前職はトラック運転手をやっていたDreamです。
入社し3週間が経ち、ようやくオフィスワークにも慣れてきたかなと感じています。
今回の記事はタイトルの通りAWSのオンラインセミナーでS3について勉強した際のメモを
まとめていきます!
はじめに
Amazon S3を簡単にまとめると
インターネット用のストレージサービス。いつでもネットワークに接続できれば容量に関係なくデータを保存したり取得したりすることができる。
今回はこの内容についてまとめてみました。
AWS クラウドサービス活用資料集※ウェビナー受講にはFlashの導入が必要になります
ウェビナー受講メモ
■Amazon S3(Amazon Simple Storage Service)
・AWSストレージサービスの中のオブジェクトストレージサービスのひとつ
◦オブジェクトストレージはOSや、ファイルシステムに依存することなく、データの格納や格納したオブジェクトへのアクセスが可能
◦HTTPを使ってKeyとオブジェクトを使ってデータを扱っていこうというコンセプト
・ユーザはデータを安全に、どこからでも、容量制限なく保存可能
・最大限のスケーラビリティを利用者やデベロッパーに提供
■S3の特徴
・容量無制限(1ファイル最大5TBまで)
・高い耐久性(データを失わない確率)→99,999999999%
◦イレブンナインと呼ばれる
◦リージョン内のデータセンターの複数個所で自動複製される
◦ユーザがデータを格納するリージョンを指定する(複製の際、勝手に他のリージョンで複製はしない)
◦3拠点でデータを同期するために結果整合性モデルが採用されている
(結果整合性=更新はそのうち全体に反映される。最終的にはデータが最新の情報に更新されるということ)
・スケーラブルで安定した性能
◦データ容量に依存しない性能(ユーザがサーバ台数、媒体本数やRAID、RAIDコントローラを考える必要がない)
・APIまたはAWS CLIにてプログラムから操作が可能
・ストレージクラス

■S3の用語
・バケット
◦データの保存場所
◦デフォルト100個まで作成可能
◦S3の中で一番大きなフォルダ
・オブジェクト
◦データ(S3に格納されるファイルでURLが付与される)
◦バケット内オブジェクト数は無制限(1オブジェクトサイズは0-5TBまで)
◦データとメタデータで構成される
・キー
◦オブジェクトの格納URLパス
◦バケット、キー、オブジェクトで一意に特定される
・メタデータ
◦オブジェクトに付随する属性の情報(システム定義メタデータ、ユーザ定義メタデータなど)
◦オブジェクトをコピーした場合はメタデータもコピーされる
・リージョン
◦バケットを配置するAWSのロケーション
◦S3のバケットをどのリージョンに作成するのかを指定できる
・アクセスコントロールリスト(ACL)
◦バケットやオブジェクトのアクセス管理

■クロスリージョンレプリケーション
・異なるリージョン間のS3バケットオブジェクトのレプリケーションを実施
・バケットに対するオブジェクトの作成、更新、削除をトリガーに非同期でレプリケーションが実行
◦対象元バケットはバージョニングの機能を有効にする必要がある
◦バケットはそれぞれ異なるリージョンでなければならない
◦双方向レプリケーションも可能
◦レプリケーション時は、リージョン間データ転送費用が発生
■バージョニング機能
・ユーザやアプリケーションの誤操作による削除対策に有効
◦バケットに対して設定されるもの
◦バージョン保管されている任意のオブジェクトを参照可能
◦バージョニングにより保管されているオブジェクト分も課金される
◦ライフサイクル管理と連携し、保存期間(有効期限)も指定可能
◦バケットを削除したい場合は、古いバージョンのオブジェクトも削除する必要がある
■ライフサイクル管理
・バケット内のオブジェクトに対してストレージクラスの変更や削除処理に関する自動化
◦バケット全体もしくはPrefixに対して、オブジェクトの更新日をベースに日単位での指定が可能
(Prefix=日本語でいう接頭語、データの名称の頭につける文字列のこと)
◦Lifecycleを利用してIAに移動できるのは128KB以上のオブジェクトのみ、他はIAに移動されない
◦各クラス間の移動や削除の日程をそれぞれ指定した組み合わせも可能
◦マルチアップロード処理で完了せず残った分割ファイルの削除にも対応
◦MFA delete が有効なバケットにはライフサイクル設定は不可
例:オブジェクト作成後1週間後に削除する設定が可能など
例:S3(Standard)作成保存→14日後にS3(Standard-IA)へ→7日後にGlacierへ→7日後に削除
※Glacier→使ってないけど捨てられないデータはここに保管しておこうという場所
■Amazon S3 Transfer Acceleration
・最適化されたAWSのネットワークを経由して高速にAmazon S3とのデータ転送を実現している
・利用者を自動的に最短のエッジネットワークに誘導
・S3 Bucketに対してAccelerationを有効化
◦S3へのアクセスエンドポイントを変更するだけで利用可能
◦Acceleration有効後、転送速度が高速化されるまでに最大30分かかる場合がある
◦バケット名はピリオド( . )が含まれない名前にする必要がある
◦IPv6 (dualstack)エンドポイントも指定可能
• 利用している端末からの無料スピード測定ツールも提供されている
■オブジェクトの共有 Pre-signed Object URL(署名付きURL)
・S3上のプライベートなオブジェクトに対して一定時間アクセスを許可
・任意のユーザへの一時的なオブジェクト共有
・任意のユーザからの一時的なS3へのオブジェクトアップロード権限の付与
■静的なWebサイトをS3のみでホスティング可能
・バケット単位で指定
◦Management Consoleで設定可能
◦パブリックアクセスを許可するため別途バケットポリシーで全ユーザにGET権限を付与
■CloudFrontとの連携
・WebサーバとしてS3を利用する場合は、CloudFront経由で配信することを推奨している
(CloudFrontを利用することで、より高速にコンテンツの配信ができるため)
・バケットポリシーを利用してCloudFrontからのHTTP/HTTPSリクエストのみを許可することも可能
・Amazon S3 コンテンツへのアクセスにユーザーが (Amazon S3 URL ではなく) CloudFront URL を使用することを要求できる。
■VPC Endpoint
・VPC内のPrivate Subnet上で稼働するサービスからNAT GatewayやNATインスタンを経由せずに直接S3とセキュアに通信させることが可能
・通信可能なのは同一リージョンのS3のみ
・VPC管理画面のEndpointで作成し、S3と通信したいSubnetのルートテーブルに追加する
・Endpoint作成時にアクセスポリシーを定義し、通信可能なBucketや通信元のVPCの指定が可能 (バケットポリシーやIAMポリシーを利用したSource IPやVPC CIDRによる制限は利用不可)
・別のVPCやSubnetを跨いだ直接のEndpointの利用はできない
■暗号化によるデータ保護
・保管時(Amazon S3 データセンター内のディスクに格納されているとき)のデータを暗号化して保護するもの
・サーバサイド暗号化
◦AWSのサーバリソースを利用して格納データの暗号化処理を実施
◦暗号化種別
(SSE-S3 : AWSが管理する鍵を利用して暗号化)
(SSE-KMS:Key Management Service(KMS)の鍵を利用して暗号化)
(SSE-C:ユーザが提供した鍵を利用して暗号化 ※AWSで鍵は管理しない)
・クライアントサイド暗号化
◦暗号化プロセスはユーザ管理
◦クライアント側で暗号化したデータをS3にアップロード
◦暗号化種別
・AWS KMSで管理されたカスタマーキーを利用して暗号化
・クライアントが管理するマスターキーを利用して暗号化
■Amazon CloudWatchによるメトリクス管理
①バケットに対するストレージメトリクス (日単位)
・バケット単位および、Storage Type(Glacierを除く)ごとにメトリクスを把握する
・1日間隔でのレポート、状況把握(追加料金なし)
②オブジェクトに対するリクエストメトリクス (分単位)
・タグやプレフィックスの指定にて細かい粒度での把握も可能
・1分間隔でのメトリクスで、通常のCloudWatchの料金
■アクセス管理
デフォルトではS3のバケットやオブジェクトなどはすべてプライベートアクセス権限のみに設定
・ユーザポリシー
◦全AWSサービス共通のIAMとよばれる管理者権限の権限管理のしくみ
◦ユーザにたいしての権限制限
・バケットポリシー
◦S3バケットごとにアクセス権限を指定できる
◦S3バケットに対しての制限
・アクセスコントロールリスト(ACL)
◦バケット、おもにオブジェクトに対する権限管理のしくみ
◦バケットとオブジェクトのオーナーが違ったりする場合に使ったりする
(例:違うアカウントが所有するバケット上のオブジェクトのアクセス許可を管理する場合にACLが有用
■パフォーマンスの最適化
①大きなサイズのファイルを快適にダウンロードアップロード
・GETリクエストは、RANGE GETを活用することで、マルチスレッド環境では高速にダウンロードが可能
◦マルチパードアップロード時と同じチャンクサイズを利用する
・マルチパートアップロードの活用によるアップロード(PUT)オペレーションの高速化
◦チャンクサイズと並列コネクション数のバランスが重要
• 帯域が太い場合は20MB-50MBチャンクサイズから調整
• モバイルや帯域が細い場合は10MB程度から調整
②目安として100MB以上のファイルのアップロードの際はマルチパートアップロード機能を推奨
・S3にアップロードする際に、ファイルを複数のチャンクに分割して並列アップロードを実施
・ファイルが100MBを超える場合、利用することを推奨
・各チャンクは5GB以下に設定(5MBから設定可能)
・全てのチャンクがアップロードされるとS3側で結合される
・Multipart Uploadを利用することで単一オブジェクトに5TBまで格納可能
・各SDKにてMultipart Uploadの機能は実装済みAWS CLIの場合は、ファイルサイズを元に自動的に判別
• PUT処理を並列化することでのスループット向上を期待(広帯域ネットワークが重要になる)
③1 秒あたり 100 個以上のリクエストを定常的に処理している場合
・定常的にS3バケットへのPUT/LIST/DELETEリクエストが100RPSを超える、もしくはGETリクエストが300RPSを超える場合、キー名先頭部分の文字列をランダムにすることを推奨
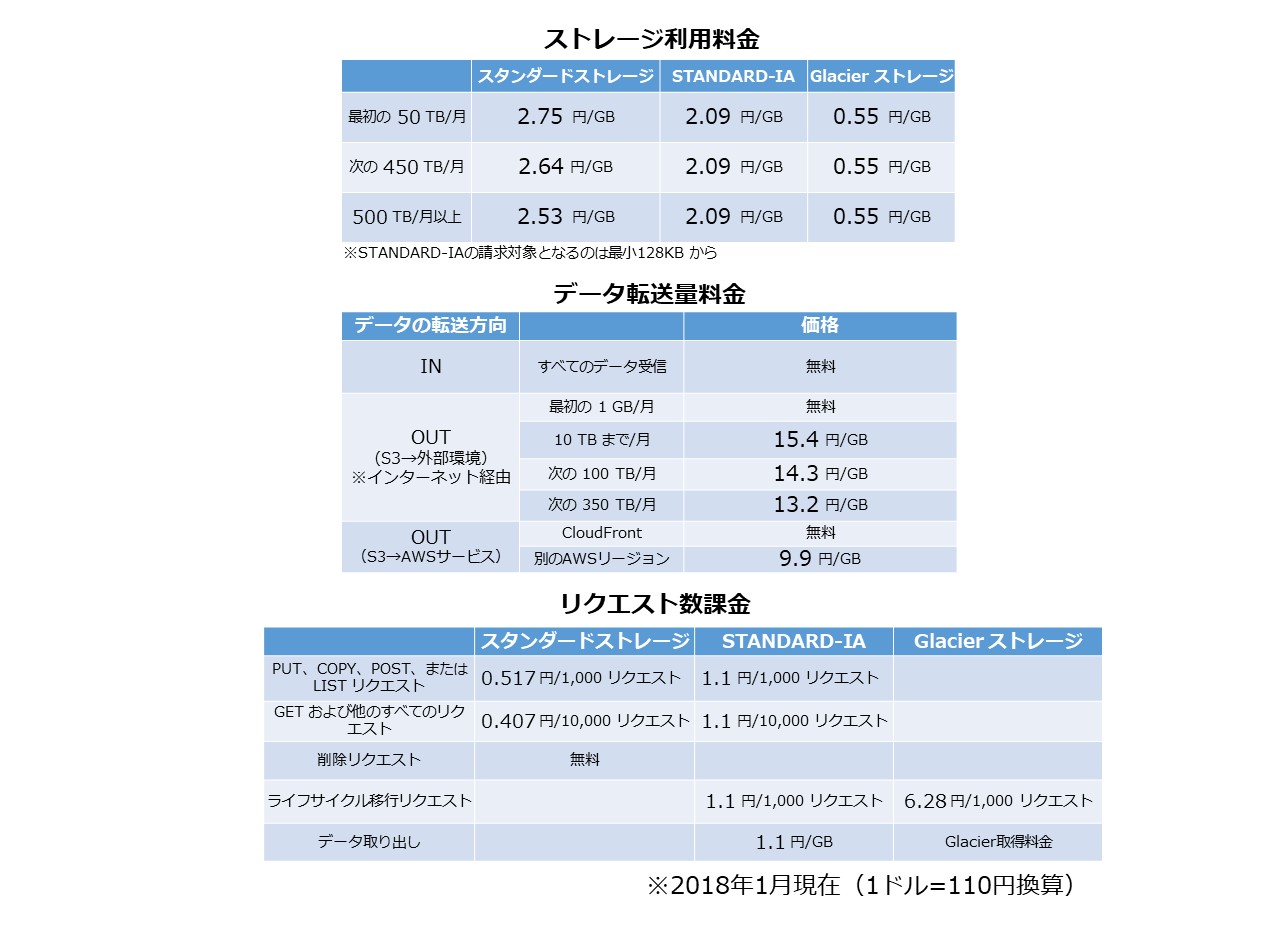
■ご利用料金【東京リージョン】(2018年1月現在)
課金対象は主に3つ
① ストレージ容量
② リクエスト数
③データ転送量
他にストレージマネジメント料金とS3 Transfer Acceleration料金が発生する
おわりに
前回のウェビナー受講メモに引き続き、今回はAmazon S3メモを整理しました。
Simple Storage Serviceなのになんていろいろな機能が用意されているんだ、と驚きました。ひとつのサービスを取ってみてもこれだけ充実した機能があることはすごいことだと思います。
本記事が自分のようにこれからAWSの勉強を開始される方の参考になれば何よりです。
次回はAmazon ELBについてまとめていきたいと思います。
お楽しみに!
