はじめに
こちらの記事でAmazon Redshift MLの機械学習モデル構築のためのインフラ関連などの準備をしました。
本記事では、実際に機械学習モデルをAmazon RedshiftMLで作成したいと思います。
RedshiftMLについて概要を知りたい方はこちら:
ローデータテーブル作成
以下 SQL クライアントでクエリをたたいています。
モデル作成の権限をユーザーに付与します。
|
1 2 3 |
1 GRANT CREATE MODEL TO awsuser; |
作成するデータベースやモデルを保持するスキーマを作成します。
|
1 2 3 |
2 CREATE SCHEMA redshiftml_test; |
ローデータ用のテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
3 create table redshiftml_test.minethatdata_orig( recency int4, history_segment varchar(256), history float (8), mens boolean, womens boolean, zip_code varchar(256), newbie boolean, channel varchar(256), segment varchar(256), visit boolean, conversion boolean, spend float (8) ); |
S3 から CSV データをインポートします。CSV data S3 URI と iam-role-arn はリソース作成時に拾ったパラメータです。
|
1 2 3 4 5 6 7 8 |
4 copy redshiftml_test.minethatdata_orig from '{CSV data S3 URI}' iam_role '{iam-role-arn}' csv IGNOREHEADER 1 ; |
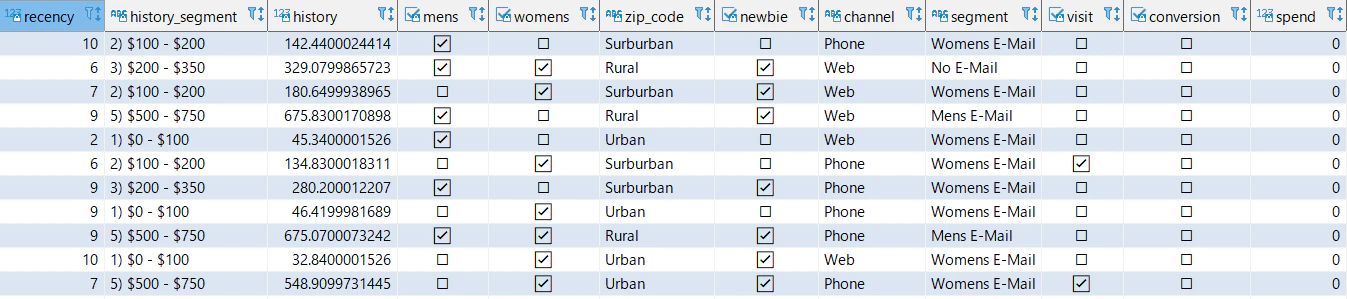
ローデータテーブルのプレビュー
|
1 2 3 |
5 select * from redshiftml_test.minethatdata_orig limit 10; |
out
学習用テーブル作成
モデル学習しやすいようにテーブルを作成します。
- segment (受け取ったキャンペーンメールの種類。Mens E-mail, Womens E-mail, No E-mail) を 1/0 で表現 (w 列)
- Spend (過去2週間の購入金額) を目的変数として利用 (y 列)
- 通し番号を unique_id として付与
- unique_id ベースで TRAIN データと TEST データに分割 (assigm 列)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
7 CREATE TABLE redshiftml_test.MineThatData AS SELECT *, CASE WHEN unique_id >= 0.50 THEN 'TRAIN' ELSE 'TEST' END AS assign FROM ( SELECT *, RANDOM() AS unique_id, CASE segment WHEN 'Mens E-Mail' THEN 1 WHEN 'No E-Mail' THEN 0 END AS w, spend AS y FROM redshiftml_test.minethatdata_orig WHERE segment IN ('Mens E-Mail', 'No E-Mail') ) |
学習用テーブルのプレビュー
|
1 2 3 |
8 select * from redshiftml_test.MineThatData limit 10; |
out

モデル構築
TRAIN データに割り振ったユーザーから (assign = ‘TRAIN’)、男性向けメールを送るを送ったユーザーを抽出し (w = 1) 、指標値を MSE とした回帰モデルを作成します。
- MSE (平均二乗誤差)
- 成果位地と予測値の差を事情し、平均値をとったもの
- 実際と予測値の誤差が大きいほどモデルの精度が悪いと判断
- 外れ値にも過剰適合(=過学習)してしまう可能性も
今回のケースだとこのようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
9 CREATE MODEL redshiftml_test.uplist_treatment FROM ( SELECT recency, history, mens, womens, zip_code, newbie, channel, y FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TRAIN' ) TARGET y FUNCTION uplift_treatment IAM_ROLE '{iam-role-arn}' AUTO ON PROBLEM_TYPE REGRESSION OBJECTIVE 'MSE' SETTINGS ( S3_BUCKET '{s3 bucket name}' ); |
以下クエリでモデルの概要を取得できます。
|
1 2 3 |
10 SHOW MODEL redshiftml_test.uplist_treatment |
今回のデータセットではモデル構築の完了に一時間ほど要しました。
完了次第、SageMaker > ハイパーパラメータの調整ジョブからジョブの実行にかかった時間などを見ることができます。
未完了の状態で推論するクエリを投げてもモデルの準備ができていないとエラーが返ってきます。
のんびり待ちましょう。
推論実行
推論結果の参照を Redshift の別ユーザーが行う場合は、権限を付与します。
|
1 2 3 |
11 GRANT EXECUTE ON MODEL redshiftml_test.uplist_treatment TO awsuser; |
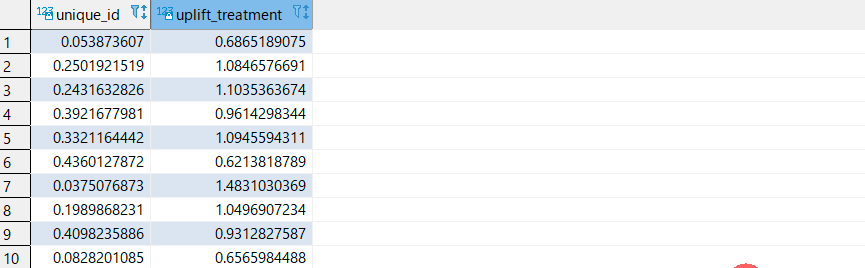
以下で Redshift 経由で推論結果を取得できます。uplift_treatment の数値が高いユーザーに対して優先的に販促キャンペーンを打てそうです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
12 SELECT unique_id, redshiftml_test.uplift_treatment(RECENCY, HISTORY, MENS, WOMENS, ZIP_CODE, NEWBIE, CHANNEL) FROM ( SELECT * FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TEST' ) |
out
CREATE MODEL構文
AUTO_ML を利用する場合
上記では AUTOML 機能を用いました。 (AUTO ON)
もっともシンプルに実装する場合の基本構文は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 |
AUTO_ONの場合 CREATE MODEL model_name FROM { table_name | ( select_query ) } TARGET column_name FUNCTION prediction_function_name IAM_ROLE 'iam_role_arn' SETTINGS ( S3_BUCKET 'bucket' ) |
備考
メトリクス
機械学習モデルの品質を測定するための指標として5種から選択できます。
データセットや予測対象の属性、予測結果の用途に応じてどのメトリクスが適当かどうか変わってきます。
- Accuracy
- 他項分類のデフォルトメトリクス
- MSE
- 回帰のデフォルトメトリクス
- 利用されるデータに外れ値が多い場合精度が低くなりやすいので注意
- F1
- 二項分類のデフォルト
- 適合率と再現率を等しく重視する
- 回帰でMSEだと精度が上がりにくい場合にも
- F1macro
- 他項分類で利用
- F1 スコアの他項分類版
- AUC
- 確率を返すロジスティクス回帰などの二項分類で利用
ハイパーパラメータ調整ジョブの実行時間
モデル学習がいつ終わるか把握したいものですが、SQL クライアントからはこの情報をパッシブに取得できません。以下迂回策です。
CloudWatch を利用
先述の通り、RedshiftML の学習データは指定の S3 バケットに保存され、学習完了時に削除されます。これをトリガーにして CloudWatch で通知を受け取るように設定します。
なお、S3_GARBAGE_COLLECT オプションを明示する際は ON にする必要があります (デフォルトはON)
MAX_RUNTIME を設定
トレーニングの最大時間を指定するオプションです。
デフォルト値は 90分 (5,400秒) で、データセットが小さい場合は指定値よりも早く完了します。
ジョブ完了通知ではありませんが、短時間でトライアンドエラーして進めたい時に使えそうです。
参考クエリ
使うクエリを乗せておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
0 -- アクセス可能なモデル一覧取得 SHOW MODEL ALL; -- Redshift データベースからのモデルの削除 drop model redshiftml_test.uplist_treatment; -- テーブル名一覧取得 SELECT DISTINCT pg_table_def.tablename FROM pg_table_def WHERE schemaname = 'public' AND tablename NOT LIKE'%_pkey' ORDER BY tablename; -- インポートでエラーが出る場合にはこちらからログを参照 select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10; |
まとめ
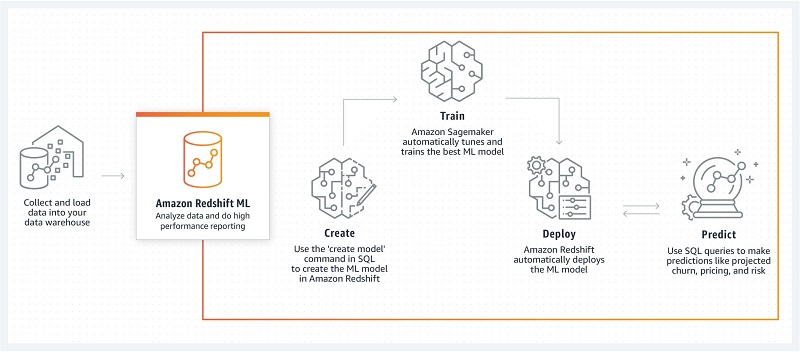
SQL だけで機械学習モデルのデプロイ、Redshift 経由で推論結果の取得までできるのは便利だと思いました。
バックエンドでは SageMaker Autopilot が動作しているので、SageMaker のコンソールからモデルをデプロイすればエンドポイント経由での推論も可能です。
そうなればドリフト値を SageMaker Model Monitor でトラッキング出来るので MLOPS 環境の構築のハードルも下がるのではないでしょうか?
Redshift上にある顧客データを活用できる便利なサービスなので、Redshift ユーザーは是非触ってみてください。
参考リンク
モデリング部分のSQLスクリプトはこちらの記事からお借りしたものをベースにしています


Amazon Redshift ML の紹介記事です。
公式ドキュメント

