大柳です。
前回記事に引き続き、2017年6月のAWS DevDaysでAWS西谷 圭介さんがセッション「全部教えます!サーバレスアプリのアンチパターンとチューニング」でこんな話をされていました。
・メモリ割当量と比例してCPU能力が割り当てられる
・メモリを増やすことで、処理時間が減って、処理速度とコストも最適化できる可能性がある
LambdaのCPU処理性能はメモリ割当量が増えるほど高くなるということで、内部的にはより処理性能が高いユニットが割り当てられていると考えられます。また、ネットワークIO性能についてもメモリ割当量によって変わるのではないかと想像しました。そこで今回は、メモリ割当量によってLambdaの計算能力、ネットワークIOがどう変わるか、そしてコストがどう変わるかを検証してみます。
前回記事
【AWS Lambdaの小ネタ】グローバルスコープでのDuration(課金対象時間)を検証する
調査方法
以下のようなLambdaコードを実行して、計算能力(gzip圧縮処理)、ネットワークIn(S3からのファイル読み込み)、ネットワークOut(S3へのファイル書き出し)を実行して、その処理時間を計測してみます。
メモリ割当量は128MBから1536MBの間で全パターンを設定し、メモリ量ごとに処理時間を2回測定し、平均値を計算して評価しました。
今回知りましたが、メモリ割当量は128MBから64MBバイト刻みで増えていき、最大は1536MBが設定できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# ライブラリのimport import boto3 import gzip import shutil from datetime import datetime print('Loading function') # Functionのロードをログに出力 s3 = boto3.resource('s3') # S3オブジェクトを取得 def lambda_handler(event, context): bucket_name = 'xxxxxxxxxx' # バケット名を設定 key = 'bigfile.dat' # オブジェクトのキー情報 # ローカルのファイル保存先を設定 file_name = key + '_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') bucket = s3.Bucket(bucket_name) # バケットにアクセス #計測開始(Network in) start=datetime.now() bucket.download_file(key, '/tmp/' + file_name) # ⑨バケットからファイルをダウンロード end=datetime.now() time_read=end-start #計測開始(zip) start=datetime.now() with open('/tmp/' + file_name, 'rb') as f_in: with gzip.open('/tmp/' + file_name + '.gz' , 'wb') as f_out: shutil.copyfileobj(f_in, f_out) end=datetime.now() time_zip=end-start #計測開始(network out) start=datetime.now() obj = s3.Object(bucket_name, 'kenshou/bigfile.dat' ) # バケット名とパスを指定 obj.upload_file( '/tmp/' + file_name ) # gzファイルをS3に出力 end=datetime.now() time_write=end-start #結果の出力 print('read ' + str(time_read) + ' zip ' + str(time_zip) + ' write ' + str(time_write) + ' memory ' + str(context.memory_limit_in_mb)) return |
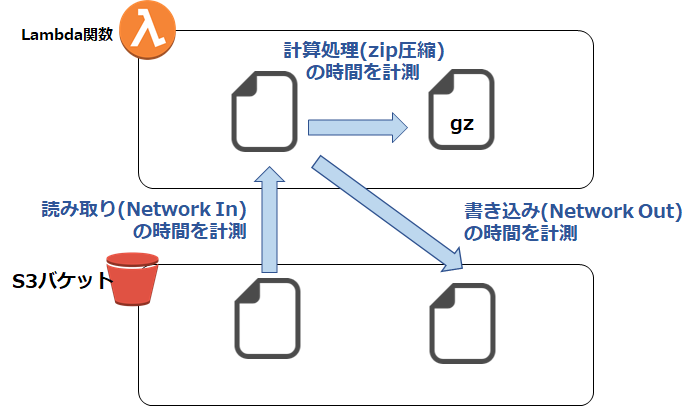
システムの構成を図示するとこのようになります。
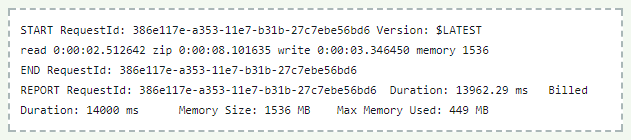
実行すると、以下のように処理時間をログとして出力します。
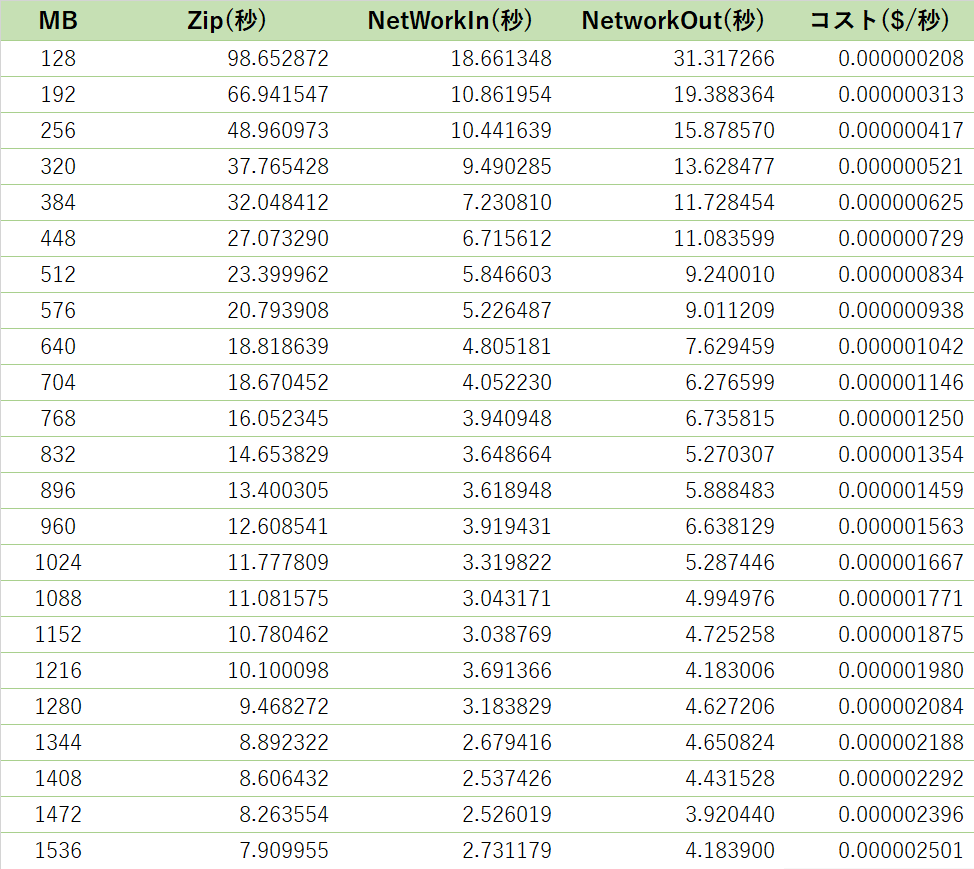
検証結果
まず、圧縮、ネットワークIn、ネットワークOutにかかった処理時間を比較してみます。
結果は以下のようになりました。
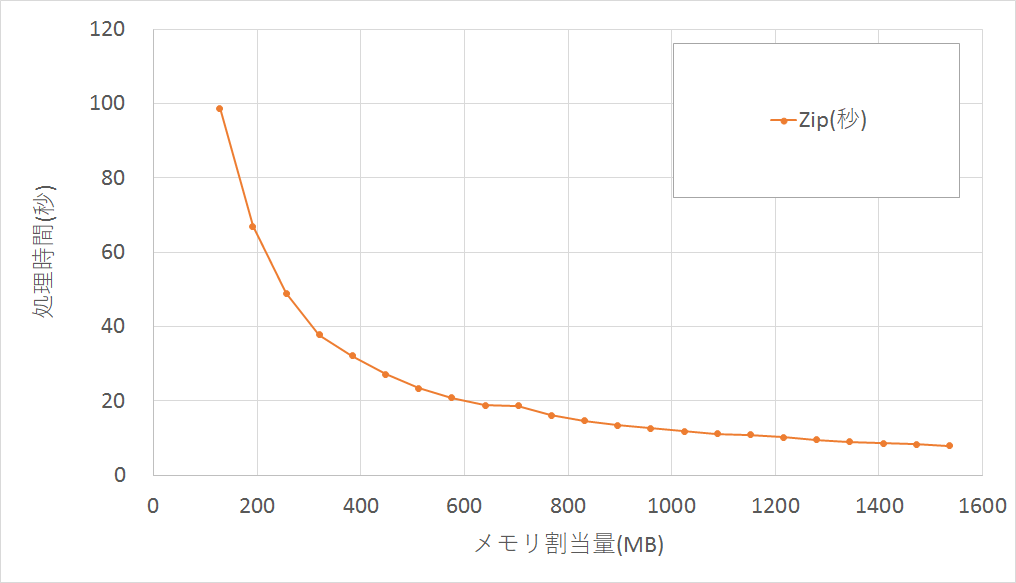
■計算能力(gzip圧縮処理)
メモリ割当量128MBと1536MBでは、処理時間に12.5倍の差がありました。メモリ割当量を増やすと計算性能も上がります。
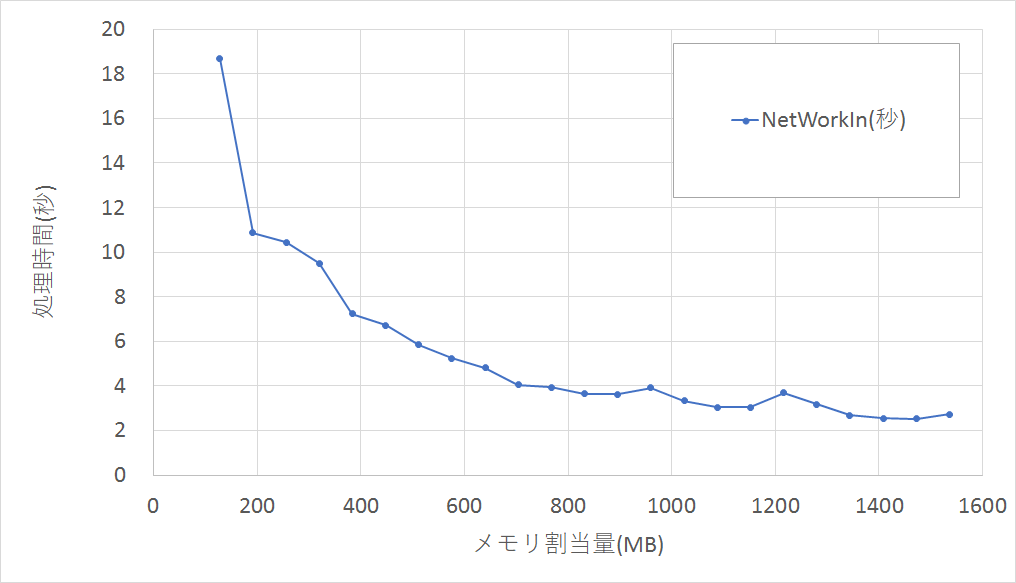
■ネットワークIn(S3からのファイル読み込み)
メモリ割当量128MBと1536MBでは、処理時間に6.8倍の差がありました。
gzip圧縮処理より差は少ないですが、ネットワークIn性能が上がりました。CPUの計算能力の寄与もあると思われますが、メモリ割当量が増えると割り当てられるユニットのネットワーク性能自体も上がっていると考えられます。
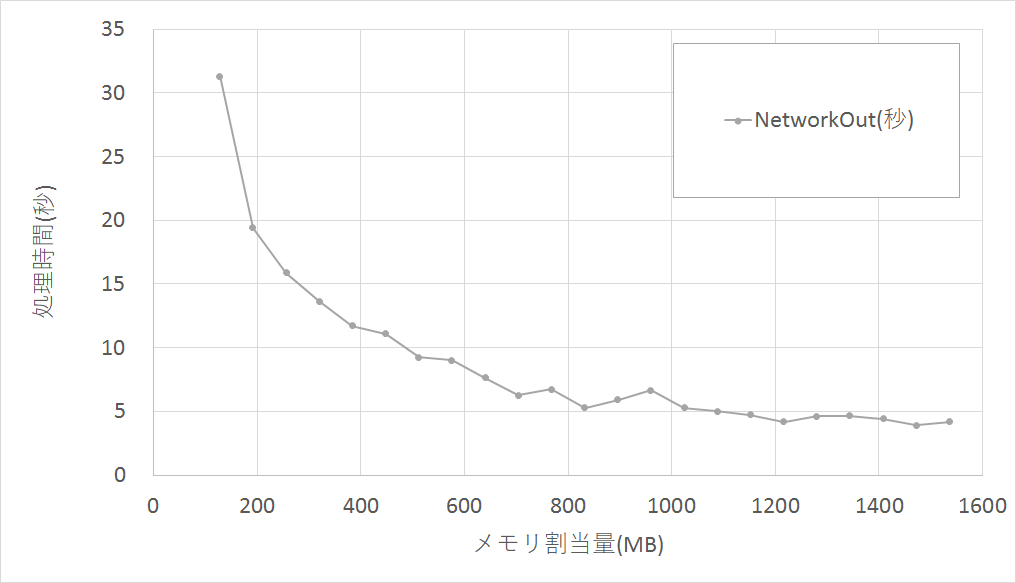
■ネットワークOut(S3へのファイル書き出し)
メモリ割当量128MBと1536MBでは、処理時間に7.5倍の差がありました。
こちらもネットワークInと同様に、メモリ割当量がネットワーク性能向上に寄与するようです。
計算能力、ネットワークIOともメモリ割当量を増やすほど向上することが分かりました。
メモリ割当量を増やすほど、処理性能は向上して処理時間が短くなります。その結果、単位時間当たりのLambda利用料金は増加する一方で、処理時間が短くなることで課金対象時間は減少し課金額は減ります。
コストの増加と減少の要因が寄与する中で、最終的なコストがどうなるかも評価してみます。
コストの計算は、上の表のメモリ割当量ごとの処理時間にLambdaのコスト($/秒)をかけて試算しています。
実際にはLambdaの課金は利用時間(Duration)を100ms単位で切り上げた時間で課金されますが、今回は単純化のため、切り上げはせずに試算しています。
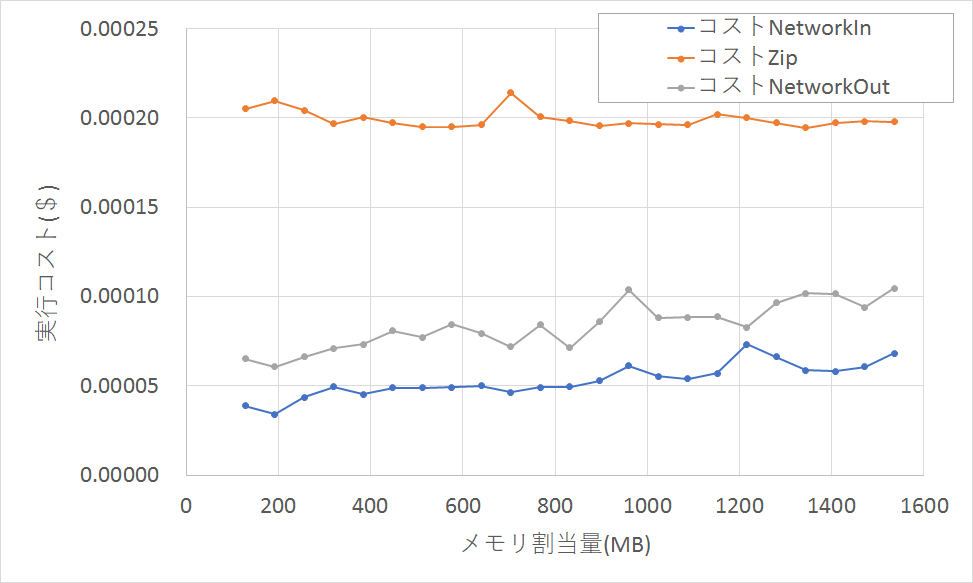
■コストベースの比較
計算能力(gzip圧縮処理)は横ばいです。同じ負荷の処理を行う場合、メモリ割当量を増やしても、処理時間が短くなる結果、全体のコストは変わらないようです。
ネットワークIn、ネットワークOutについては、メモリ割当量が増えるとコストは微増する傾向になりました。
まとめ
メモリ割当量を増やすと時間当たりのコストも上がりますが、性能があがって処理時間が短くなる分、最終的なコストは変わらない、という結果になりました。「時は金なり」という考え方で行けば、できるだけメモリ割当量を増やして、処理時間を短くする方が良さそうです。
ただし、時間当たりの課金コストは比例して大きくなるので、Lambdaの処理件数や1件当たりの処理時間などを検討した上でメモリ割当量を決めておかないと、コストが膨むので気を付けましょう。想定外の課金を避けるために、メモリ割当量を大きくした場合は、Lambdaのタイムアウト値を低めに設定したり、CloudWatchで処理件数をモニタリングしたりして、「Lambda破産」を防ぎましょう。
