Amazon SageMaker Studioの導入とAutopilotについて#1の続きです。
前回は、SageMaker Studioの導入とAutopilotによるパイプラインを開始したところまで終わりました。
Amazon SageMaker Autopilot –高品質な機械学習モデルをフルコントロールかつ視覚的に自動生成
Amazon SageMaker Studio-Amazon SageMaker AutoPilot(パート2)
part2は、Future Engineeringについての話です。
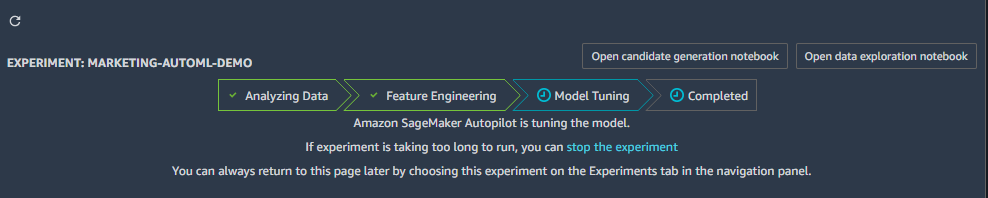
「Open data exploration notebook」には、データセットに関する情報が書かれています。
1.どのように特徴量を選択するために分析されたのか
2.データセットからAutoMLパイプラインの修正と改善について
トレーニングデータセットから39128行を読み取ります。データセットには21個の列があり、yという名前の列がターゲット列として使用されます。これはBinaryClassificationの問題として識別されます。ラベルの2つの例を次に示します:[‘no’、 ‘yes’]。
21項目からなる39128個のトレーニングサンプルがあり、「y」が推論対象。これはyesかnoを推論する二項分類の問題です。
データセットのサンプル
次の表は、トレーニングデータセットの10行のランダムサンプルです。表示を簡単にするために、データセットの21列のうち20列のみを表示しています。
10個のサンプルを表示しています。21項目中20項目のみ表示しています。
カラム分析
AutoMLジョブは21の入力列を分析して、各データタイプを推測し、各トレーニングアルゴリズムの機能処理パイプラインを選択しました。
AutoMLジョブが21項目を分析します。
欠損値の割合
21列のうち1列に欠損値が含まれていることがわかりました。次の表は、欠損値の割合が最も高い1列を示しています。
1項目について欠損値を見つけたようです
。poutcomeが86.33%欠損しているそう。
カウント統計
データがカテゴリカルならone-hot encodingを実施したり、テキストならtf-idfなどを実行するようです。
次の表は、一意のエントリの数でランク付けされた21列のうち21列を示しています。
各項目の独立した値の数を一覧表にしてくれています。
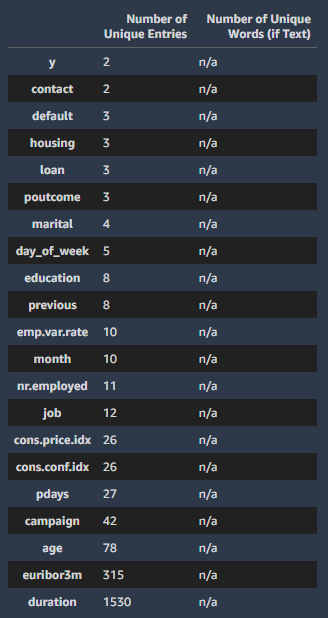
記述統計
数値データの場合は、正規化、log、quantile、binningなどにより外れ値やスケールを調整してくれます。
Amazon SageMaker Studio-Amazon SageMaker AutoPilot(パート3)
part3は、Model Tuningの話です。
「Open候補世代ノートブック」には、SageMaker Autopilotジョブの詳細情報(各試行の情報、データ前処理ステップなど)が書かれています。すべてのコードは利用可能な状態で、実験を重ねる際のとっかかりになるらしい。
データセットには21個の列があり、yという名前の列がターゲット列として使用されます。これはBinaryClassificationの問題として扱われています。データセットには2つのクラスもあります。このノートブックは、トレーニングされたモデルの「精度」品質メトリックを最大化するBinaryClassificationモデルを構築します。「ACCURACY」メトリックは、モデルが正しいクラスを予測した回数の割合を提供します。
ACCURACY(正確度)が最大になるように二項分類のモデル作ったそうです。
セージメーカーのセットアップ
SageMakerのセットアップ
- Jupyter:JupyterLab 1.0.6、jupyter_core 4.5.0およびIPython 6.4.0でテスト済み
- カーネル:conda_python3
- 必要な依存関係sagemaker-python-sdk> = v1.43.4
生成された候補のダウンロード
データ変換とAutopilotに関するモジュールをダウンロードします。
SageMaker自動操縦ジョブとAmazon Simple Storage Service(Amazon S3)の構成
Autopilot JobとS3の設定を行います。
候補パイプライン
生成された候補
SageMaker Autopilot Jobはデータセットを分析し、2つのアルゴリズムを使用する10の機械学習パイプラインを生成しました。各パイプラインには、一連の機能トランスフォーマーとアルゴリズムが含まれています。
2つのアルゴリズムを用いた10個のパイプラインを生成し、分析したそうです。
dpp0-xgboost:このデータ変換戦略は、まずRobustImputerを使用して「数値」機能を変換し(欠損値をnanに変換)、ThresholdOneHotEncoderを使用して「カテゴリ」機能を変換します。生成されたすべての機能をマージし、RobustStandardScalerを適用します。変換されたデータは、xgboostモデルの調整に使用されます。定義は次のとおりです。
10個がそれぞれどのようなパイプラインかの説明が書いてあります。上記は、内1つの例です。
選択された候補者
SageMakerのtraining jobとバッチ変換を含む特徴エンジニアリングを行います。
候補パイプラインの実行
データ変換ステップを実行する
データ変換を実施します。
マルチアルゴリズムハイパーパラメーターチューニング
データ変換されたら、Multi-Algo Tuning jobにより最適な推論モデルを探します。
モデルの選択と展開
ジョブ結果の調整の概要
Pandas dataframeを用いて各パイプラインの可視化を行います。
モデル展開
最後にデプロイします。
Amazon SageMaker Studio-Amazon SageMaker AutoPilot(パート4)
part4は、モデルの比較やデプロイまでの話です。
Autopilotが完了すると、さまざまなモデルができています。Trialsタブ
を見ると、トレーニングジョブと精度の一覧が見れます。
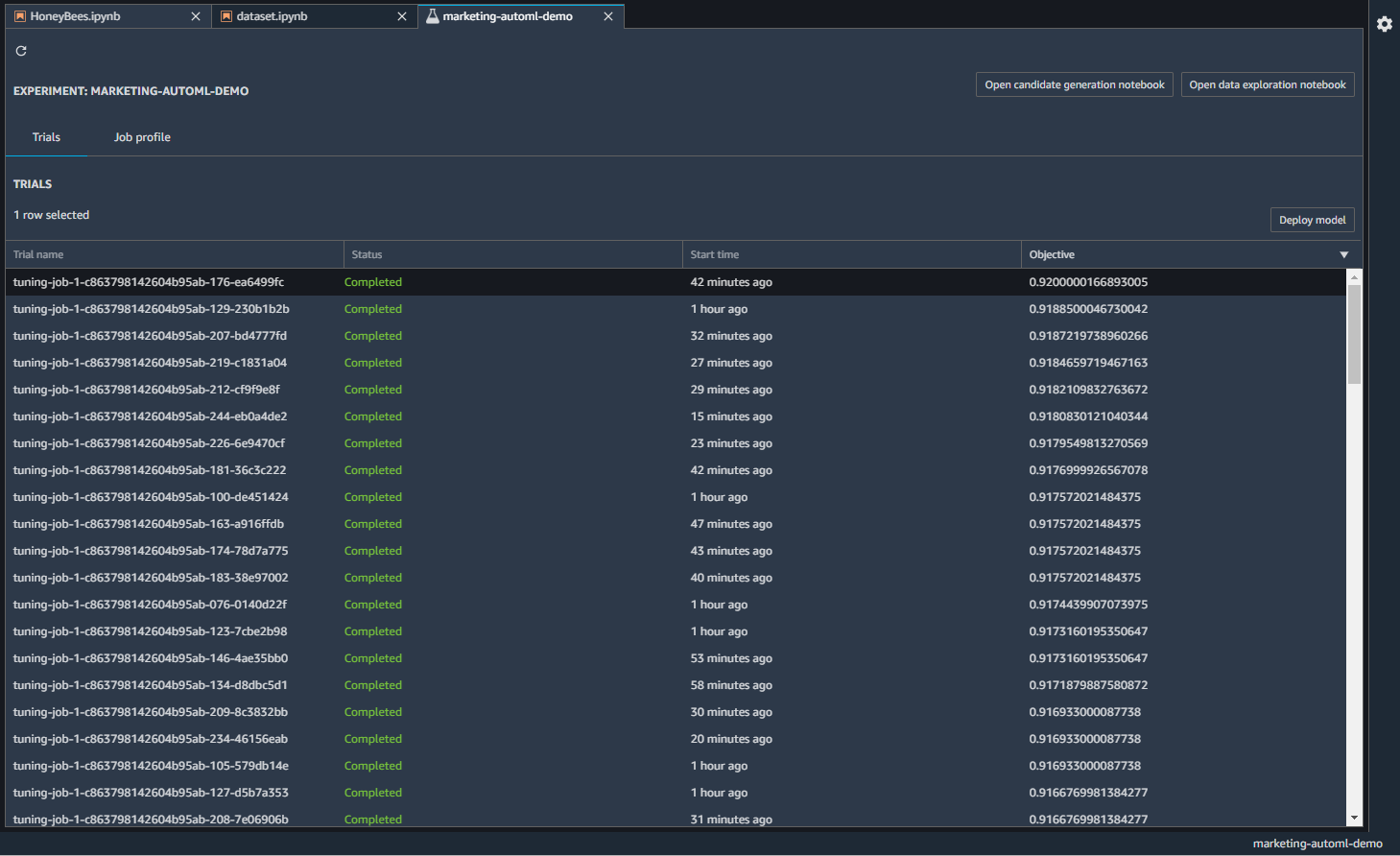
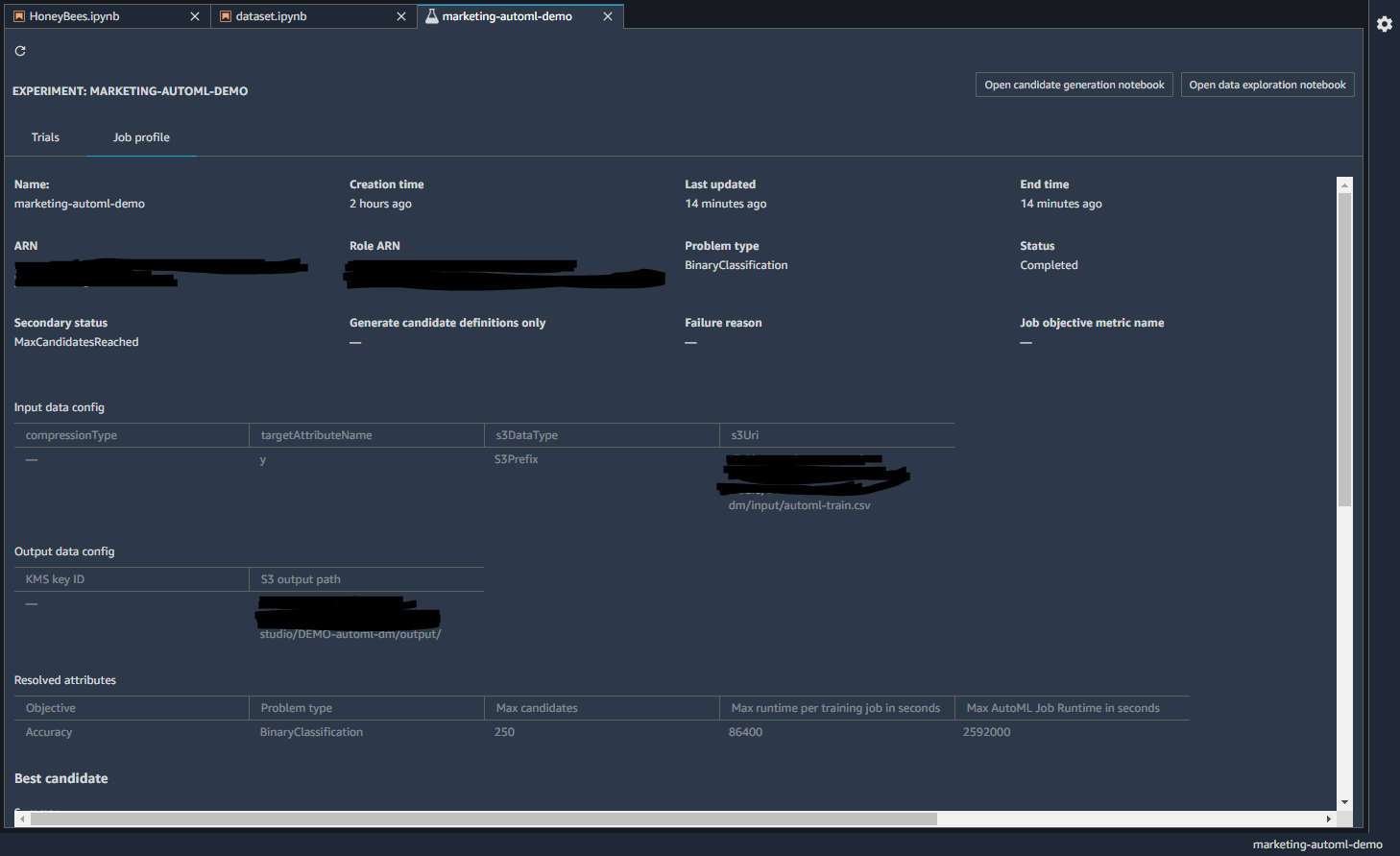
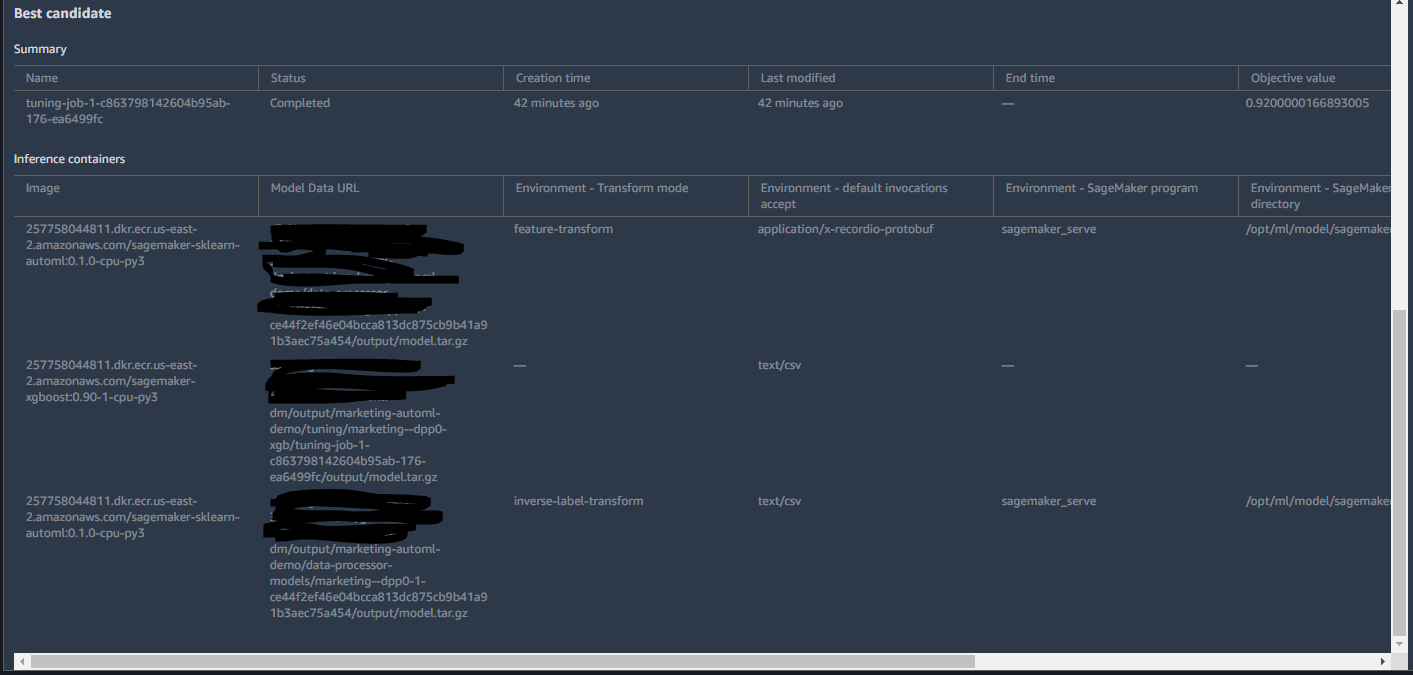
Job Profileでは、学習時間や設定の情報、ベストなモデルの候補が挙げられています。
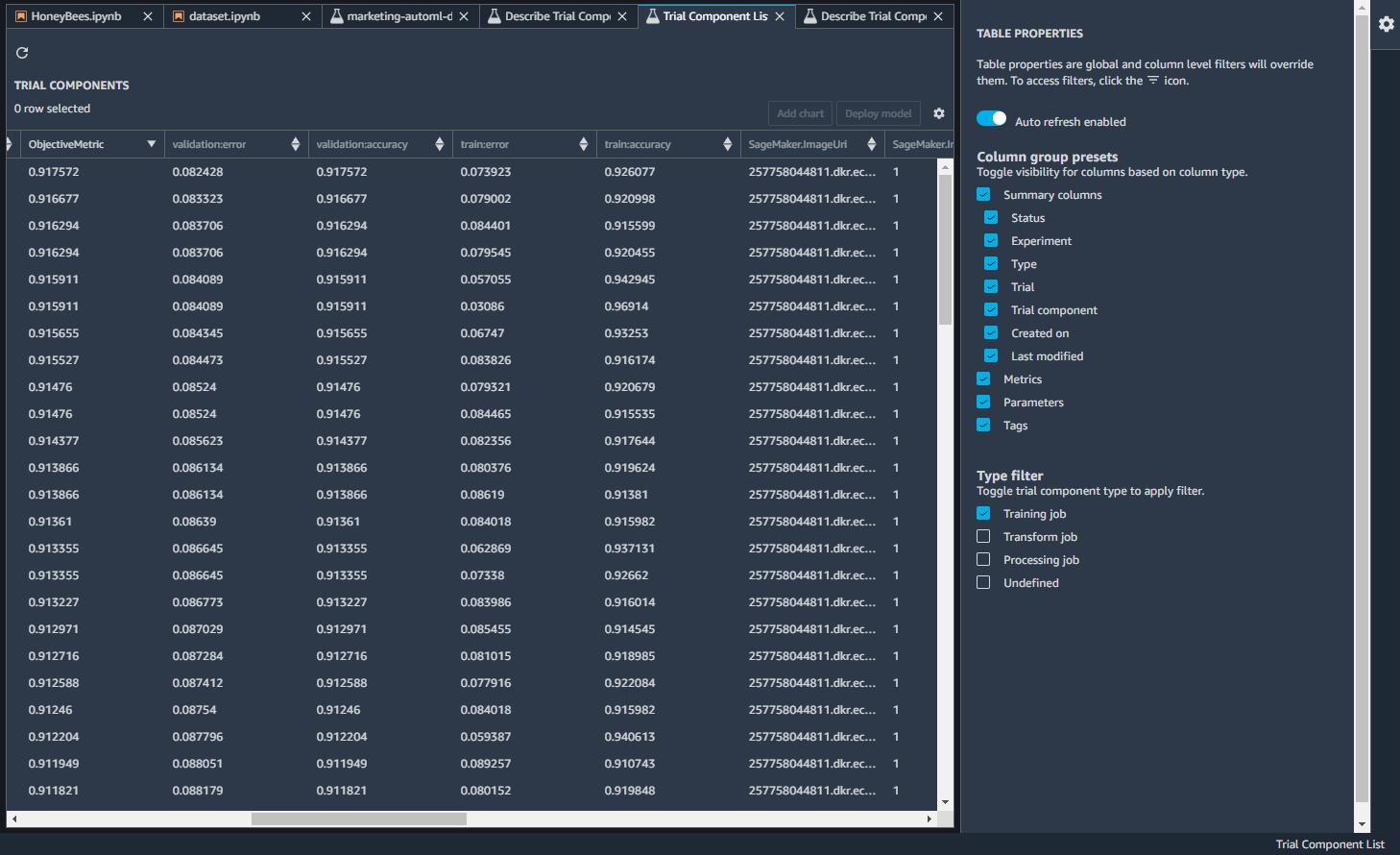
トレーニングジョブを右クリックして、トライアルコンポーネントリストをクリックすると、詳細のリストが見れます。
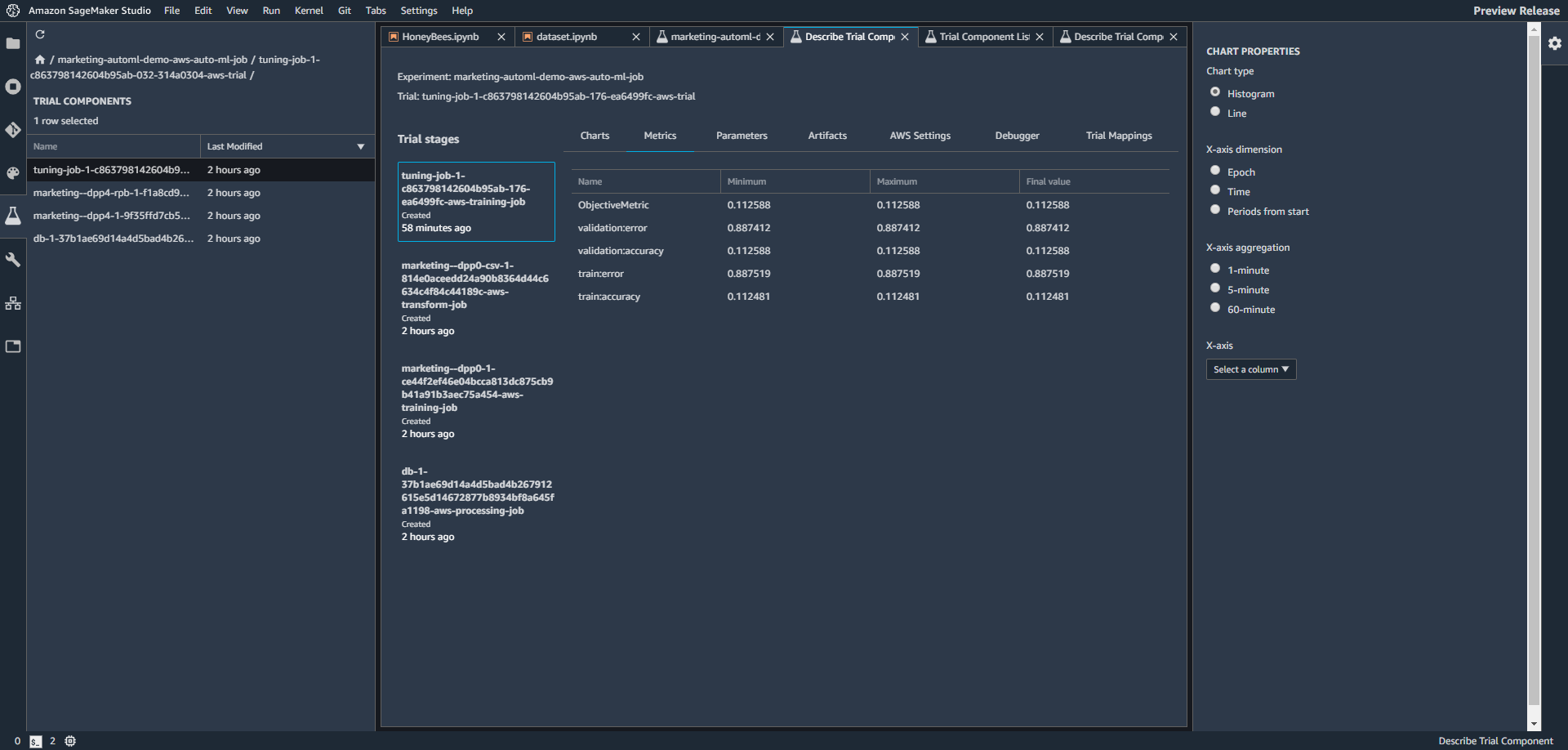
トレーニングジョブを右クリックして、試用版で開く詳細をクリックすると、ジョブの詳細が見れます。
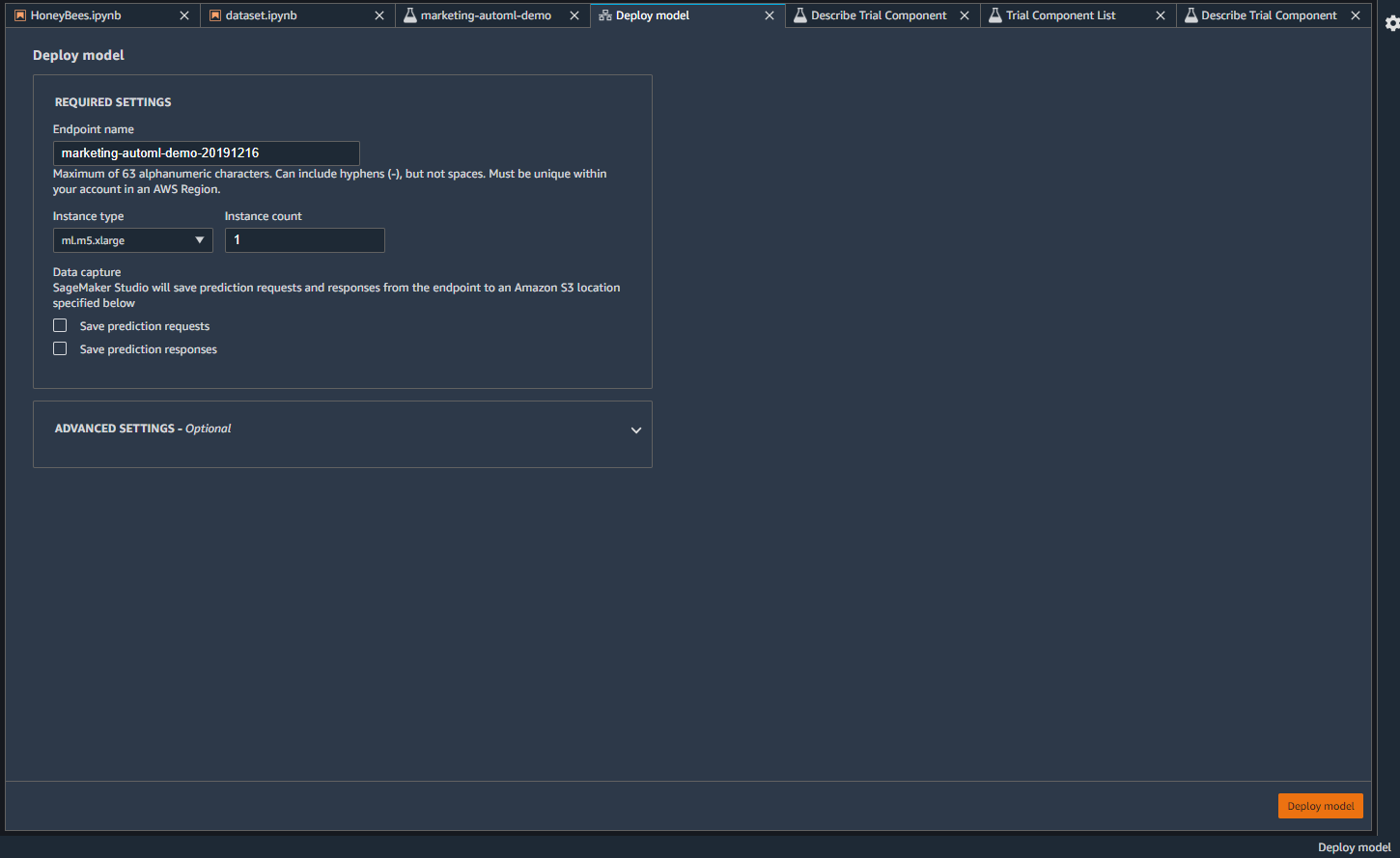
デプロイモデルをクリックすると、エンドポイントが作成されます。
監視を有効にするをクリックすると、
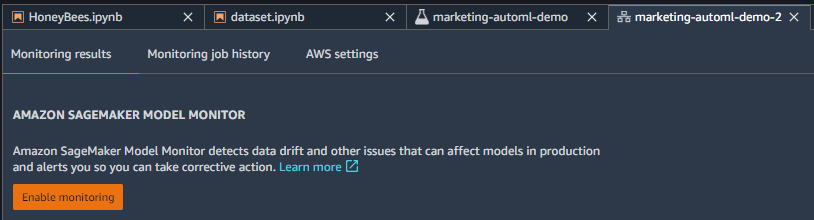
ノートブックを利用して、モデルの監視ができるみたいです。
Amazon SageMaker Experiments –機械学習モデルの整理、追跡、比較、評価
Amazon SageMaker Model Monitor –機械学習モデルのためのフルマネージドな自動監視
まとめ
ざっくりとした説明になってしまいましたが、SageMaker Autopilotの続きをやってみました。SageMaker Autopilotにより、モデルを自動で最適でやつを作ってくれます。さらに、どのようなプロセスでモデルを作ったあるのかや、モデルの比較や監視までできるようです。
その他
SageMakerの導入ならナレコムにおまかせください。
日本のAPNコンサルティングパートナーとしては国内初である、Machine Learning コンピテンシー認定のナレコムが導入から活用方法までサポートします。お気軽にご相談ください。
