こんにちは!中の人です。
前回までのレシピではAmazon Redshiftへの様々な接続方法を紹介しました。
※ Amazon Redshiftへの接続編のレシピは、以下を参照してください。
■Amazon Redshift編~プログラムからRedshiftを操作してみよう!(ODBC接続)~
■Amazon Redshift編~プログラムからRedshiftを操作してみよう!(PG接続)~
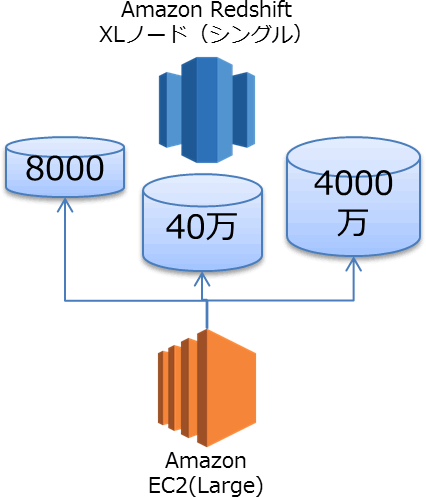
今回は『Amazon Redshift編~接続方法(ODBC/JDBC/PG接続)別パフォーマンス比較~』と題して、前回までのレシピで紹介したそれぞれの接続方法でパフォーマンスが異なるか検証してみました。
約8千行
約60万行
約4000万行
のテーブルを用意して検索してみました。
RedshiftはXL ノードをシングル構成での検証です。
クエリ1:select COUNT(*) from TABLE_NAME where id<1000
クエリ2:select * from TABLE_NAME where id<1000
を実行してみました。
■約8千行(10回平均)
| ODBC | PG接続 | JDBC | |
|---|---|---|---|
| クエリ1 | 0.04 | 0.04 | 0.02 |
| クエリ2 | 0.08 | 0.06 | 0.60 |
行数が少ないので、クエリ1・2の差はそれほどありません。
■約60万行(10回平均)
| ODBC | PG接続 | JDBC | |
|---|---|---|---|
| クエリ1 | 0.07 | 0.31 | 0.03 |
| クエリ2 | 3.11 | 3.05 | 3.72 |
参照する行数が増えると他のSQL同様クエリ1,2での差が徐々に発生します。
■約4000万行(10回平均)
| ODBC | PG接続 | JDBC | |
|---|---|---|---|
| クエリ1 | 0.39 | 0.74 | 0.35 |
| クエリ2 | 16.91 | 16.94 | 17.67 |
かなりクエリ1,2での差がはっきり出て来ました。
いかがでしたでしょうか?
上記のことから以下の事が分かります。
・ 接続方式での差はごく僅かなので、使い勝手や環境にあわせて好みの接続方式を利用したほうが良い。
・ 他のデータベースと同様に、正しくクエリを使用することは重要である。
クエリによって大きく差が出るのは想定通りでしたが接続方式によっても、もっと差が出ると思っていました。
環境により異なる場合はあるかもしれないですが、安心してお好みの接続方式を使うことをオススメします。
次回は『Amazon Redshift編~複数クエリ同時実行時パフォーマンス(シングル)~』と題して、同時処理を行った時のパフォーマンスについて紹介します。
お楽しみに!
