はじめに
Amazon Comprehendという機械学習のサービスの一つをご紹介致します!
プログラミングもいらず、機械学習の前提知識もいらない、直感的に自然言語処理ができます。
私JJも気軽に挑戦できますね!
Amazon Comprehendで何ができるの?
Entities(固有名詞抽出)
属性。データテーブルのようなものですね。
日付やイベント、特定の場所、企業や人、量やタイトル及びその他を抽出できます。
| タイプ | 説明 |
|---|---|
| 日付 | 曜日、月、時間 |
| 場所 | 国、都市、湖、建物 |
| 組織 | 政府、企業、宗教、チーム |
| 人 | 個人、グループ、人物 |
| 量 | 通貨、パーセンテージ、数値、バイトなどの定量化された量 |
| タイトル | 映画、書籍、歌、作品に付けられた公式名 |
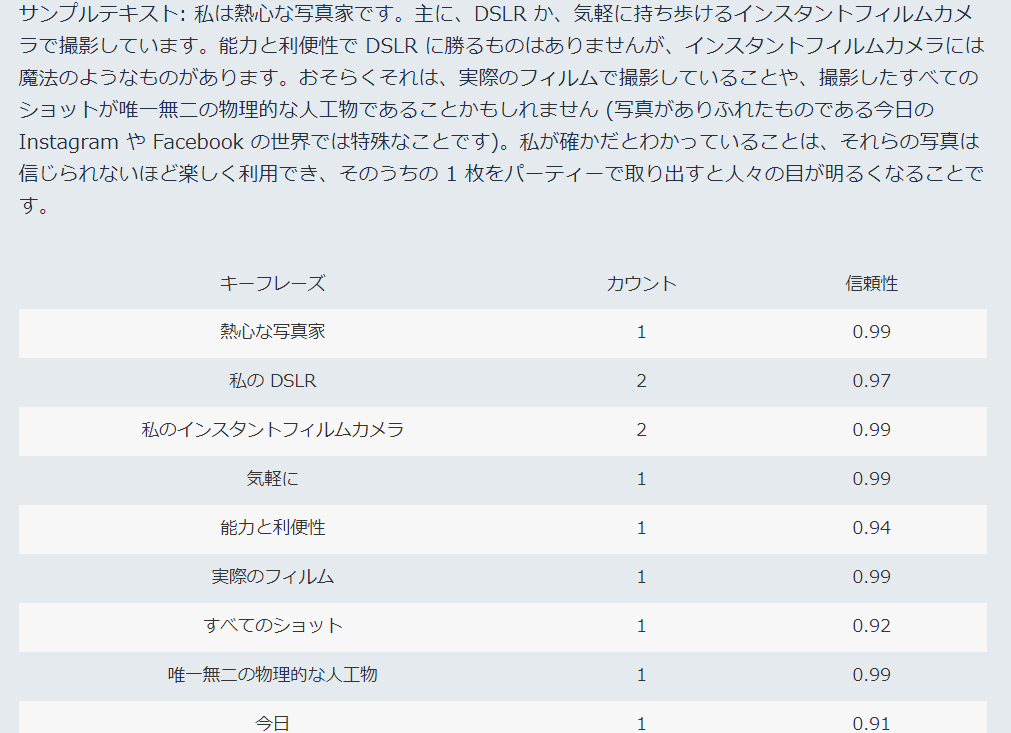
Key phrases(キーワード抽出)
重要なフレーズとなる特徴的な名詞を抽出できます。会話のポイントだったり特徴的なキーフレーズであることを裏付ける信頼性スコア(フレーズの検出がアプリケーションにとって十分に高い信頼性を持っているかどうか)を出してくれます。以下Amazonの資料から。
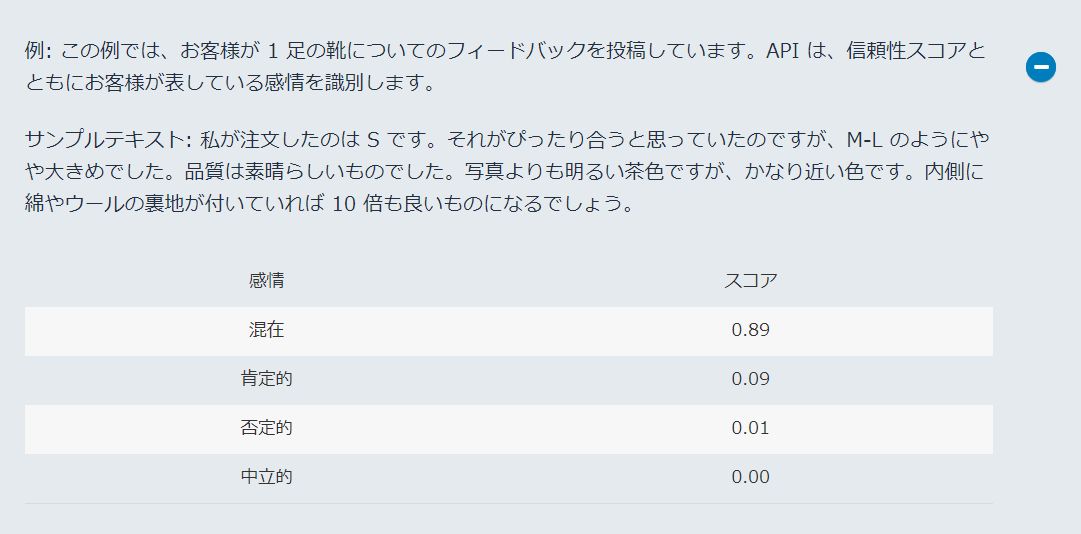
Sentiment(感情分析)
4種類で表した感情の分析ができます。肯定的、否定的、中立的(感情の振れ幅が一定)、または混在。
たとえば、センチメント分析を使用して、ブログ投稿に対するコメントのセンチメントを判断し、
読者が投稿を気に入ったかどうかを判断できます。
実際に触ってみました
小説「そして、バトンは渡された/瀬尾まいこ」さんのAmazonのレビューを分析してみました。
Amazon Comprehendのページに行ったらReal-time analysisを左メニューから選択。
Input textにテキストを貼り付けてAnalyzeのボタンを押すだけ。(本当に何も難しいことがない、、、!)
Entities
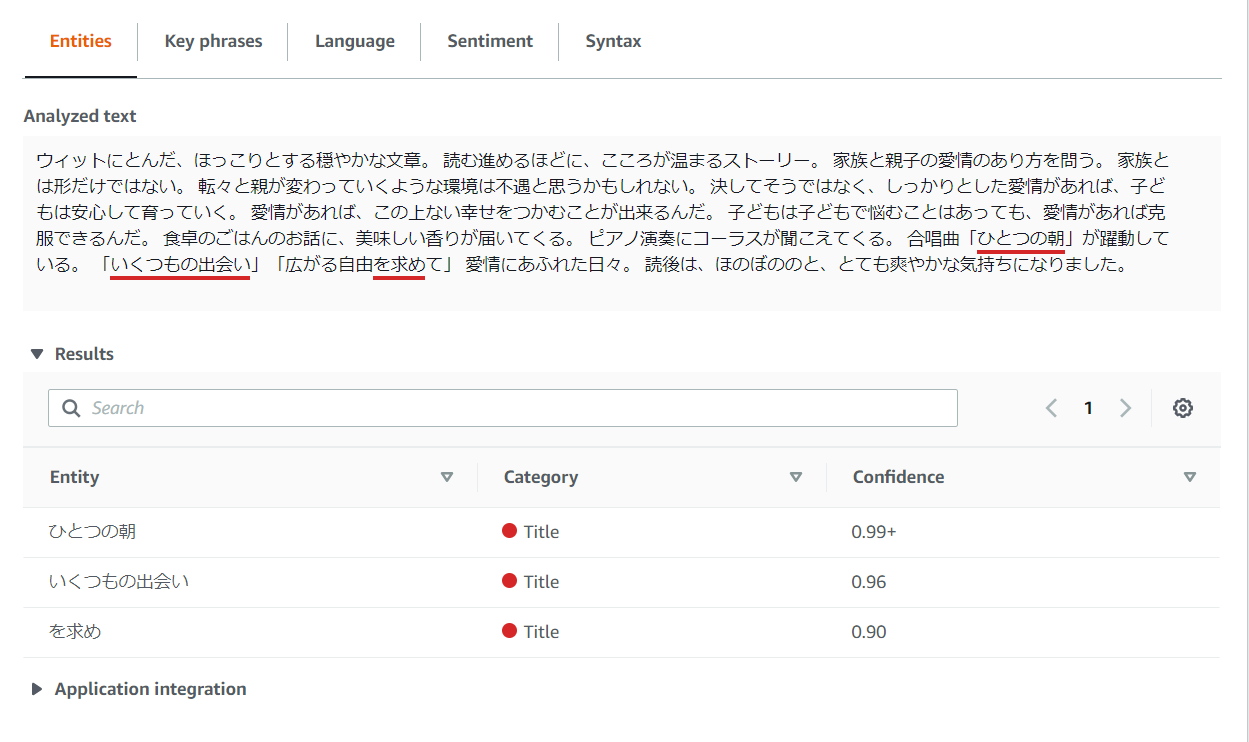
赤線が引かれ、数値というよりはタイトルになりそうな言葉が抽出されています。
Key phrases
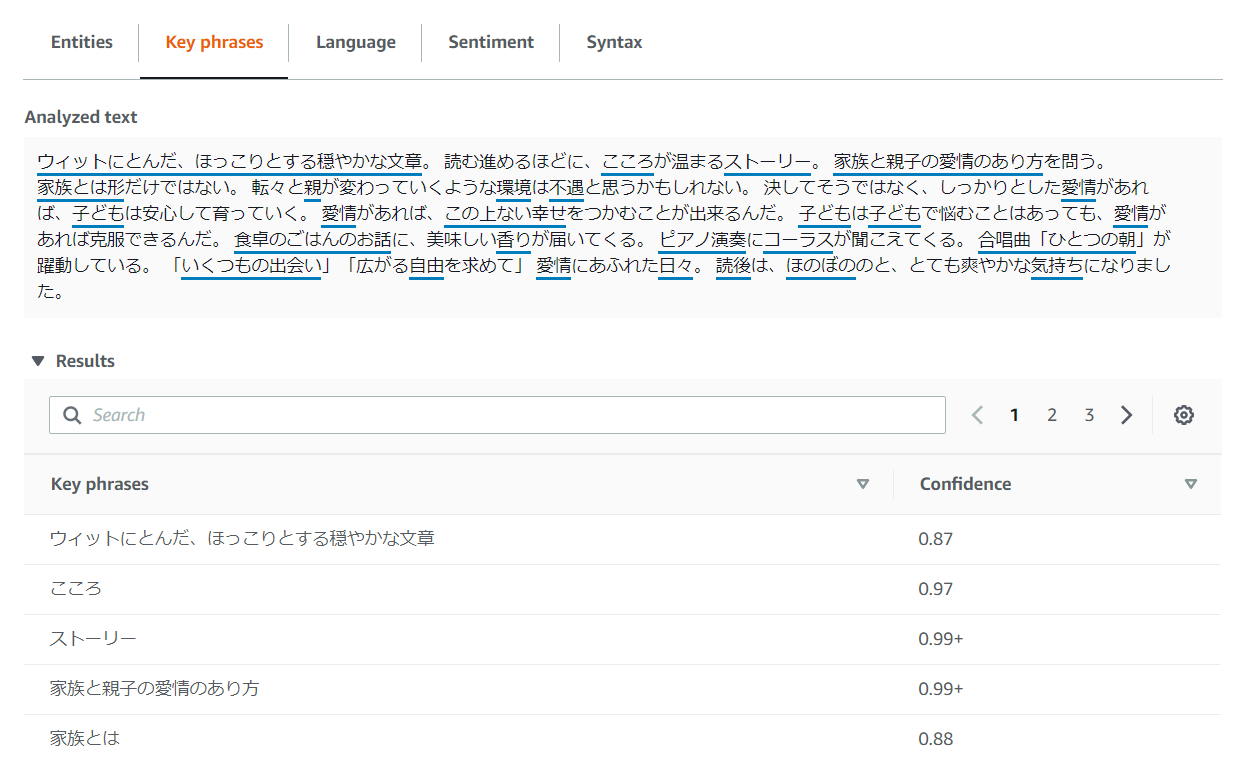
こちらでは青線が引かれ、感情や叙情的フレーズ、特徴的な動詞が抽出されています。
エンティティよりキーフレーズの方が抽出量も多いです。
Sentiment
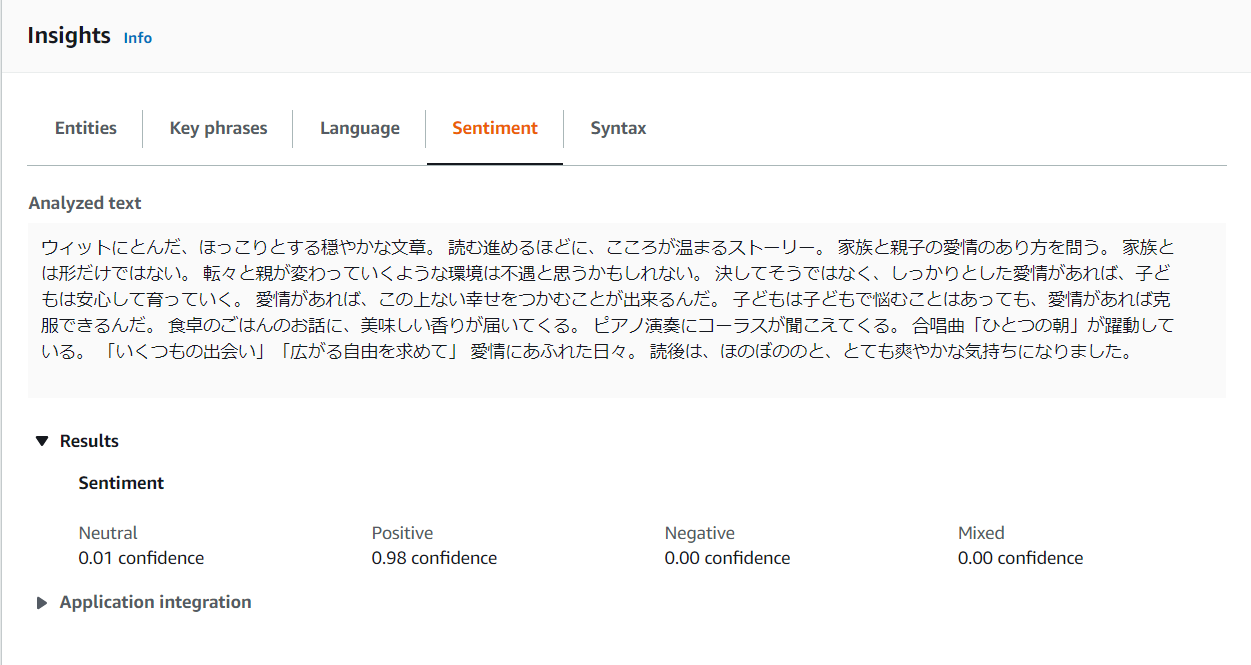
個人的に一番気になっていたセンチメントも98%肯定的でポジティブなレビューであるという分析結果!
マイナスな文章はどうなる?
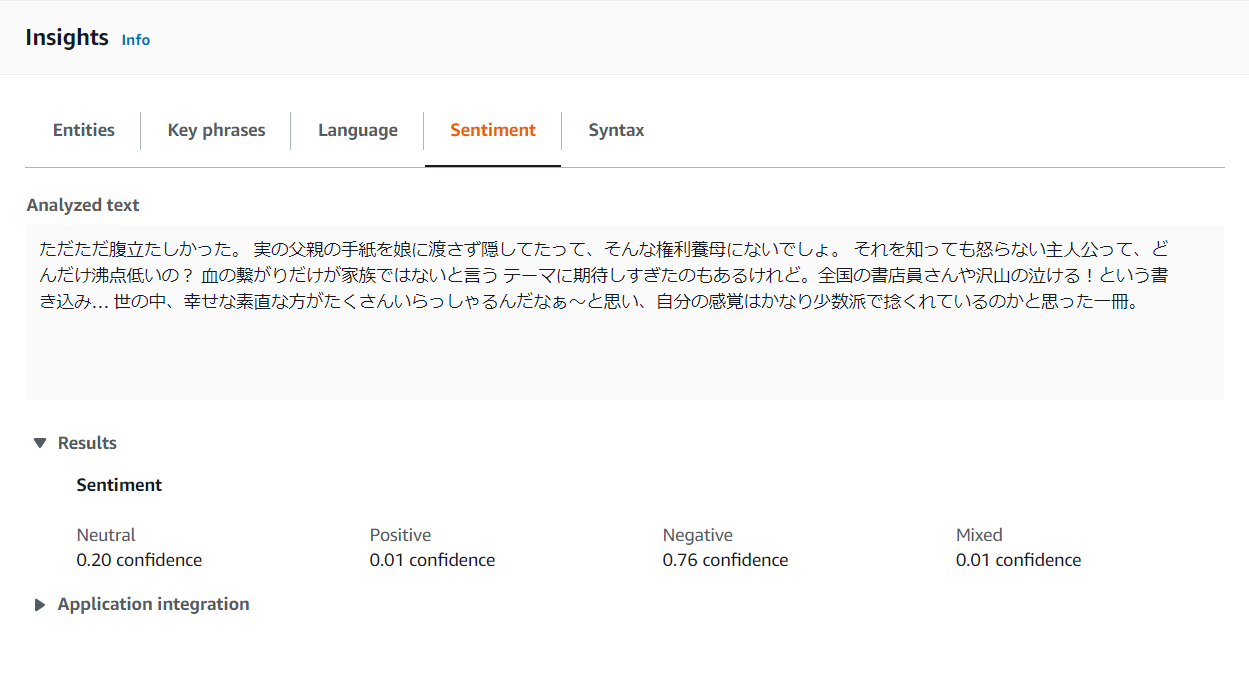
しっかり辛口なレビューであることがわかりますね。「幸せな」あたりから微量なポジティブを抽出しているのでしょうか。
「期待しすぎた」「捻くれている」
こんな細かな混在した気持ちも分析してくれています。想像以上です。
企業公式アカウントのTwitterでSHARP株式会社「シャープさん(@SHARP_JP)」が「炊飯器発売のお知らせ」で呟いた友永構文のシュールなツイートも分析してもらいました。(個人的な興味で)
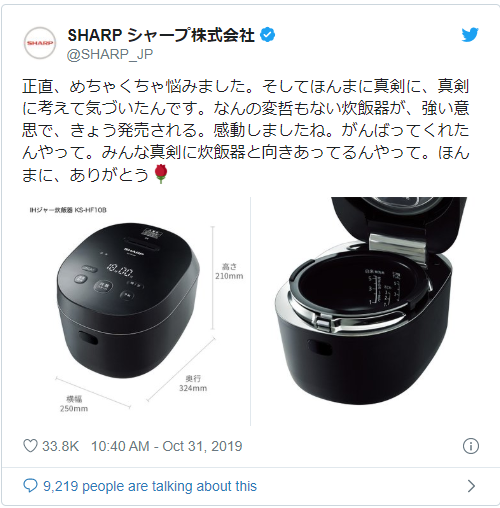
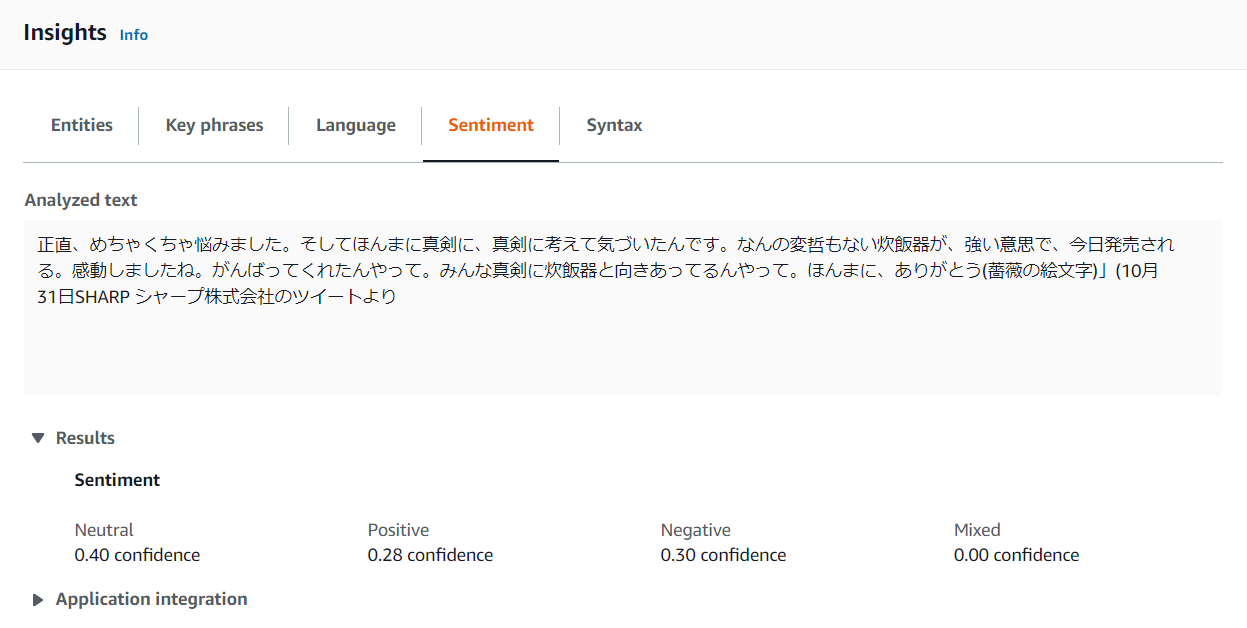
感情が深すぎます。
価格
Amazonお馴染みの従量課金制です。初回一年は無料枠が使えます。
エンティティ認識、感情分析、構文解析、キーフレーズ抽出、言語検出のリクエストは
100 文字で 1 ユニットとして計算され、各リクエストにつき 3 ユニット (300 文字) が
最低料金となります。こちらもAmazonの料金説明から抜粋しています。


最後に
ここまで抽出や分析ができると、テキストから最善の回答を得る、トピック別にドキュメントを整理する
独自のデータでのモデルのトレーニング、業界に特化したテキストのサポートが簡単に実現できそうですね!
例えば、顧客が満足か不満足かに関して頻繁にコメントのある製品について
その特徴を特定することができます。
製品レビュー、ソーシャルメディアフィード、ニュース記事、ドキュメント、その他のソースからテキスト内の意味や関連性も検出できるのでこれから沢山活用できそうです!
