こんにちは! JQです。
前回は『Amazon VPC編~Natインスタンスパート④~』ということで、RouteTableによるNatインスタンスの切替をお話しました。
今回は『Amazon EMR編~ElasticMapReduceの使い方パート①~』と題して、EMR(ElasticMapReduce)の使い方に関してお話していきたいと思います。
っと、その前にAWSの更新情報をご紹介します。
先日、AWS Elastic BeansTalkのIAM Rolesのサポートが発表されました。
IAM Rolesが使える事でBeansTalkの管理がさらに簡単にできますね!
さらに詳しい情報がお知りになりたい方は、公式サイトの「新着情報」をご覧下さい。
それでは、ここから本題に入りまして、EMRの使い方を試していきたいと思います。
今回はAWSのドキュメントの「ワードカウント」を試していきます。
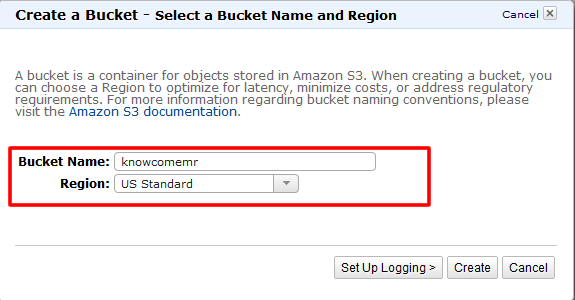
S3バケットの作成
1. まずはデータのinputやoutputに利用するS3バケットを作成します。
※EMRと別リージョンに作成すると転送量が発生しますので、ご注意下さい。
また、S3バケット作成の詳細については以前のレシピ「Amazon S3編~S3バケットを作成してみよう!~」も参照してください。
2. WEBコンソールで作成します。
解析するデータのアップロード
3. 作成したS3バケットで「Create Folder」ボタンをクリックしてinputというデータを置くフォルダ作成します。
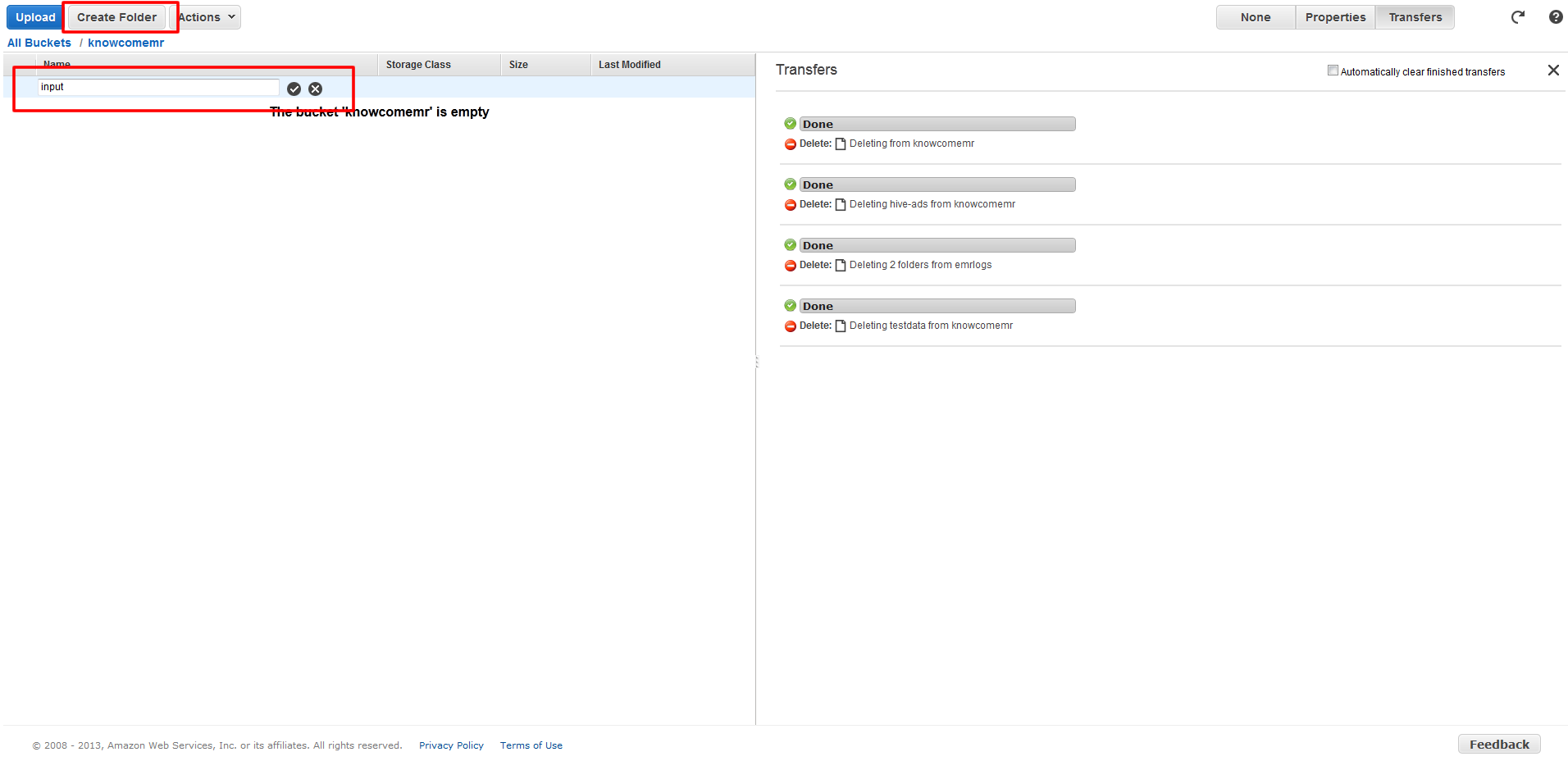
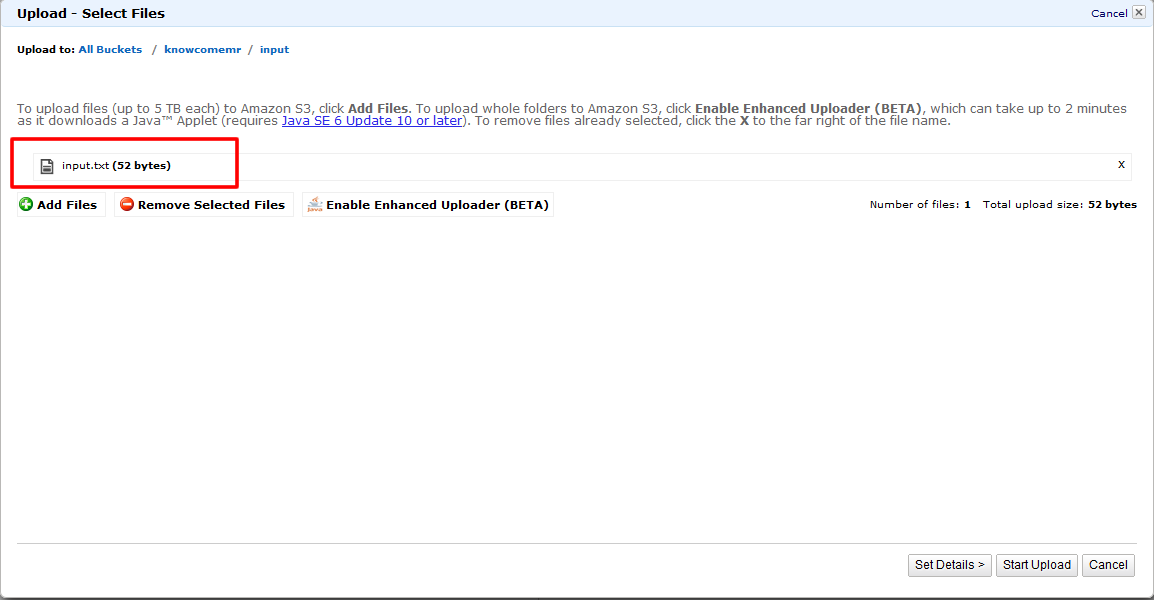
4. アップするデータとしてinput.txtというタブ区切りのファイルを作成します。
|
1 2 |
one two two three three three four four four four |
5. 「Upload」ボタンをクリックして作成したinput.txtをinputフォルダにアップロードします。
スクリプトのアップロード
6. 今回では「Streaming」というJOBタイプを利用して行います。
「Streaming」ではPython, Ruby, Perl, PHP, R, Bash, C++などの言語を利用する事が出来ます。
今回のサンプルスクリプトはPythonで作成されており、中身は以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#!/usr/bin/python """ import the system-specific parameters and functions (sys) and the regular expressions (re) modules """ import sys import re def main(argv): """ Read the first line of the input. """ line = sys.stdin.readline() """ Compile the specified regular expression into a regular expression object that identifies distinct words. """ pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*") """ Loop through the input, line by line, until you reach the end of the file. For each line, identify each distinct word and print it out in a format that identifies the type (LongValueSum), the word (converted to lower case) and the value "1", indicating that it's been found 1 time. This reduces the input data from a block of text to counts of individual words. The counts of each word will be rolled together by the built-in Aggregate Hadoop function used as the mapper for this job flow to create the output sum. """ try: while line: for word in pattern.findall(line): print "LongValueSum:" + word.lower() + "\t" + "1" line = sys.stdin.readline() except "end of file": return None if __name__ == "__main__": main(sys.argv) |
サンプルスクリプトはこちらからダウンロード出来ます。
または上記の内容を保存して作成します。
7. 保存したファイルを作成したS3バケットの直下にアップロードします。
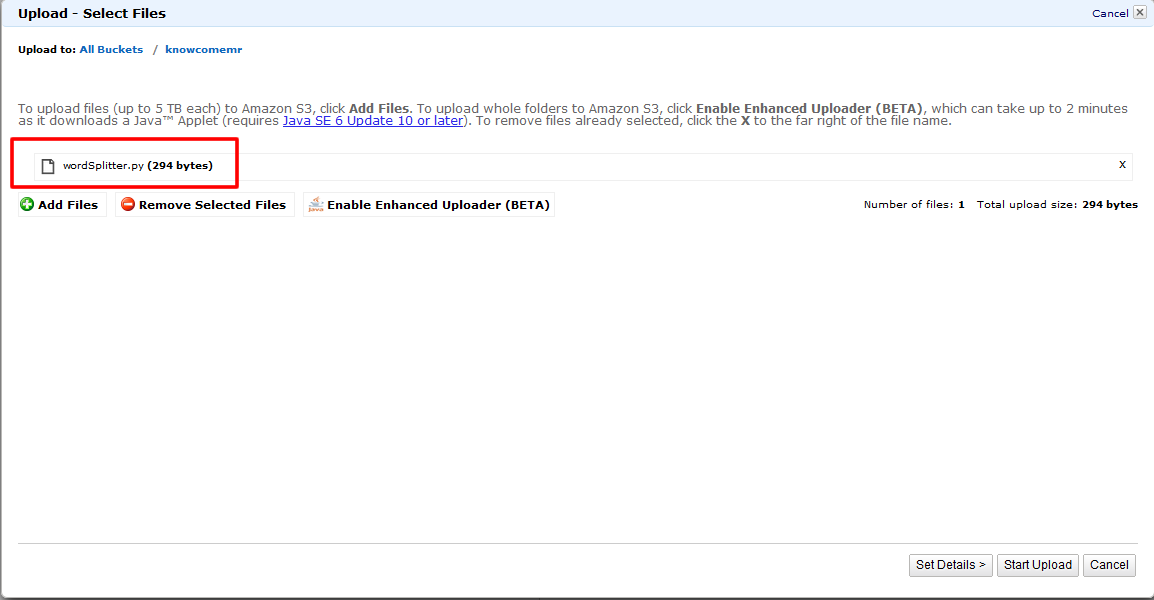
これで準備は完了となります!
いかがでしたでしょうか?
次回は『Amazon EMR編~ElasticMapReduceの使い方パート②~』ということで、実際にJobFlowを立ち上げてみたいと思います。
お楽しみに!
