はじめに
今回は、先日公開がされたこちらの記事https://qiita.com/KC_NN/items/d265eddcbdc8a47ed88c
をML初心者の私が見ながらでもできるものなのかを試してみた記事になります。その為新技術などの情報はないですが、そこはご容赦ください。
今回の背景
今日(投稿日)がクリスマス・イブということで、せっかくだからクリスマスにちなんだ記事にしようと思いました。そこで、クリスマスのお菓子で定番のあのお菓子を画像分類してみようと思いました。

そう!あの「ジンジャーマンクッキー」です!
ラベル付けの際にジンジャーマンクッキーに名前を付けて名前による分類ができるんじゃないか。この企画ならいける!と思い、早速ジンジャーマンクッキーを購入しようと思いました。が、みんな見た目一緒じゃないか…
↓私の中のイメージ
↓現実

これじゃあ分類ができない!いっそ自分で作るかとも少しだけ思いましたが料理を普段しない私にはできるはずもなく…
そこで、形が違って、クッキーっぽいものはないかと探したところ。このお菓子にたどり着きました!

これなら要望を満たせる!ということで、たべっ子どうぶつビスケットの画像分類をML初心者の私が、先日公開された記事を見ながらAWSのRekognition Custom Labelsで挑戦してみました。
いざ実践!
まず、記事の手順通りに素材を集めるところからということで素材写真をiphoneで撮影しました。今回は、全体画像の角度を変えたものを7枚ほど撮影しました。



こんな感じで7枚ほど撮影
記事の手順通りに、「プロジェクト名作成、S3バケット作成、画像をS3に保存」を実施していきます。
次に、保存した画像にラベリングをしていきます。
ラベリングは、自分で入力をしていくのですが、この数は結構めんどいなーと思ったので、OCR(Amazon Rekognition text in image)を使って画像内のテキストを抽出し、こんな感じに2画面にし、抽出したテキストをコピペして作業を簡略化してみました。(下記画像の左がCustom labels、右がtext in imageの画面です。)
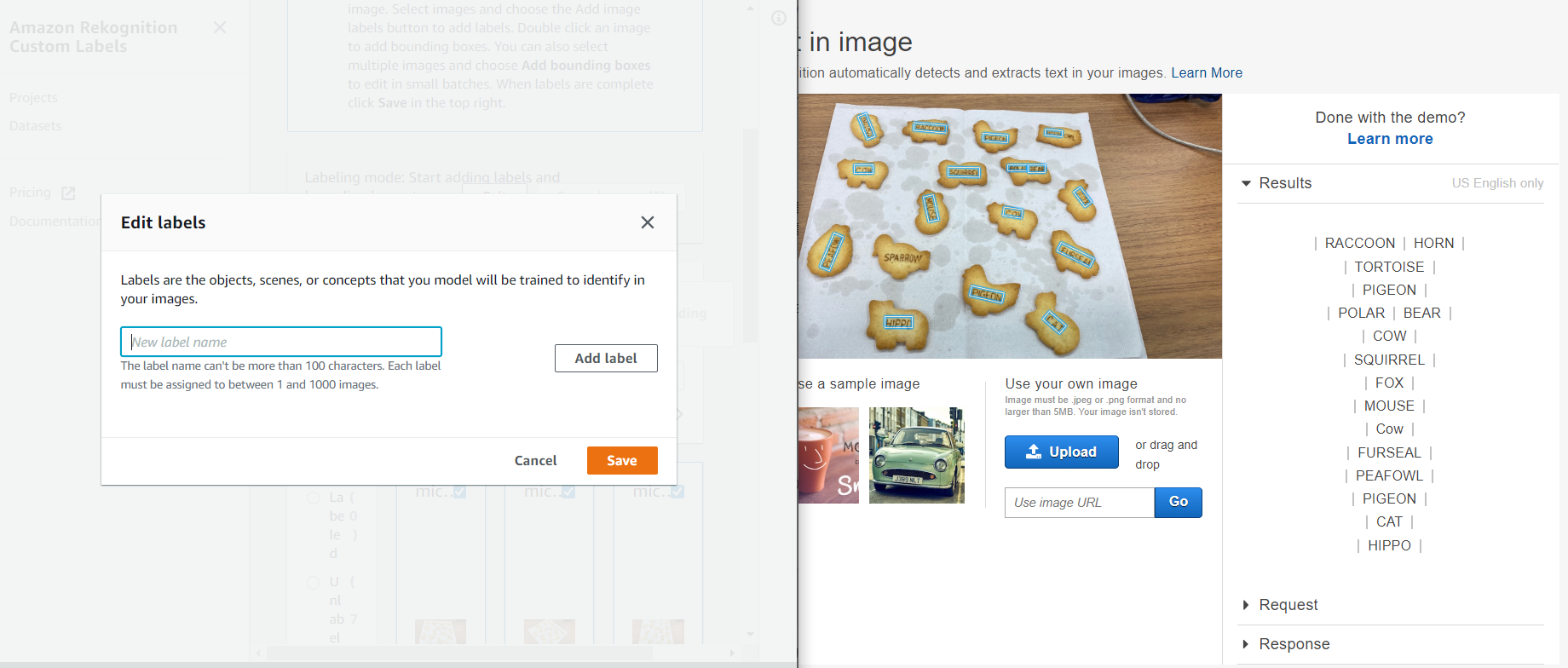
ラベリング名の登録も済んだので、実際に写真にラベル付けをしていきたいと思います。
ラベル付けも記事の手順通りに、ラベル付けしたい画像を選んで、画像内のオブジェクトに対してラベル名のついたドローイングボックスをただひたすらにこんな感じで囲っていきます。

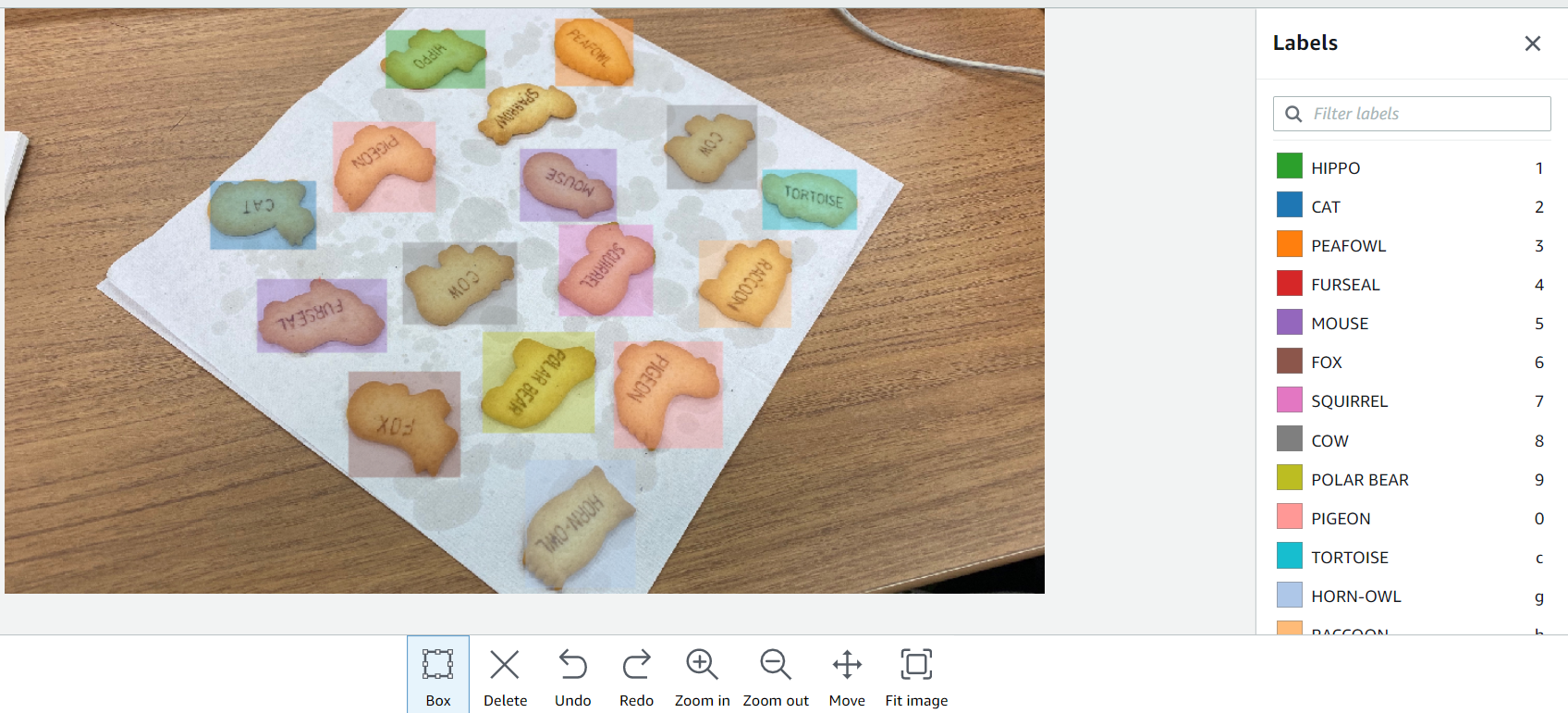
こうして撮影した全部で7枚の写真にラベルを付けていきます。
ここまでだいたい30分前後で作業は終わりました。(画像のアップロードから数えて)
作業が終わるとダッシュボードがカラフルになります。
記事では、ラベル付けをした後に、「save change」を選択後「Train model」を選択するとありましたが、
実際は、「save change」を選択した後に隣の「Exit」を選択しないと「Train model」のボタンがに切り替わらないので、ご注意を。
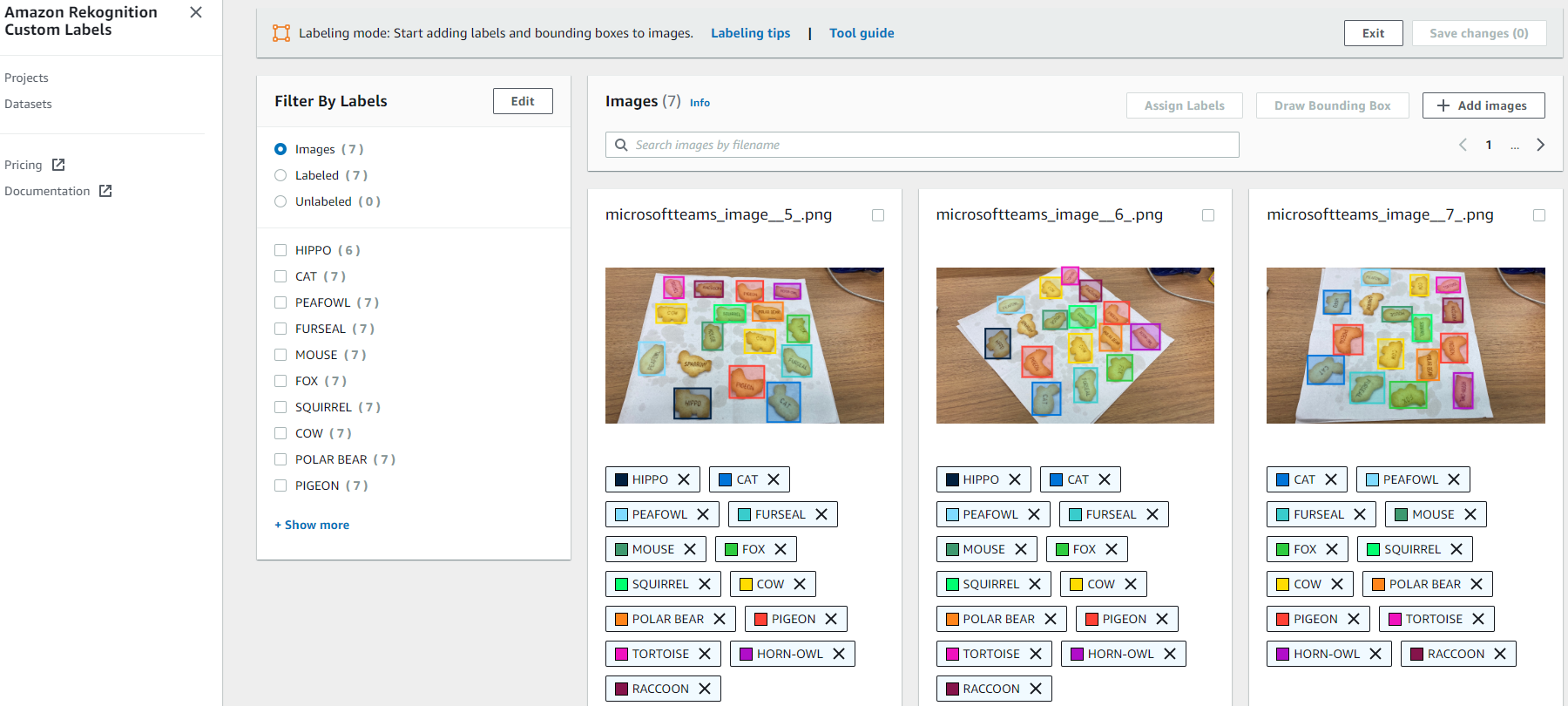
ここまで簡単に画像認識のモデルを作れるとは思いませんでした。技術的にあまり詳しくない私でもこんなに簡単にできるとは、AWSはすごいですね!
あとは、推論するだけ。ってここにきてまさかのCLI!
CLIでモデルを使って推論した結果こんな感じになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
"CustomLabels": [ { "Name": "HORN-OWL", "Confidence": 100.0, "Geometry": { "BoundingBox": { "Width": 0.8662499785423279, "Height": 0.2805599868297577, "Left": 0.05463000014424324, "Top": 0.31387001276016235 } } } ] |

HORN-OWLを判定しているみたいですが、今回用意したデータセットが少ないせいか信頼スコア(Confidence)がかなり高いように見えます。もう少しデータセットを増やすべきでしたね…
結果を視覚的に見せるのには、結果コードと画像を使ってプログラムを書く必要があるとのことなので、ここだけは社内のメンバーに手伝ってもらいました。
まとめ
トータル的に見て、ほとんど技術を知らない人でも簡単に画像認識の予測モデルができて推論までできてしまうすごいサービスがリリースされたなーと感じずにはいられません。
こんなに簡単にライトにできるのであれば、もっといろんな画像分析を試してみたいと思いました。
最後まで、読んでいただきありがとうございました!メリークリスマス!
