大柳です。
サーバレス・アーキテクチャがここ数年ブームです。その中でもAWS Lambdaがサーバレスを実装する方法として、様々なシーンで活用されています。
サーバレスは、その名の通りサーバを用意することなく、コードを動かすことができるためとても便利ですが、従来のサーバ上でのシステム稼働と勝手が違います。特に本番業務で使うにあたっては、構成や運用を考える必要があります。
Lambdaをこれまで使ってきた中で、このあたりをいろいろと考えてきましたが、以下の2つの考慮が必要と考えています。
・動作確認やエラー調査に必要な情報をログに出力する
・エラー時の動作をハンドリングする
今回は、Lambdaでこの2点を実装する方法を考えてみましたので、ご紹介します。言語はPython3.6で実装しています。
結論
以下の3つを実装しました。
・ログ出力はloggerを使用して、環境変数によりロギングレベルを設定できるようにした
・エラーケースに応じたハンドリングを行う
・リトライしても正常終了しなかった場合はデッド・レター・キュー(Dead Leter Queue:DLQ)に入れて、通知させる
実装方法
上であげた3点について、詳細な実装方法を説明します。
ログ出力はloggerを使用して、環境変数によりロギングレベルを設定する
Pythonではloggerを利用することで、ログ出力をレベルに応じてハンドリングしてくれます。
さらに、Lambdaの環境変数を設けて、ロギングレベルを変更できるようにしました。
例えば、テスト時や障害調査時に、コード自体は変更することなく、ログ出力のレベルを変更できます。
サンプルコードは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import logging import os #Setting for logging #Environment Variable 'logging_level' allows to control logging level logger = logging.getLogger() logLevelTable={'DEBUG':logging.DEBUG,'INFO':logging.INFO,'WARNING':logging.WARNING,'ERROR':logging.ERROR,'CRITICAL':logging.CRITICAL} if 'logging_level' in os.environ and os.environ['logging_level'] in logLevelTable : logLevel=logLevelTable[os.environ['logging_level']] else: logLevel=logging.WARNING logger.setLevel(logLevel) logger.info('Loading function') def lambda_handler(event, context): # ロギングレベルに応じてログを出力できる logger.debug('1:debug') logger.info('2:info') logger.warning('3:warning') logger.error('4:error') logger.critical('5:critical') |
環境変数はインラインエディタの下にある入力フィールドで設定できます。
logging_levelログレベルに対してDEBUG/INFO/WARNING/ERROR/CRITICALを設定することでログの出力レベルを設定できるようにしました。
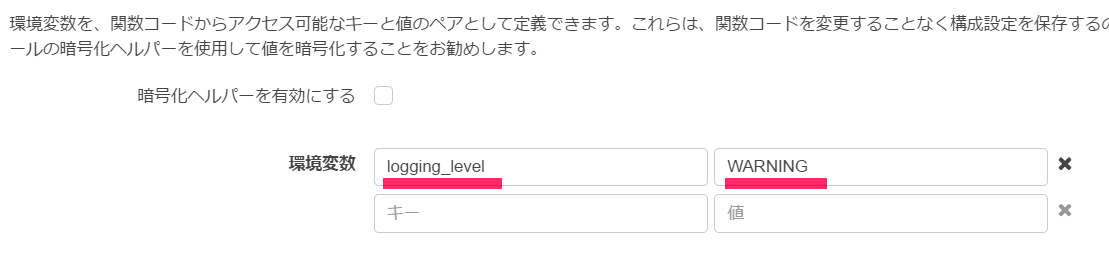
例えば、logging_levelをWARNINGに設定した場合以下のようなログが出力されます。
WARNING以上のレベルとして、ERRORとCRITICALも出力されていることが確認できます。

エラーケースに応じたハンドリングを行う
正常終了、異常終了(リトライあり)、異常終了(リトライなし)、リソース制約によるエラー(タイムアウトなど)をハンドリングしました。
Pythonの場合は各終了条件とコードは以下のように紐づけられます。
正常終了
returnで終了します。トリガーがS3のような非同期で呼ばれるものは、returnで何か値を返しても破棄されるので、戻り値で正常終了、異常終了を判断させることはできませんが、”normal end”を返すようにしています。
|
1 2 3 4 |
# 正常終了させるケース if 正常終了の条件: logger.info("MODE : normal") return "normal end" |
異常終了(リトライなし)
loggerでErrorレベルのログを出力、returnで終了します。
returnの戻り値で正常終了、異常終了を判断させることはできないので、異常終了したことを、ログ出力で明示的に分かるようにしています。
|
1 2 3 4 |
# 明示的に異常終了させるケース。リトライさせない if 異常終了の条件: logger.error("MODE : abend") return "abnormal end" |
異常終了(リトライあり)
raiseでエラーを明示的に発生させると異常終了し、リトライが動きます。
リトライは現在の仕様では最大2回行われます(最大3回までLambdaが実行される)。
|
1 2 3 4 |
# 明示的に異常終了させるケース。リトライさせる if 異常終了の条件: logger.warning("MODE :retry") raise Exception("Inner Error") |
リソース制約によるエラー(タイムアウトなど)
トリガーがS3のような非同期で呼ばれるものは、リソース制約で異常終了すると、自動的にリトライされます。
Lambda関数内で、タイムアウトしたら何かを行う、といったことを明示的にコントロールすることはできません。
なお、Lambda関数に渡されるcontextオブジェクトのcontext.get_remaining_time_in_millis()メソッドを呼び出せば、タイムアウトまでの時間を取得することができます。時間のかかる処理の場合は、残り時間を確認して、残りが少ない場合になんらかの処理を行うことも可能です。例えば、Lambdaから別のLambdaをキックして、処理を途中から再開する、というような使い方も可能です。
リトライしても正常終了しなかった場合はデッド・レター・キュー(Dead Leter Queue、DLQ)に入れて、通知させる
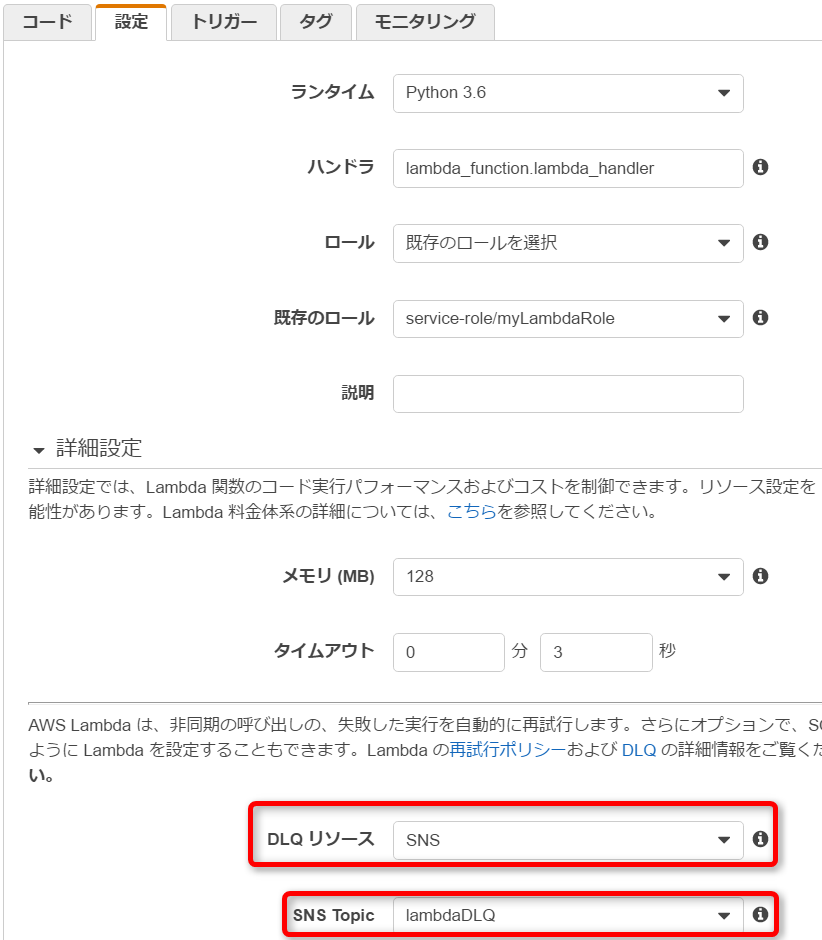
最大3回Lambdaが実行されても、正常終了されなかった場合は、DLQに入れることができます。
DLQとしてSQSとSNSが指定できます。以下の例ではSNSを選択し、SNS Topicを指定しています。今回の例ではSNSでメール通知させる設定をしてあります。
検証
以下のコードで検証していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import logging import os import urllib from time import sleep import re #Setting for logging #Environment Variable 'logging_level' allows to control logging level logger = logging.getLogger() logLevelTable={'DEBUG':logging.DEBUG,'INFO':logging.INFO,'WARNING':logging.WARNING,'ERROR':logging.ERROR,'CRITICAL':logging.CRITICAL} if 'logging_level' in os.environ and os.environ['logging_level'] in logLevelTable : logLevel=logLevelTable[os.environ['logging_level']] else: logLevel=logging.WARNING logger.setLevel(logLevel) logger.info('Loading function') def lambda_handler(event, context): # 検証のためトリガーになったS3のファイル名で条件分岐させる key = event['Records'][0]['s3']['object']['key'] # 正常終了させるケース if re.search(r"normal" , key): logger.info("MODE : normal") return "normal end" # 明示的に異常終了させるケース。リトライさせない if re.search(r"abend" , key): logger.error("MODE : abend") return "abnormal end" # 明示的に異常終了させるケース。リトライさせる if re.search(r"retry" , key): logger.warning("MODE :retry") raise Exception("Inner Error") # 明示的にタイムアウトさせてみる if re.search(r"timeout" , key): logger.error("MODE : timeout") sleep(4) return return |
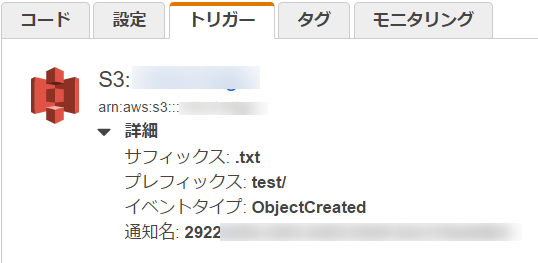
トリガーはS3へのオブジェクトの作成を設定しています。
指定したS3バケットにファイルが格納されたり、ファイル名が変更されたりするとLambdaが起動されます。
正常終了
トリガーとなるバケットにnormal.txtを保存するとLambdaが起動して、以下のようなログが出力されます。
正常終了してINFOを出力しています。

異常終了(リトライなし)
トリガーとなるバケットにabend.txtを保存するとLambdaが起動して、以下のようなログが出力されます。
Lambda上は正常終了していますが、ERRORレベルのログを出力させています。

異常終了(リトライあり)
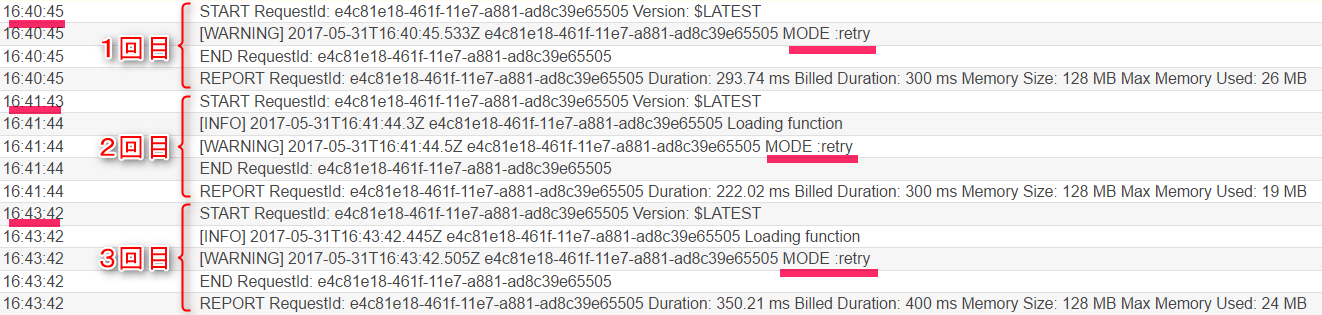
トリガーとなるバケットにretry.txtを保存するとLambdaが起動して、以下のようなログが出力されます。
例外(Exception)が出力されています。
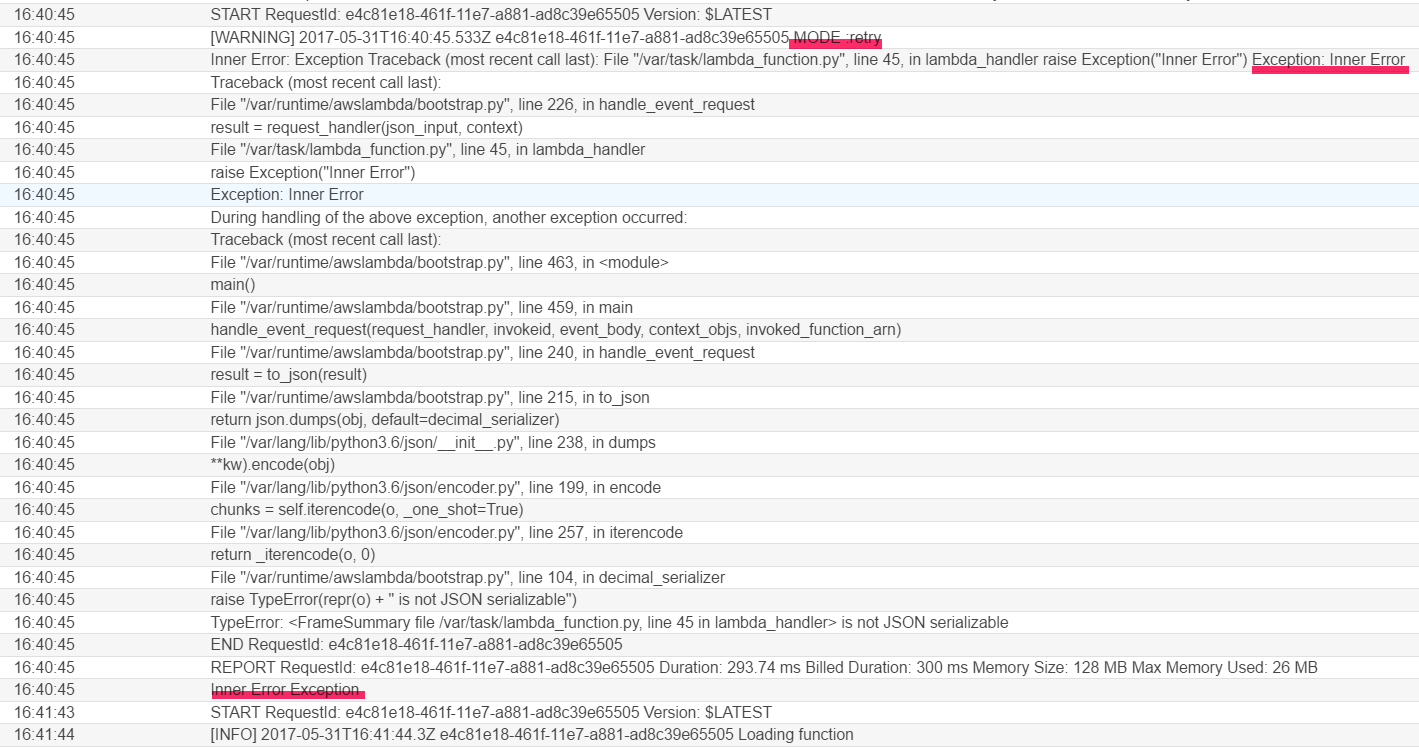
また、ログからリトライが発生し、合計3回実行されているのも分かります。
なお、1回目の実行から2回目の実行までは約1分、そして2回目の実行から3回目の実行までは約2分かかっています。
Exponential backoffというアルゴリズムで、再試行までの時間を1分、2分と長くしていく仕組みとなっているようです。
リソース制約によるエラー(タイムアウトの場合)
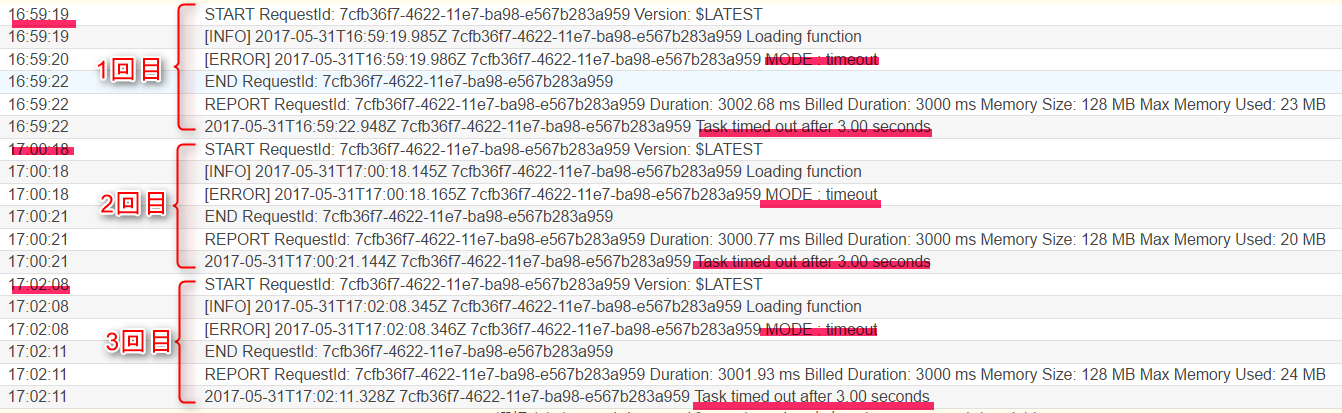
トリガーとなるバケットにtimeout.txtを保存するとLambdaが起動して、以下のようなログが出力されます。
タイムアウトにより処理が終了しているのが分かります。

この場合も、Exponential backoffで、再試行までの時間が1分、2分と長くなっています。
DLQへの通知内容
合計3回実行しても、リトライが失敗した場合は、DLQに登録され、SNSに連携、メールが送付されます。
今回の検証では異常終了(リトライあり)とリソース制約によるエラー(タイムアウトの場合)のケースの2件の通知が来ていました。

まとめ
loggerによるログ出力で、WARNINGやERRORなどレベルに応じたログを出力できることが確認できました。
CloudWatchでLambdaのログを監視すれば、エラー検知の仕組みを作ることもできます。
また、リトライオーバー(現状だと最大3回まで実行)時に通知する仕組みも構築できました。タイムアウト等で処理がNGになったことも検知できます。
Lambdaで提供されるメトリクスも組み合わせて活用すれば、Lambdaで構築した本番システムの監視が問題なくできそうです。
欲を言えば、リトライについては、リトライ回数もContextオブジェクトから取得できれば、さらに細かい稼働状況確認ができるので、今後の機能追加に期待しています。
最後までお読みいただき、ありがとうございました。
