今回は天候データをAmazon Machine Learningに流し込み3つの方法(二項分類、多項分類、回帰分析)で天気予測をしてみます。
記事の目的
記事の目的は以下の3つです。
・もっとも簡単な機械学習サービスであるAmazon Machine Learningを理解する
・同一データに対して3つの方法を利用することで3つの違いを掴む
・機械学習に対する属性情報の重要性を掴む
同じデータを複数の方法で利用することで、3つの違いや使い方がわかりやすく理解できると思います。
今回利用するデータは気象庁が提供する過去の天候データです。
http://www.data.jma.go.jp/obd/stats/etrn/
項目が多く載っている東京都のデータを利用しています。
http://www.data.jma.go.jp/gmd/risk/obsdl/index.php
Amazon Machine Learning(以後AML)の特徴
・操作が簡単
「世の中でもっとも簡単な機械学習」だと思います。
Jubatus、Mahoutなどを始め様々な機械学習を触っていますが、これほど簡単に利用できるのは他に無いと思います。
・結果の評価
OSSだと自分で評価する必要がありますが、作成されたモデルの評価をしてくれます。例えば、10万件のデータが有った場合に、7万件のデータでモデルを作り、残り3万件で答え合わせをしてくれるので、最初からモデルがどの程度有益かがわかって使える点が優れています。
・属性の選択
機械学習で精度を上げるためには、ユーザーやアイテムに対する属性情報を付与することが重要ですが、同時に属性情報が多すぎるとノイズとなり精度が落ちてしまいます。
ところが、AMLでは自動的に必要な属性の選択をしてくれます。今回の記事でも約20個の属性があるデータを利用しておりますが、AMLの中で自動的に必要な属性を判断してくれます。
操作編
では、早速AMLを使って複数の方法で天気予測をしてみましょう。
今回は以下のように行っております。同じデータを使って、3つの予測を行います。
明日は雨が降るか? Binary classification(二値分類・二項分類)
明日の天気 Multiclass classification(多値分類・多項分類)
明日の気温 Regression(回帰分析)
1. データの取得
http://www.data.jma.go.jp/gmd/risk/obsdl/index.php
にアクセスし、東京都の「年月日 日照時間(時間)、平均湿度(%)、平均蒸気圧(hPa)、平均雲量(10分比)、天気概況(夜:18時〜翌日06時)、天気概況(昼:06時〜18時)、平均気温(℃)、最高気温(℃)、最高気温(℃) 時分 、最低気温(℃)、最低気温(℃) 時分、降水量の合計(mm)、1時間降水量の最大(mm)、1時間降水量の最大(mm) 時分、平均風速(m/s)」という取れるだけの項目を取っています。
これはAMLの特徴の部分に記載したとおり、自動的に属性の判断をしてくれるので、項目を選ばず全て取れるものは取ってきています。
2. データの準備
このままではただのデータなので、AMLで利用できるように加工します。
1. 共通で日付のフォーマットの変換
共通で行うのが、「年月日」の隣の行に「月日」を追加します。
この時に「yyyy/mm/dd」となっているフォーマットを数値とするために「mdd」と変えます。
他にも時間が表示されている※※時分となっている部分も「yyyy/mm/dd h:mm」から「hmm」に変更します。
※年月日のフォーマットだと、年ごとに異なるデータとなってしまうので、年を削除して、月日も”/”があると文字列になってしまうので数字に変換しました。
2. 個々のファイルごとの変更
取得したデータに対して各目的用に加工します。全て挿入するのは末尾の行にしております。
Binary classification(二値分類・二項分類) 翌日の「降水量の合計(mm)」に対して0より大きいなら雨が降ったということなので1を、ふらない場合は0を入れます。
Execelでは「=IF(翌日の降水量の合計>0,1,0)」の様に式を入れることで取得できます。このファイルをbinary.csvという名称で保存します。
先頭行に項目名が入っている場合、項目名には日本語が使えないので削除して下さい。
保存後に必ずエンコードをShift-JISからUTF-8に変更して下さい。
※今回はTeraPadで再度開き、文字コードを指定して保存で変換しました。
文字コード:UTF-8
改行コード:LF
3. S3に準備した3つのファイルのアップロード
マネージメントコンソールからS3を選択して、ファイルをアップします。

4. AMLに遷移し、データソースの追加を行います。
初めて利用する場合は「Get Started」>「Launch」から利用できます。
既に利用したことがある場合は「Create New Datasource and Model」を選択します。
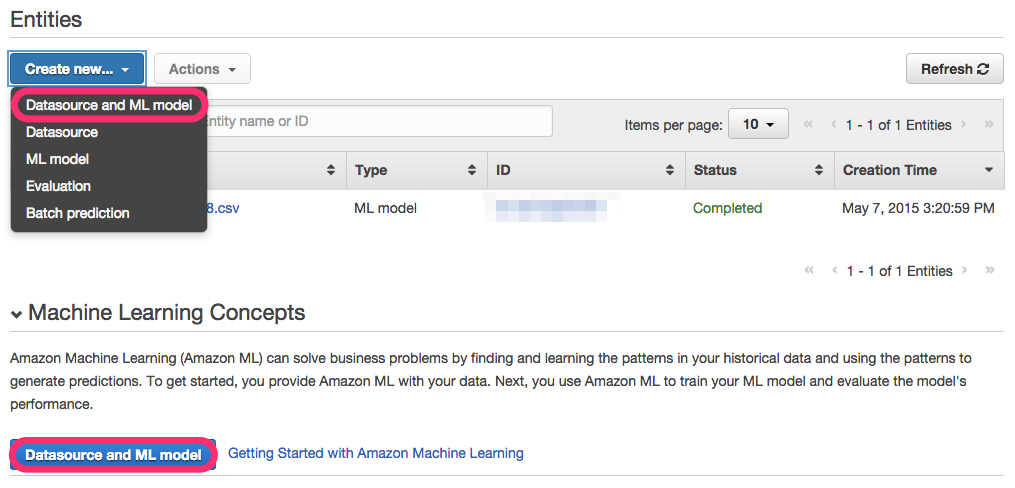
5. 入力データの選択
input dataの画面では先ほどアップロードしたS3のファイルを選択します。なお、この画面では自動的にバケット名やファイル名を取得してくれるので、先頭から数文字入れるだけで呼び出すことが出来ます。
Datasource Nameは任意ですが、あとで管理しやすいようにBinary Classificationと入力しました。
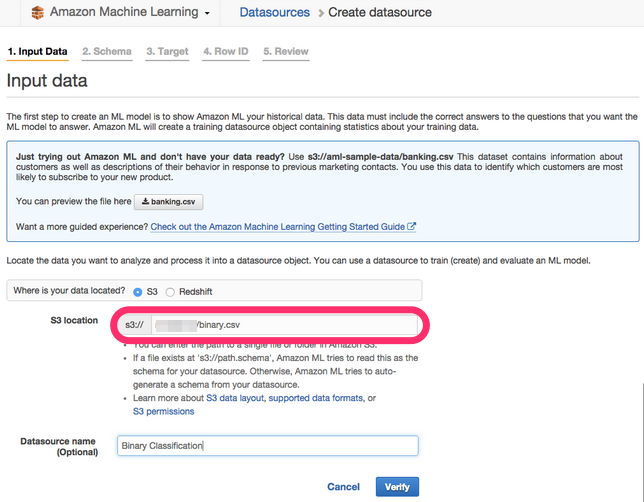
S3のパーミッションの確認が表示されるのでそのままYesを選択します。
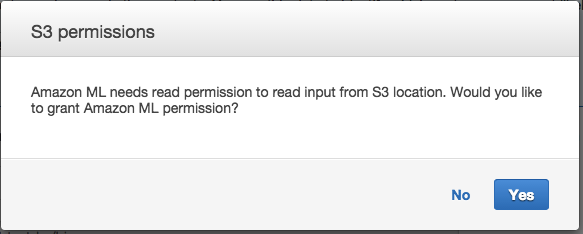
Verifyが完了すると以下の画面が表示されるので、そのままContinueをクリックします。
6. データの確認
Schema画面では各項目のフォーマットのチェックをします。
「Does the first line in your CSV contain the column names?」をYesにすることで先頭行の項目名が反映されますが、項目名に日本語は使えないので後でエラーになるので、手順1に戻って削除して下さい。
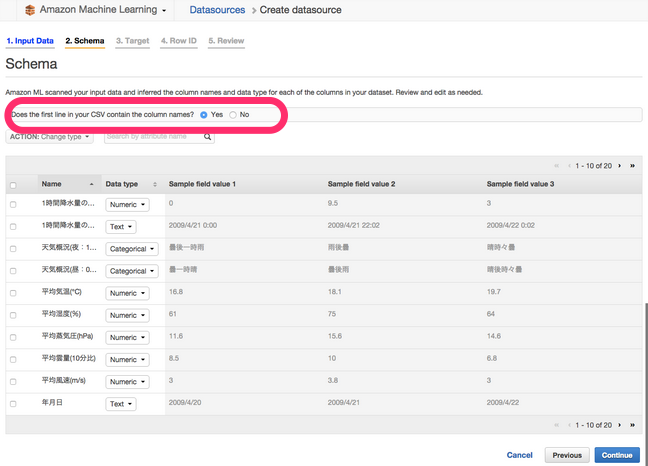
各項目が自動的に”Binary”, “Text”, “Numeric”, “Categorical”に振り分けられます。予測する項目「Var25(最終行)」がBinaryになっているかをチェックします。
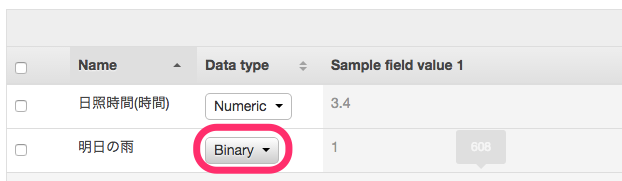
問題なければ「Continue」をクリックします。
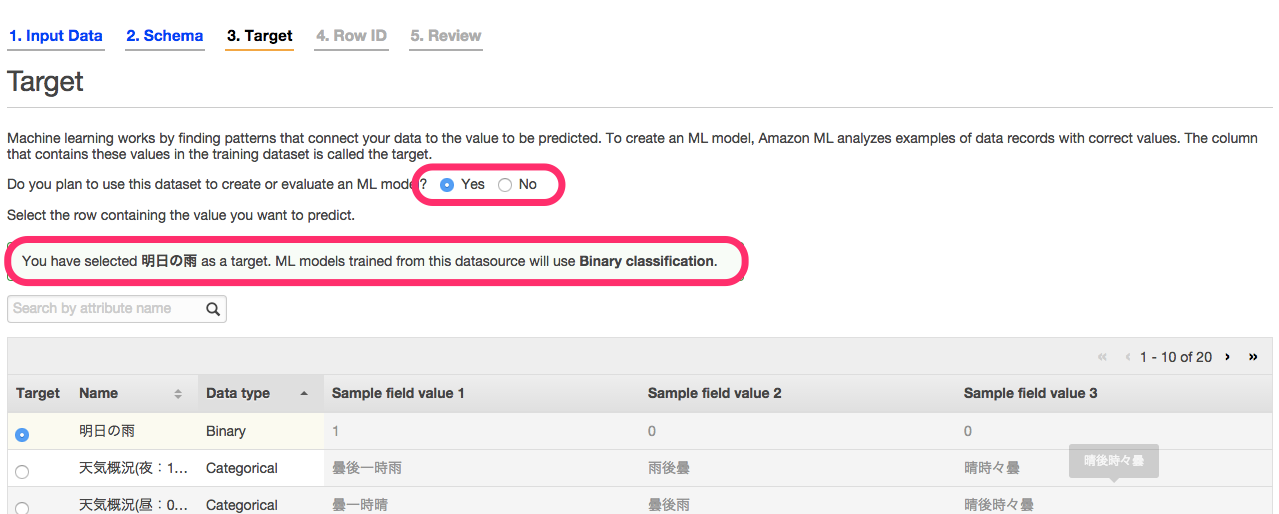
7. ターゲットの選択
target画面では予測対象となるカラムの選択をします。
カラムを選択するだけで、自動的に方法が選択されます。今回はBinaryデータを指定したため「Binary Classification」が選択されました。
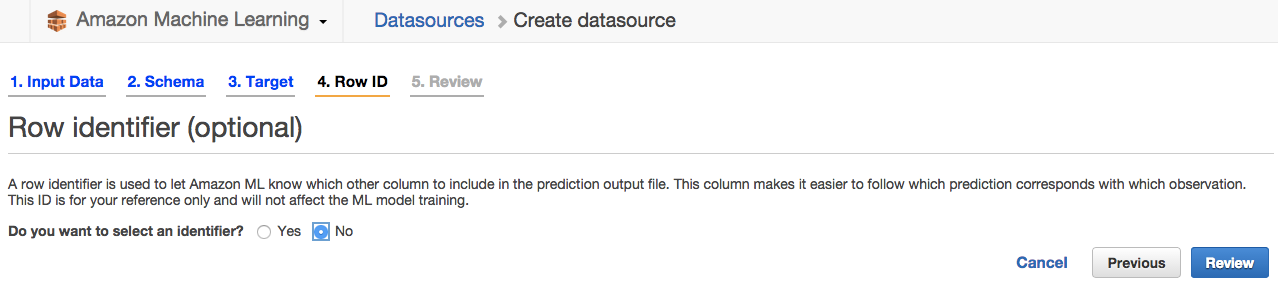
次にRow IDの選択がありますが、機械学習には影響しないとのことで特に選択しないで「Review」をクリックします。
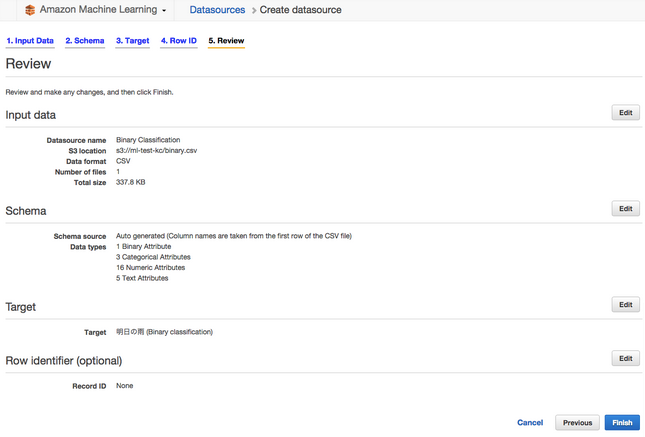
8. Review
Review画面でチェックして特に問題なければ、そのまま「Finish」をクリックします。
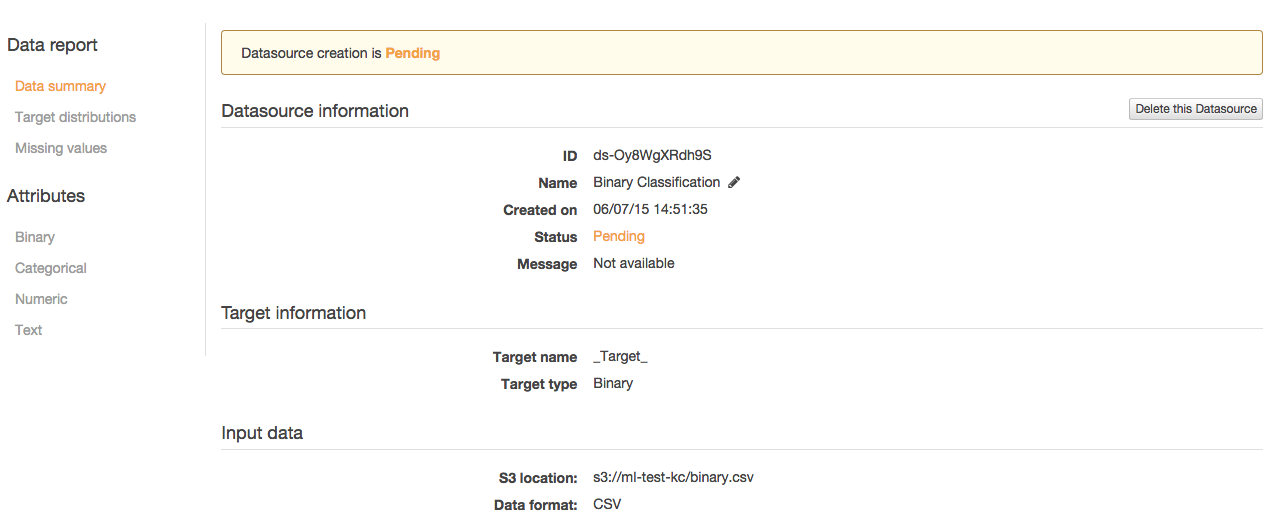
Data reportが表示され、一定時間でcompleteになります。
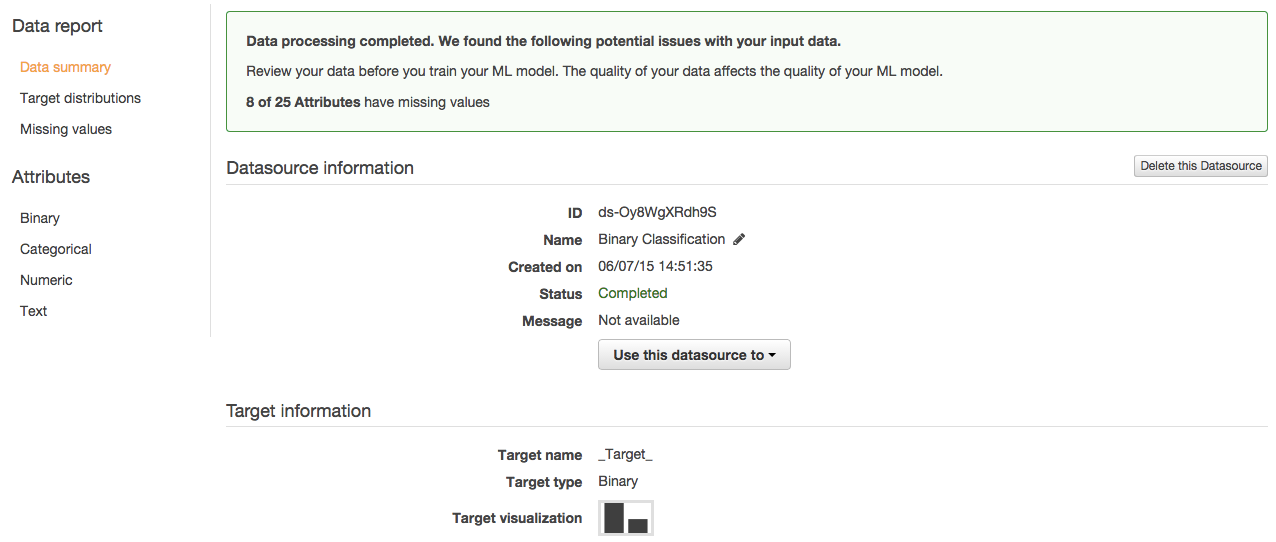
上図にあるように一部データに欠損があったようです。
9. データの確認
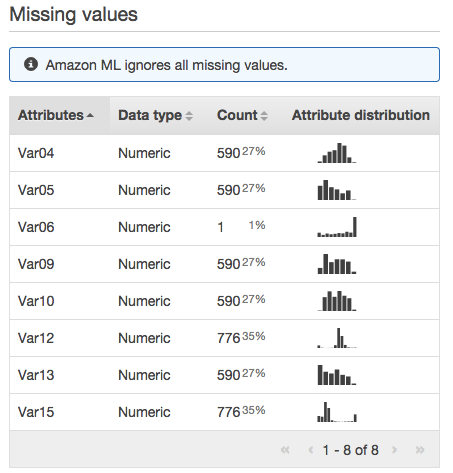
Missing Valuesに遷移すると、どの項目が何個(何パーセント)欠けているかが表示されます。
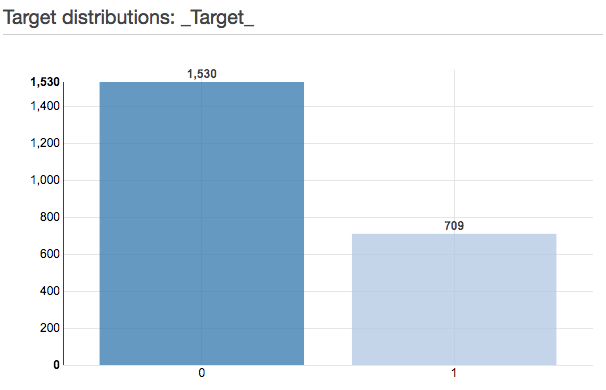
他にもTarget distributionsでターゲットとする項目の分布を確認することが出来ます。今回のデータでは
全く雨が降っていない 1530日
雨が降った 709日
となっております。
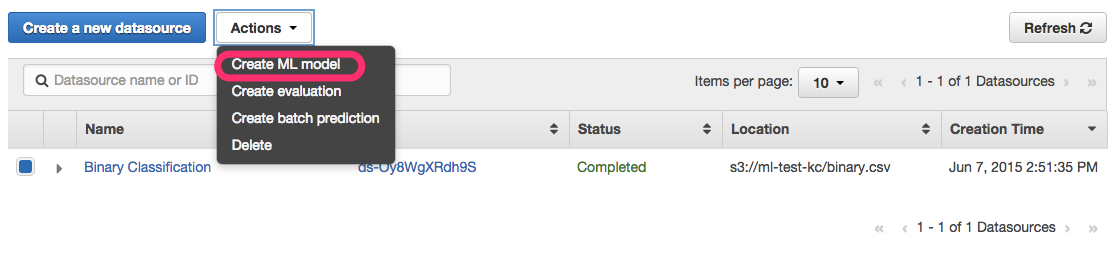
10. 機械学習モデルの作成
Datasourceから先ほど作成した”Binary Classification”にチェックをして「Create ML Model」をクリックします。
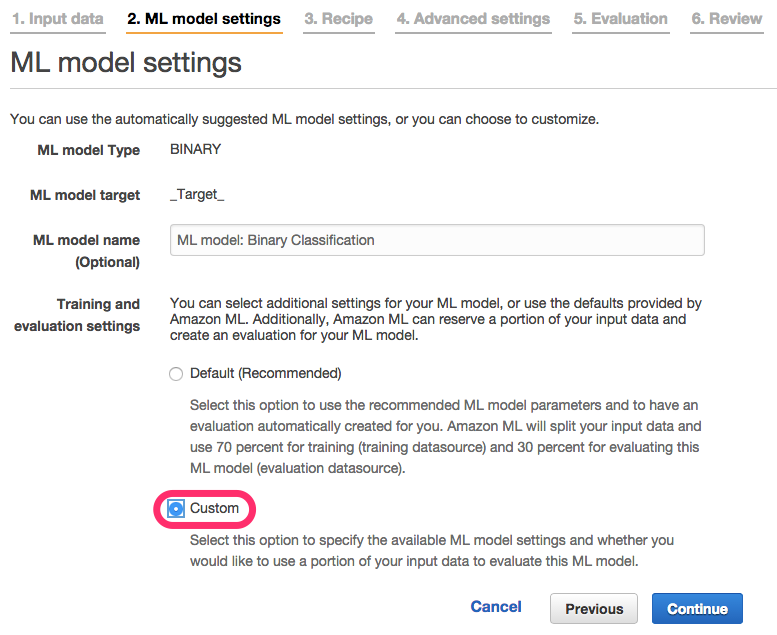
11. モデル作成のための設定
ML Model Settingsでは”Default”でも問題ありませんが、内容を確認する意味でもCustomを選択します。
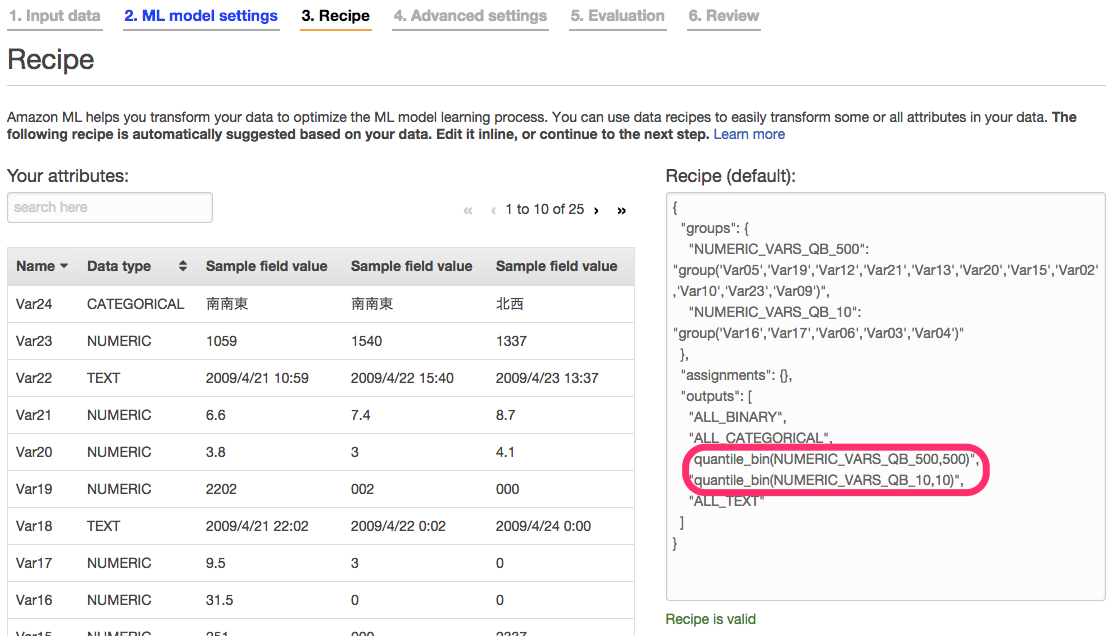
Recipeでは各項目の重み付けが確認できます。
月日、平均蒸気圧、平均気温、最高気温時分、最低気温、最低気温時分、降水量 最大時分、平均風速、最大風速、最大風速時分
の重みが高かったですが、予想では関係ないと思われた、一日のいつ最高/最低の状態が発生したかという時分情報が多く含まれていることが確認できました。
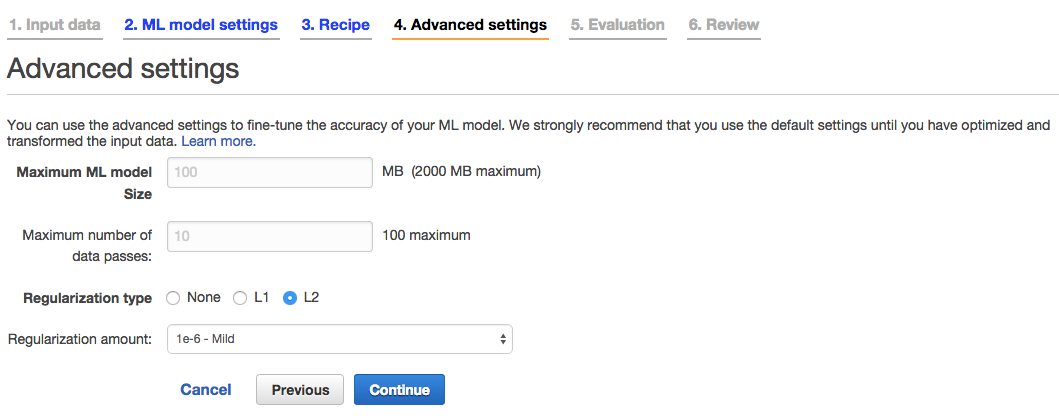
12. 追加設定
Advanced Settingsではデータサイズや正則化の方式を選ぶことが出来ますが、今回はそのまま「Continue」をクリックします。
13. 評価の方法
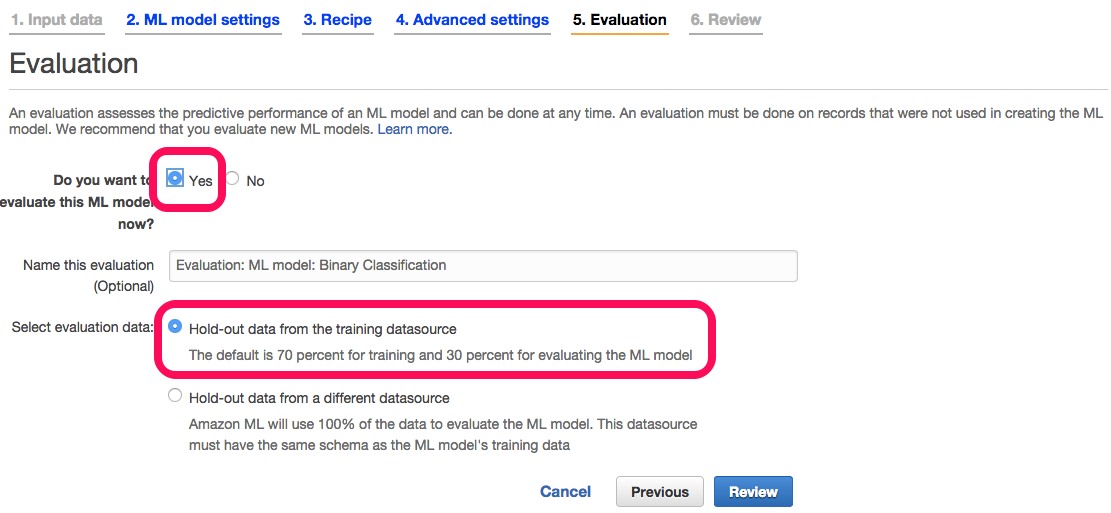
Evaluationではデータの評価の有無、評価の方法を選択します。
“Do you want to evaluate this ML Model now?”では直ぐに評価をするので”Yes”
を選択し、“Select evaluation data”ではデータの70%をトレーニング用、30%を評価に利用する”Hold-out data from the training datasource”にチェックします。
14. Review
Review画面でチェックして特に問題なければ、そのまま「Finish」をクリックします。
実行すると”ML model report”の画面に遷移し、一定時間でCompletedとなります。
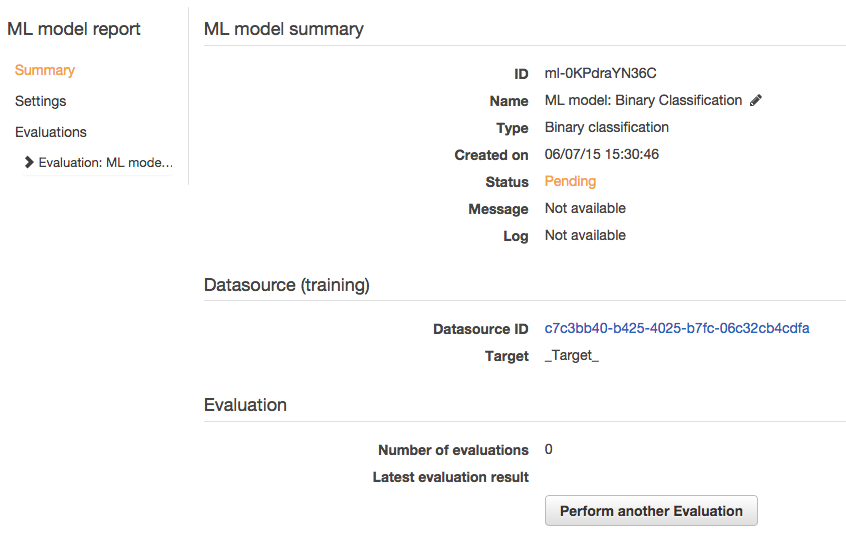
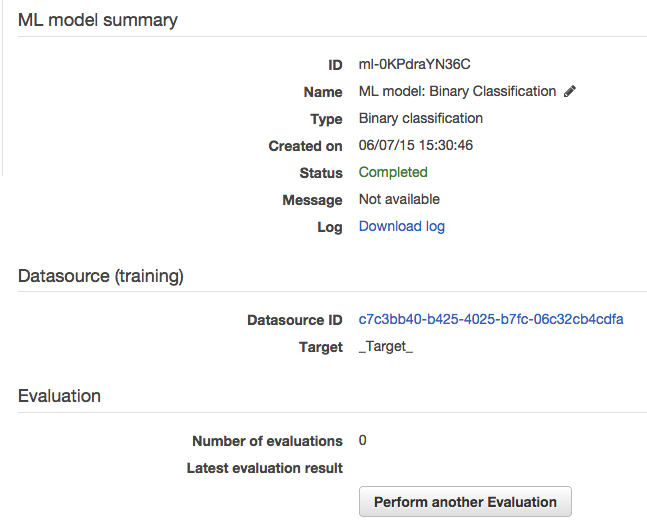
15. Evaluation Summary
評価のサマリーを確認することが出来ます。
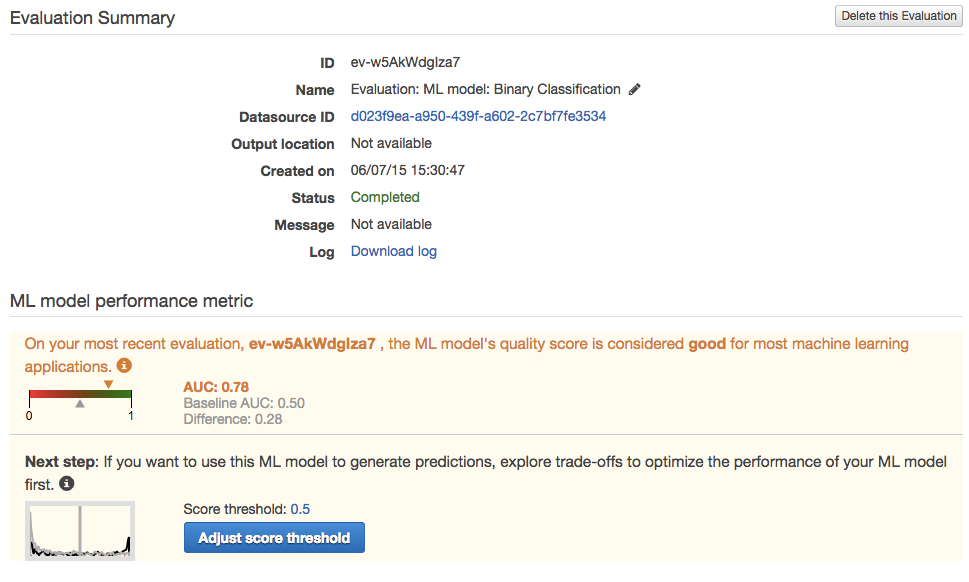
AUCが0.7797 と非常に高い数値が出ております。1に近いほどいいのですが高すぎると別に問題がある可能性が高いので今回くらいの数値が良い数値となります。
16. ML model performance
ここではtrueとfalseの値が出る確率をチューニングすることが出来ます。
見方としては以下となります。
true positive true(雨が降る)と予想し正解
true negative false(雨が振らない)と予想し正解
の2つの合計が75%となっており、75%の確率で当たります。
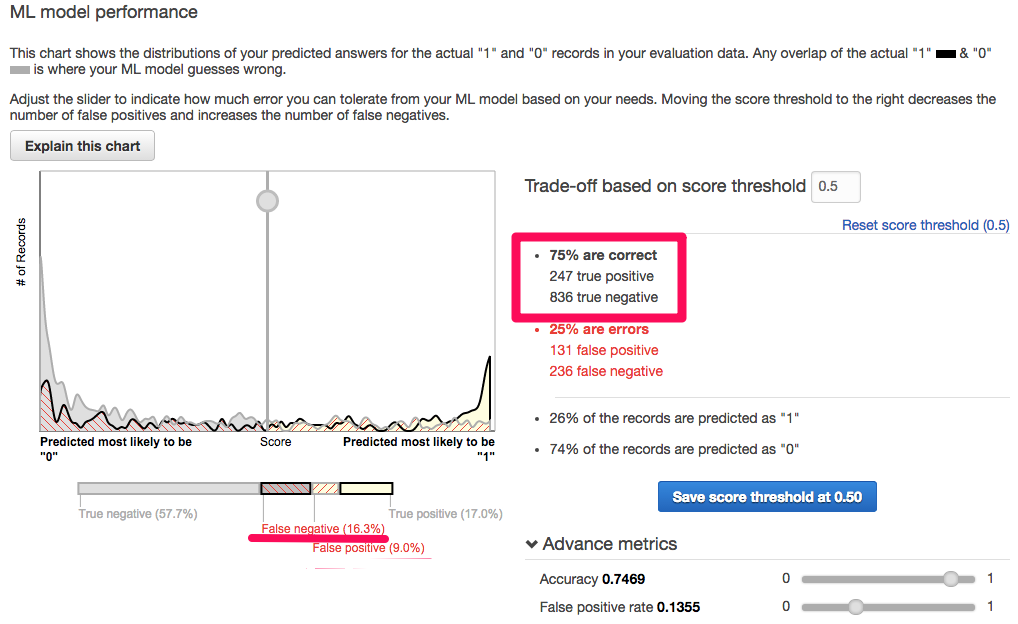
このままでは約16.3% 雨が降るのに”降らない”と予想しており、雨の日に傘を持って無いと困るので、雨が降る日に降らないと予想する確率を5%以下にしてみます。
◯マークをスライドするか、thresholdの値を変更して5%以下に設定して「Save score threshold at 0.02」をクリックします。

大幅にスライドをずらしたためにCorrectの確率が非常に下がりましたが、雨が降る日に降らないとでる確率は5%以下にする事が出来ました。
必要なリスクとのバランスを見ながら調整する事が出来ます。
いかがでしたでしょうか?
今回は「二項分類(Binary Classification)」を利用して、”明日は雨が降るか?”を予想しました。
次回は同じClassificationの一種である「多項分類(Multiclass Classification)」を利用して、”明日の天気“を予想します。
ナレコムクラウドでは機械学習を含めたAIやロボットといった事に興味があるエンジニアを募集しております。未経験の方でも興味がある方はお気軽にお問い合せ下さい。
◯Amazon Machine Learning
第1回
Amazon Machine Learningを理解するために3つの方法で天気予測をしてみた(二項分類編)
第2回
Amazon Machine Learningを理解するために3つの方法で天気予測をしてみた(多項分類編)
第3回
Amazon Machine Learningを理解するために3つの方法で天気予測をしてみた(回帰分析編)
