いた銀行の顧客ターゲティング
※ Udemy では Anaconda を使用してますが、自分は Amazon SageMaker を使用しました。
※環境構築についても Amazon SageMaker を使用した手順を記載します。
本稿の内容
・Amazon SageMaker で Python を使うための環境構築
・利用するデータのダウンロードと Jupyter にアップロード
・使用する Python の基本コードについて紹介
前提
・AWSのアカウントを用意します。
※AWSアカウント作成の流れはこちら
・SIGNATE のアカウントを用意します。
※SIGNATEアカウントの作成はこちら
環境構築
Amazon SageMaker で環境構築
Amazon SageMaker でノートブックインスタンスを作成し、Jupyter を開いて、フォルダの作成をします。
・AWS にログインし、Amazon SageMaker を検索。
・左の一覧からノートブックインスタンスを選択。
・右上のノートブックインスタンスの作成を選択。
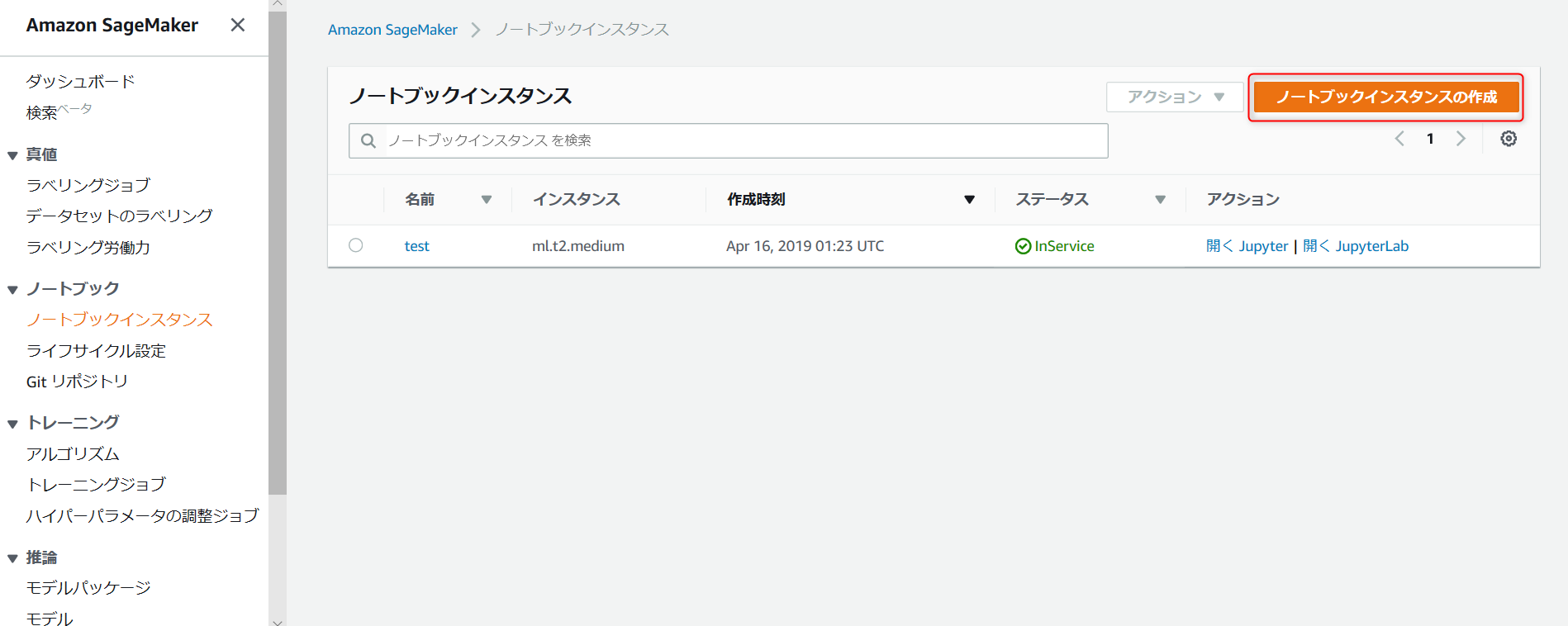
・ノートブックインスタンス名を入力(インスタンス名は任意)
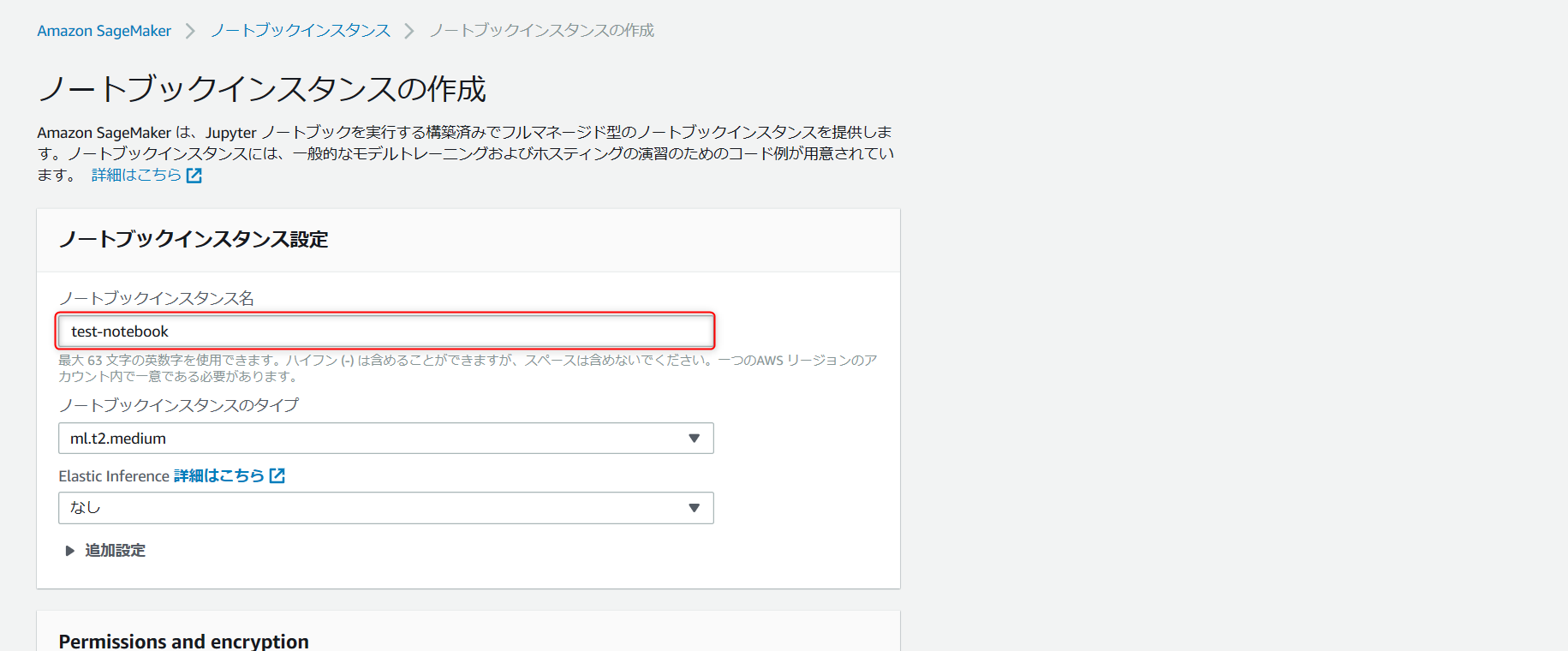
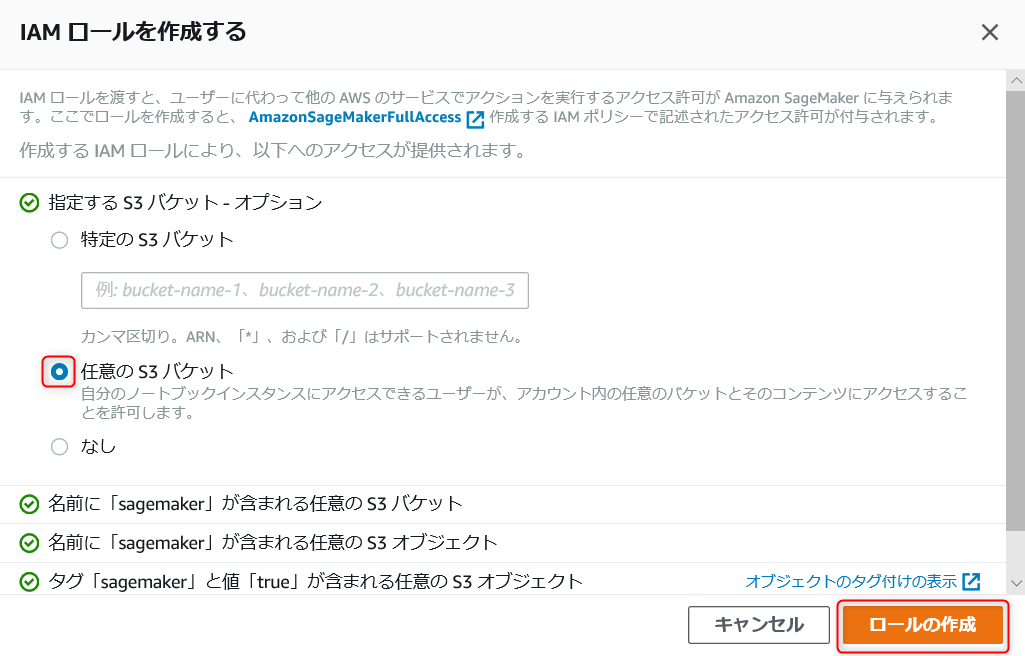
・下にスライドして、上の赤枠の部分を選択して、新しいロールの作成を選択。
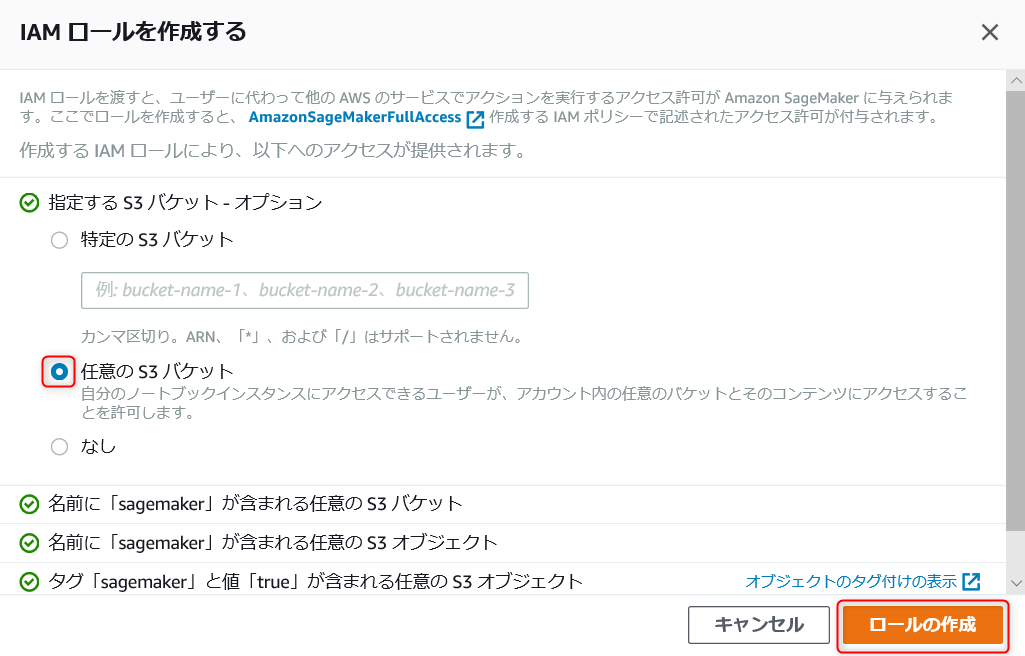
・任意の S3 バケットを選択し、ロールの作成を選択します。
※今回は任意の S3 バケットを選択していますが、実際に運用する際は適切な IAM ロールを設定して下さい。
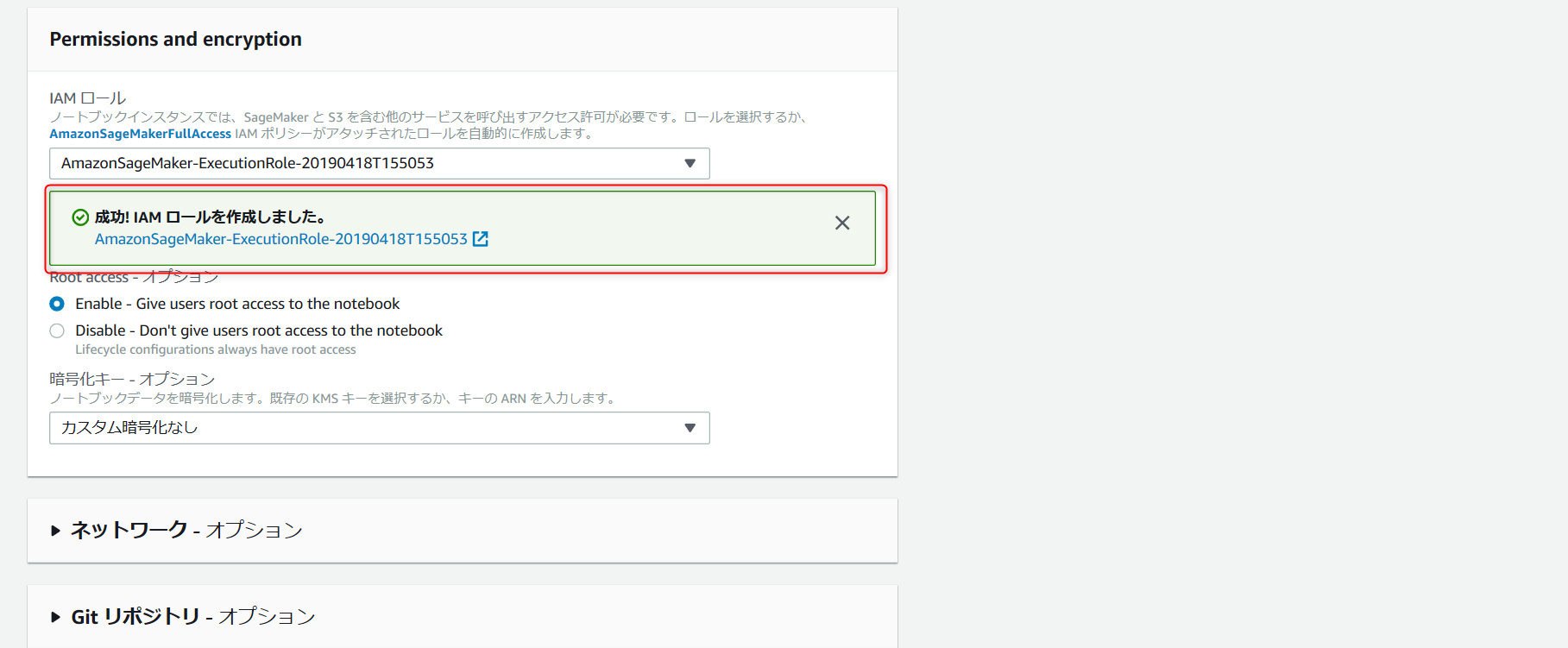
・赤枠のように表示されたら IAM ロールの作成は成功です。
・下にスライドして、ノートブックインスタンスの作成を選択。
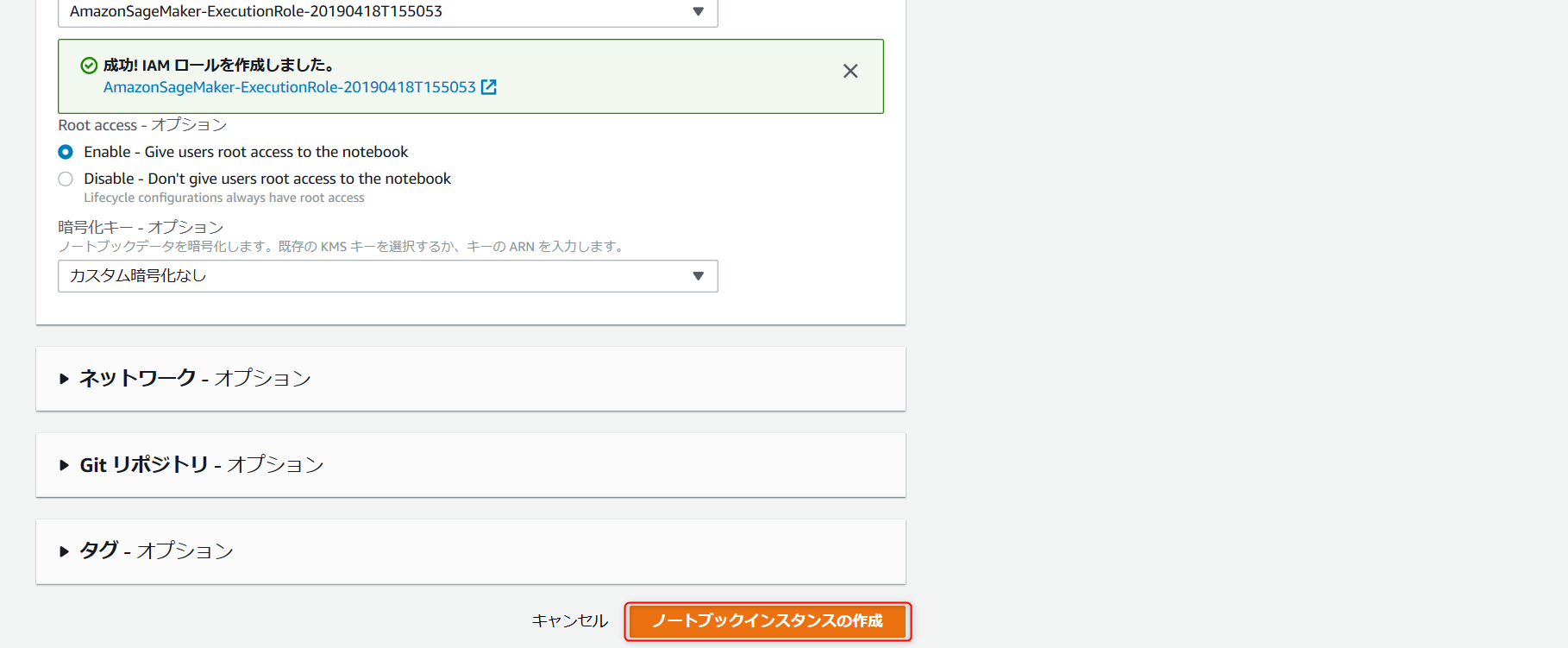
・画像上部の赤枠のように表示されたらノートブックインスタンスの作成は完了です。
ステータスが「 Pending 」 → 「 InService 」 になるまで待ちます。
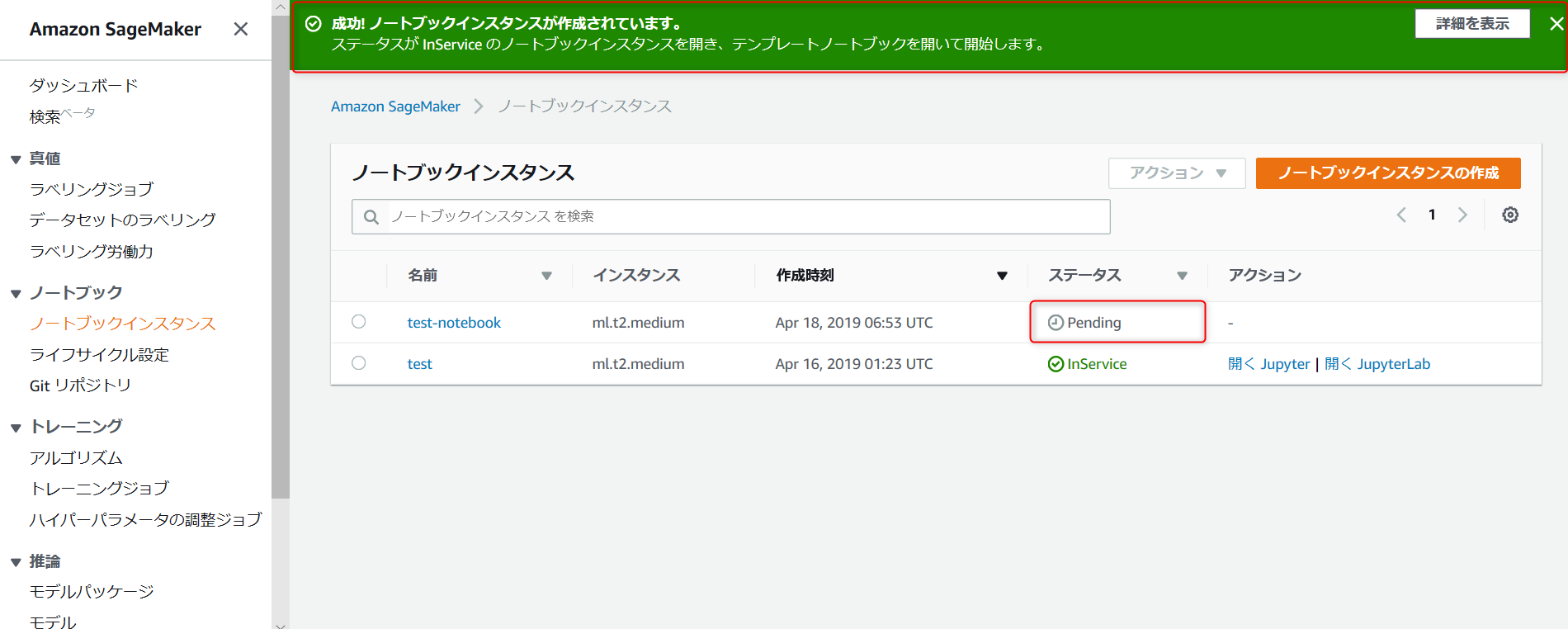
・ステータスが InService になったら、開く Jupyter を選択して Jupyter を開きます。
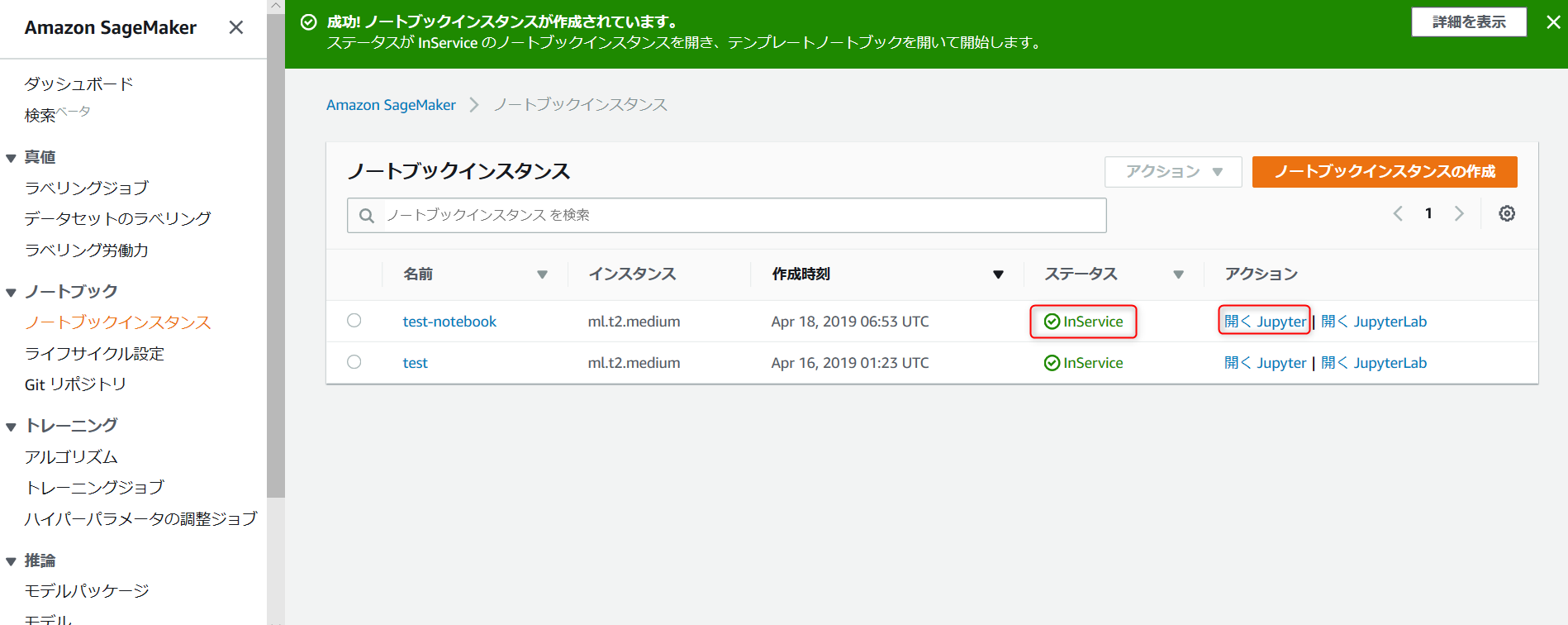
・Jupyter が開けたら、この後ダウンロードしたデータを保存するフォルダを作成します。
Newを選択。
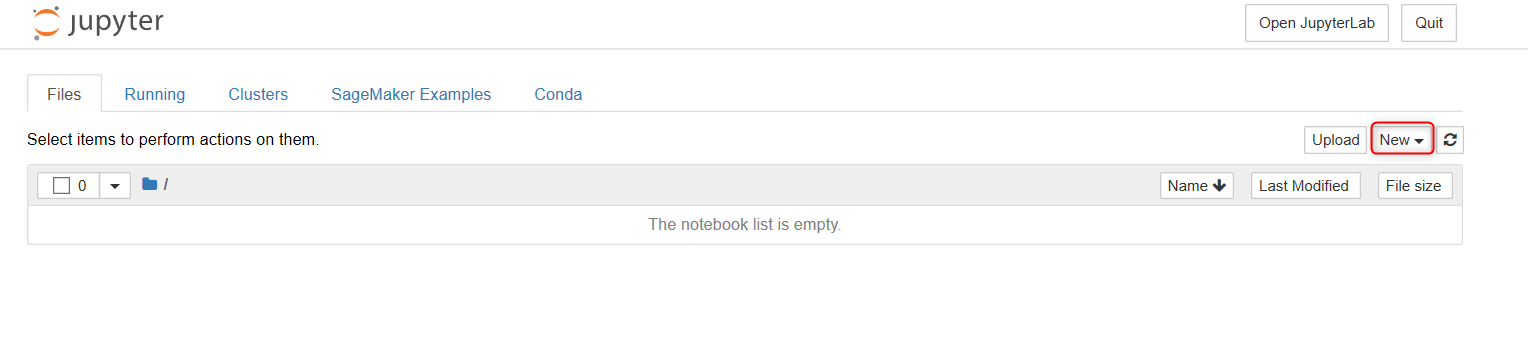
・Folder を選択。
・作成したフォルダを選んで、Rename を選択。
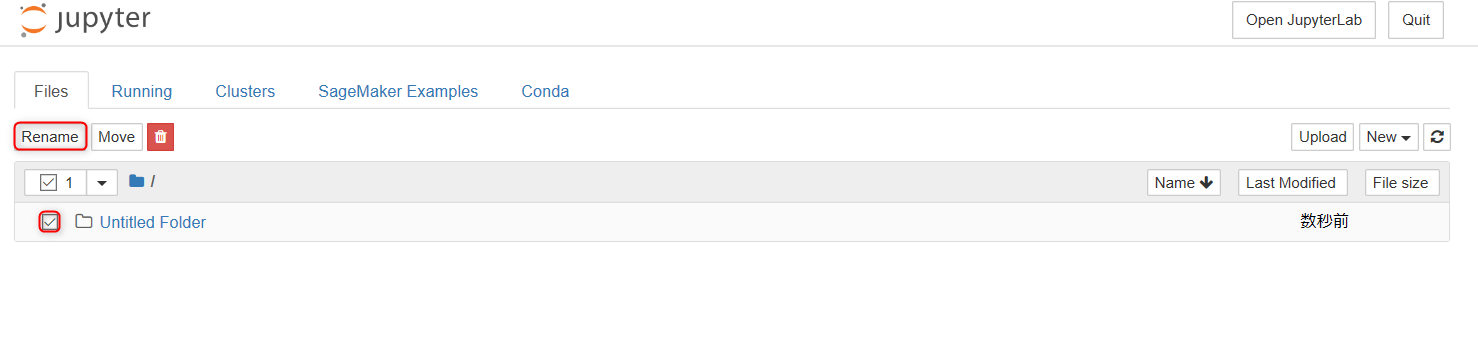
・名前は case1 として、Rename を選択。
・これでフォルダができました。case2 のフォルダも同様に作っておきます。

データの準備
データをダウンロードして Jupyter にアップロードします。
データのダウンロード
SIGNATEにアクセスする。
アクセスするとこのような画面が出るので、右上のConpetitionsを選択します。
・練習問題を選択。
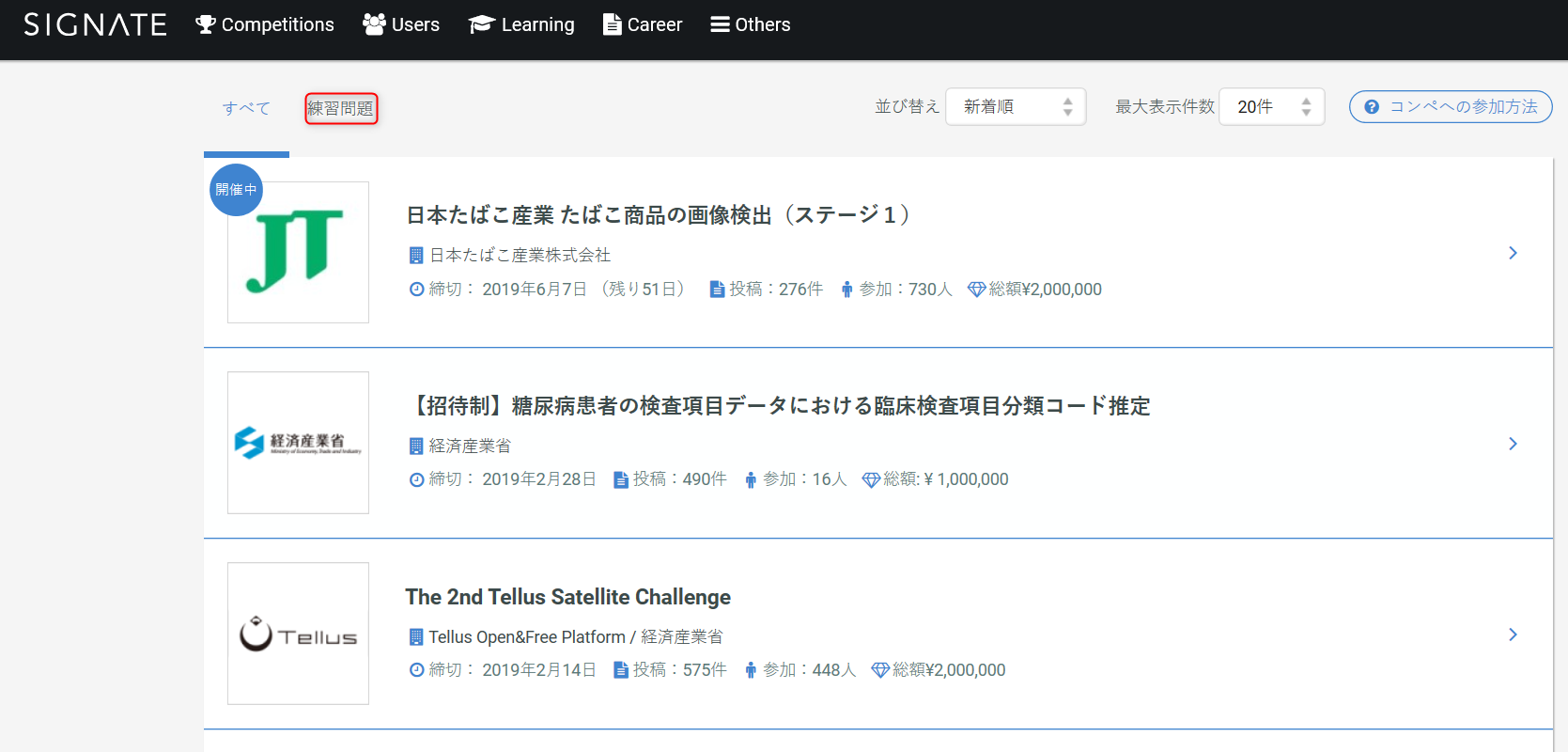
・一番下までスクロールするとお弁当の需要予測と銀行の顧客ターゲティングが出てくるので、それらのデータをダウンロードします。
まず、お弁当需要予測からデータをダウンロードするので、お弁当需要予測を選択。
・データを選択。
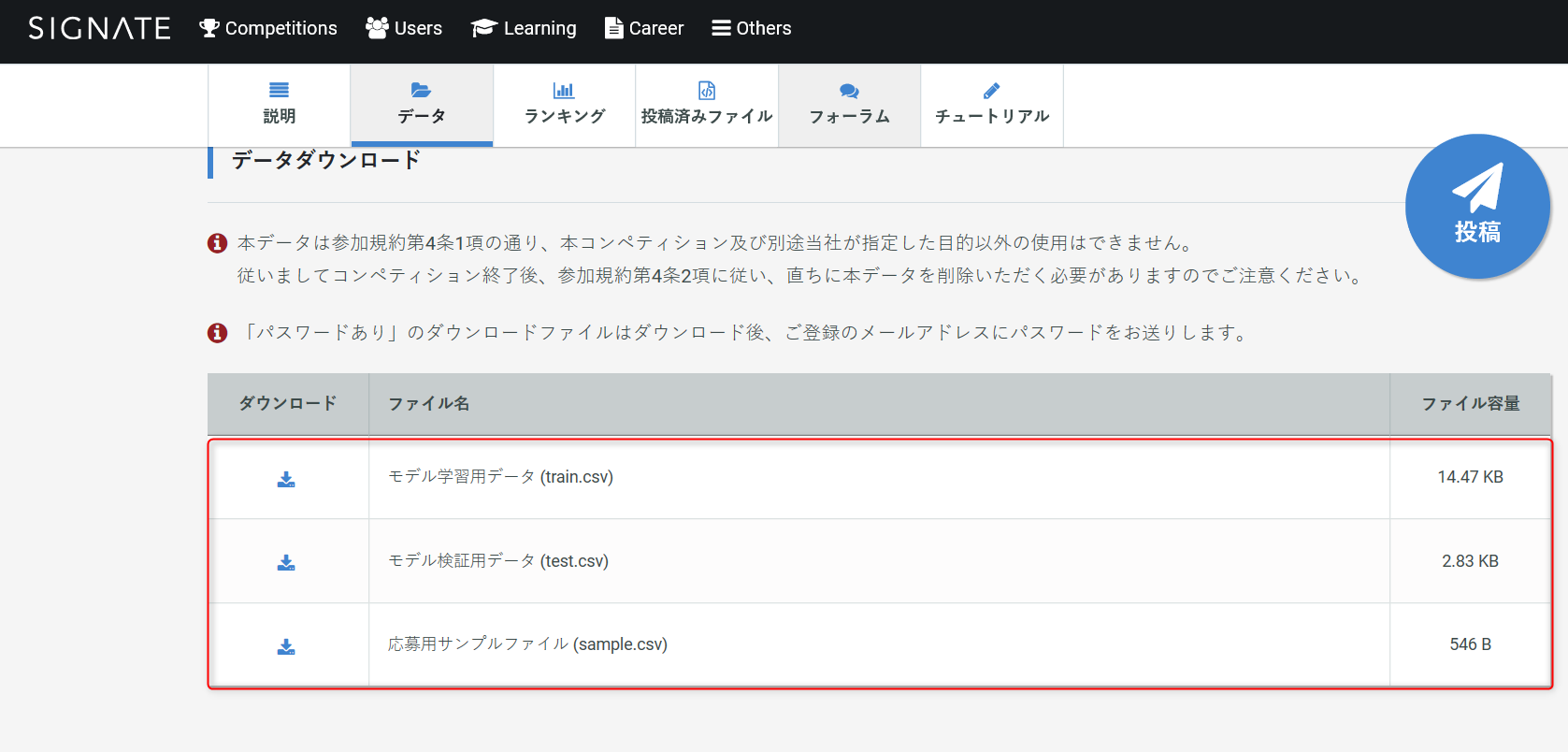
・下にスライドして、赤枠で囲んだ中の3つのファイルをダウンロードしてください。
・銀行の顧客ターゲティングについても同様にデータをダウンロードしてください。
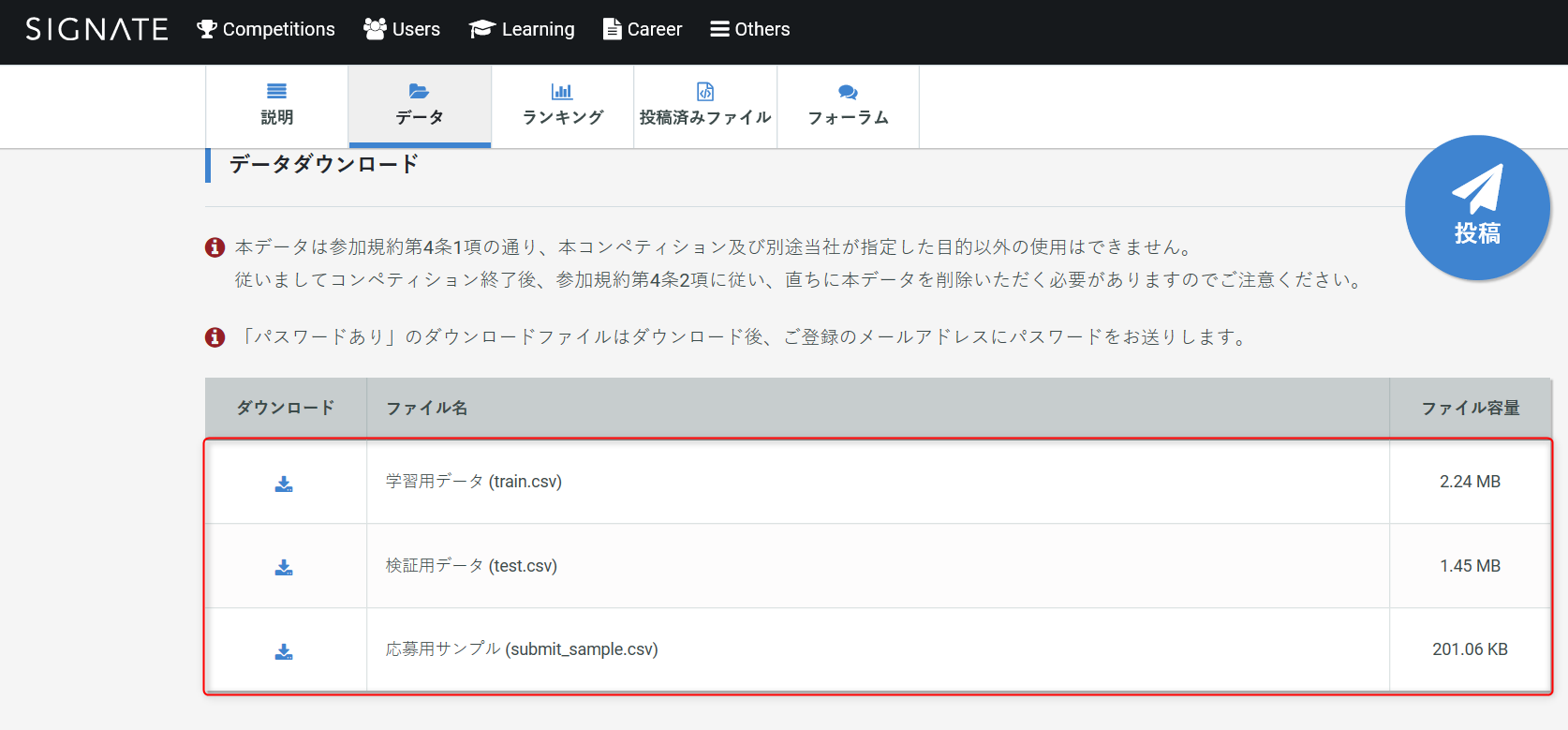
Jupyter にデータをアップロード
・先ほど Jupyter に作成した case1 フォルダにお弁当需要予測、case2 フォルダに銀行の顧客ターゲティングのデータをアップロードします。
case1フォルダを選択。

・Uploadからダウンロードしたデータをアップロードします。
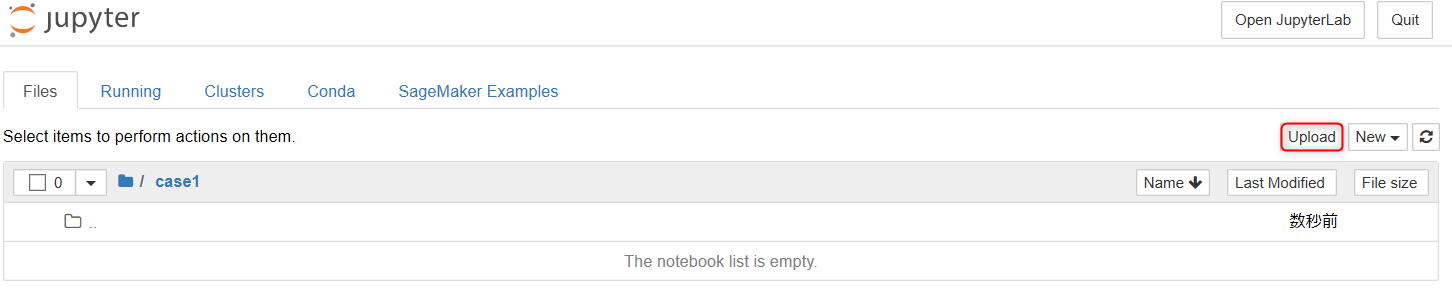
・ファイルを開くとこのようになるので、それぞれUploadを選択します。
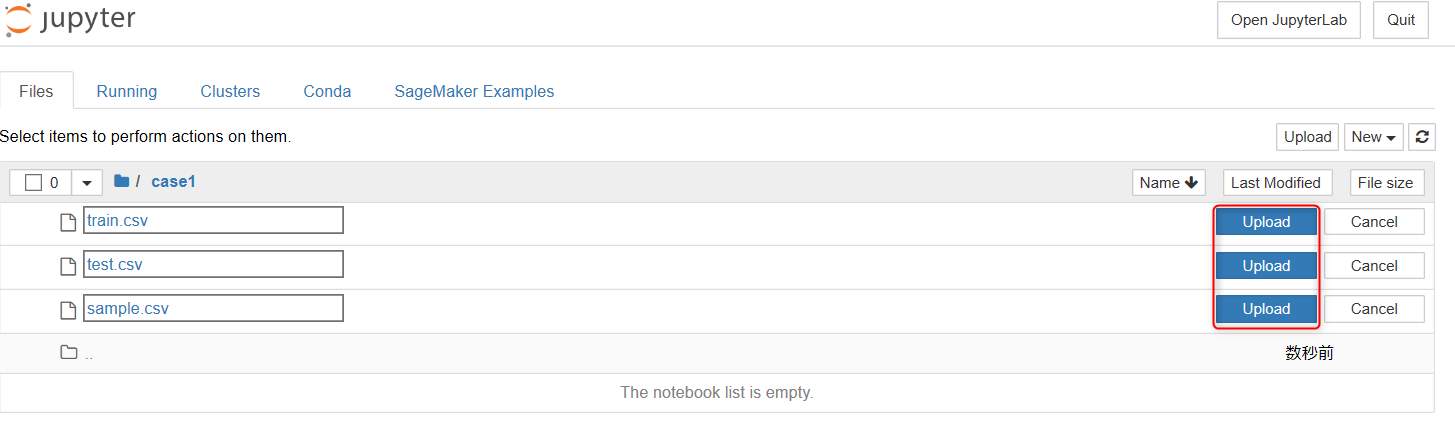
・これで、Jupyterにデータをアップロードできました。
case2のフォルダにも同様に銀行の顧客ターゲティングのデータをアップロードします。
Python コードの紹介
本コースで使用した主要な Python コードをまとめました。
この内容を実際に実行したい場合は、先ほど作成したcase1フォルダ内にnotebookをconda_python3で作成して実行してください。
モジュールのインポートと設定
・データ解析を支援する機能を提供するライブラリ。
|
1 |
import pandas as pd |
数値計算を効率的に行うためのライブラリ。
|
1 |
import numpy as np |
Python およびその科学計算用ライブラリNumPyのためのグラフ描画ライブラリ。
|
1 |
from matplotlib import pyplot as plt |
Jupyterのnotebook上で画像や図を表示するためのおまじない。
|
1 |
%matplotlib inline |
データ(csvファイル)の読み込み
train.csvを読み込んでtrainに格納する。
|
1 |
train = pd.read_csv("train.csv") |
データの表示
データの先頭を表示。
|
1 |
train.head() |
データの末尾を表示。
|
1 |
train.tail() |
データの行数と列数を表示。
|
1 |
train.shape |
基本統計量の表示。
|
1 |
train.describe() |
データの情報の確認。
|
1 |
train.info() |
1つのカラム(列)だけ表示。
trainのy列を表示。
|
1 |
train["y"] |
複数のカラムを表示。
trainのy、week、temperature列を表示。
|
1 |
train[["y","week","temperature"]] |
データの平均値を表示。
trainのy列の平均を表示。
|
1 |
train["y"].mean() |
データの中央値を表示。
trainのy列の中央値を表示。
|
1 |
train["y"].median() |
指定した範囲の表示。
trainのy列の値が150以上のデータを表示。
|
1 |
train[train["y"]>150] |
trainのweek列が月のデータを表示。
|
1 |
train[train["week"] == "月"] |
データを昇順、降順で表示。
trainをy列で昇順、降順で表示。
|
1 2 |
train.sort_values(by="y") #昇順 train.sort_values(by="y",ascending=False) #降順 |
データをグラフで表示
折れ線グラフを表示。
trainのy列を折れ線グラフで表示。
|
1 |
train["y"].plot() |
グラフの大きさを調節。
|
1 |
train["y"].plot(figsize=(12,4)) |
グラフにタイトルとx、y軸のラベルを追加。
一度タイトルを付けたグラフを変数に格納し、その後ラベルを追加する。
|
1 2 3 |
ax = train["y"].plot(title="test") ax.set_xlabel("time") ax.set_ylabel("y") |
ヒストグラムを表示。
trainのy列をヒストグラムで表示。
|
1 |
train["y"].plot.hist() |
ヒストグラムにグリッド線を追加。
|
1 |
train["y"].plot.hist(grid=True) |
ヒストグラムに平均値を表す赤の垂直線を表示。
線を表示した後で、グラフを表示する。
|
1 2 |
plt.axvline(x=train["y"].mean(),color="red") train["y"].plot.hist() |
ヒストグラムをpngファイルとして保存。
ヒストグラムをsample_fig.pngとして保存。
|
1 2 3 |
plt.axvline(x=train["y"].mean(),color="red") train["y"].plot.hist(figsize=(12,4),title="histogram") plt.savefig("sample_fig.png") |
箱ひげ図を表示。
yとweekを選択して、x軸にしたいカラムをboxplot(by=””)で指定する。
|
1 |
train[["y","week"]].boxplot(by="week") |
欠損値の処理
欠損値があるか確認。
欠損値の場合、Trueと表示される。
|
1 |
train.isnull() |
各カラム(列)に欠損値があるかどうか確認。
Trueなら欠損値があるということ。
|
1 |
train.isnull().any() |
各カラム(列)にいくつ欠損値があるか確認。
|
1 |
train.isnull().sum() |
欠損値を0で補間。
|
1 |
train.fillna(0) |
欠損値がある行を削除。
|
1 |
train.dropna() |
ある列に欠損値があった場合のみ、その行を削除するにはオプションのsubset=[]で列を指定できる。
kcal列に欠損値がある行を削除。
|
1 |
train.dropna(subset=["kcal"]) |
列の中の値がそれぞれいくつあるか表示。
soldout列の中の値がいくつあるか表示する。
|
1 |
train["soldout"].value_counts() |
相関関係を調べる
相関係数の表示。
trainのy列とtemperature列の相関関係数を表示する。
|
1 |
train[["y","temperature"]].corr() |
散布図で相関係数を調べる。
trainのy列とtemperature列の散布図を表示。 オプションとしてx=、y=でグラフに出力するデータを指定。 figsize=(,)でグラフのサイズを指定
|
1 |
train.plot.scatter(x="temperature",y="y",figsize=(5,5)) |
おわりに
本稿の内容は以上です。
その2では実践編として、線形回帰を用いたお弁当の売り上げ予測についてまとめていきますので、よろしくお願いします。
SageMakerの導入ならナレコムにおまかせください。
日本のAPNコンサルティングパートナーとしては国内初である、Machine Learning コンピテンシー認定のナレコムが導入から活用方法までサポートします。お気軽にご相談ください。
