こんにちは!HALです。
今回は、リアルタイム分析を実現する強力なツールシリーズとして、前回紹介した「Storm」に加え、Hadoopよりも強力に高速に解析処理が実現可能な「Spark」というSWをご紹介したいと思います。
▼前回の記事はこちら
リアルタイム分析を実現する強力なツールシリーズ~storm~
■Sparkとは?
ビッグデータを分散処理で高速に処理が可能な[Hadoop]は聞いたことがある人も多いかと思います。AWSでもHsdoopが実行可能なEMRというサービスもありますしね。
Sparkは、Hadoopに比べ、インメモリー処理を主体とするため、より高速(10倍~100倍ぐらい)で低遅延の分析が可能となります。
次世代のビッグデータ処理基盤として期待が集まっているフレームワークです。
Sparkは、以下の構成要素となっています。
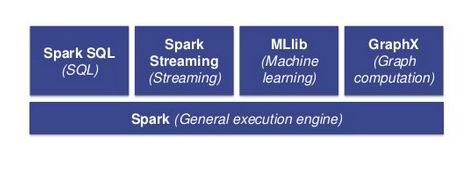
Spark:Hadoopと同じくバッチ処理を実行する、他のフレームワークの基盤
Shark/Spark SQL/BlinkDB:DWHのようなインタラクティブでSQLの処理を実行
Spark Streaming:リアルタイム・ストリーミング処理を実行
MLlib:機械学習のライブラリ
GraphX:グラフ計算ライブラリ
■SparkとAWS
上述のHadoopが実行できるAWSのAmazon EMR(Elastic MapReduce)でSparkも実行することが可能です。
Run Spark and Shark on Amazon Elastic MapReduce
http://aws.amazon.com/articles/Elastic-MapReduce/4926593393724923
そして、AWSのブログでもSparkに最適なインスタンスは、i2.8xlargeインスタンスタイプと紹介されております。
http://aws.typepad.com/aws_japan/2014/04/new-instance-types-for-amazon-elastic-mapreduce.html
いかがでしたでしょうか。
今回は概要のみでしたが、別の機会にSparkについて、もっと掘り下げてご紹介したいと思います!
お楽しみに!!
