こんにちは! JQです。
前回は『Amazon EMR編~ElasticMapReduceの使い方パート①~』ということで、EMRを利用する準備までをお話しました。
今回も『Amazon EMR編~ElasticMapReduceの使い方パート②~』と題して、引き続きEMRの使い方に関してお話していきたいと思います。
前回のパート①でS3バケットやスクリプトの準備が完了している為、今回はJobFlowの立ち上げから試していきます。
Job Flowの作成
1. EMRの画面に移動します。
「Create New Job Flow」をクリックして作成していきます。
JobFlowの設定
2.「Job Flow Name」にはそのまま「My Job Flow」で「Hadoop Version」はデフォルトを指定します。
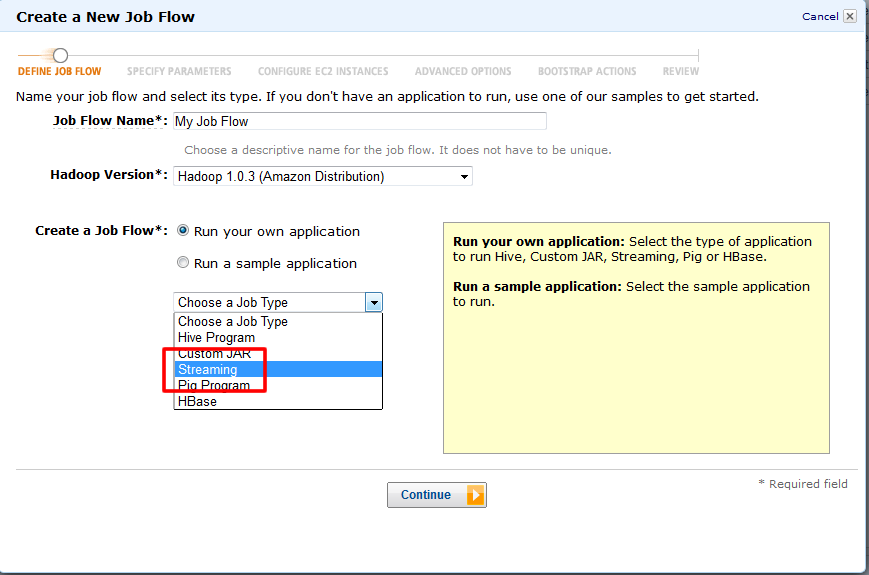
3.「Create a Job Flow」では「Run your own application.」で「JobType」を「Streaming」に指定します。
データとプログラムの設定
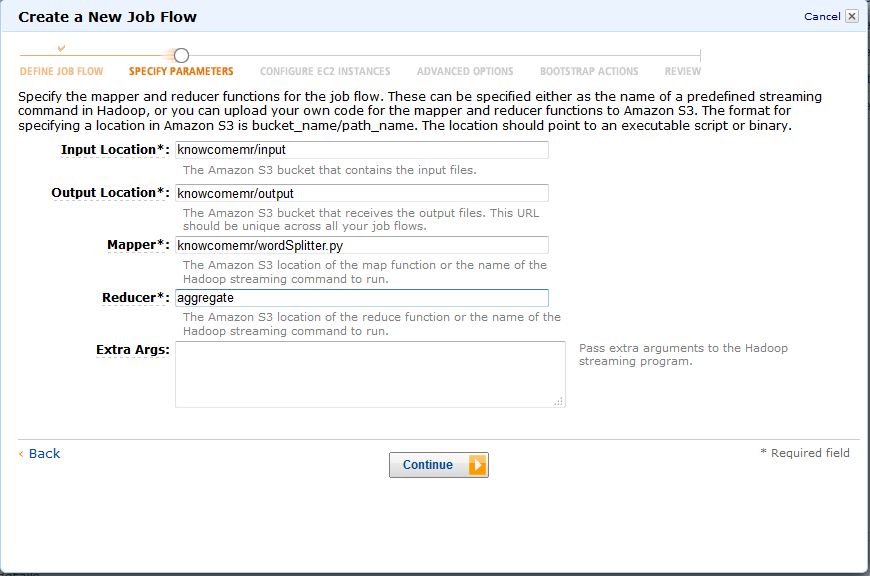
今回は以下を入力していきます。
4. Input Location: 作成したS3バケットのInputフォルダを指定します。
5. Output Location: 作成したS3バケットのOutputフォルダを指定します。
6.Mapper: アップロードしたwordSplitter.pyのパスを指定します。
7. Reducer: Hadoopの「aggregate」クラスを指定します
8. Extra Args: 空白にします。
インスタンス設定
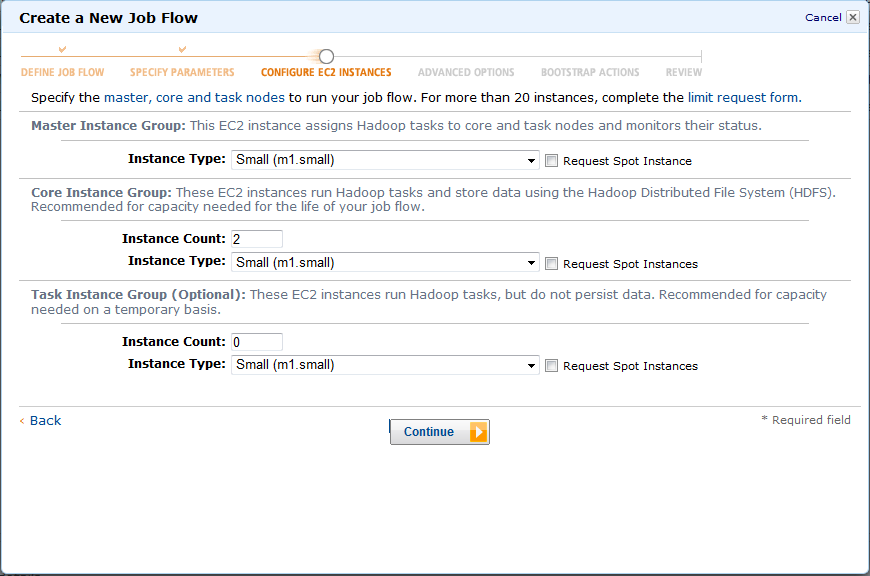
9. インスタンス数やインスタンスタイプ等はデフォルトのままにします。
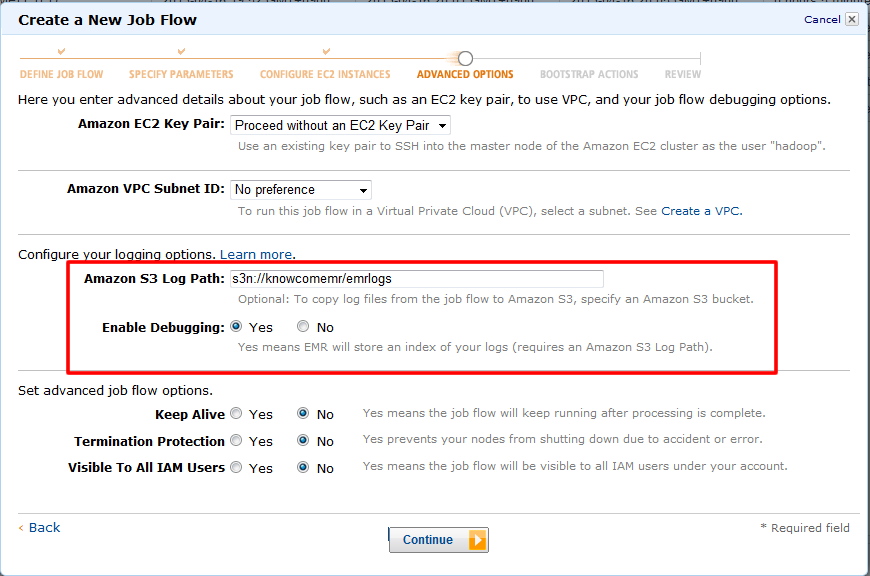
デバッグ設定
10. 今回はサンプルスクリプトを動かすだけなので、
デバッグとログファイルの指定場所だけを変更して進みます。
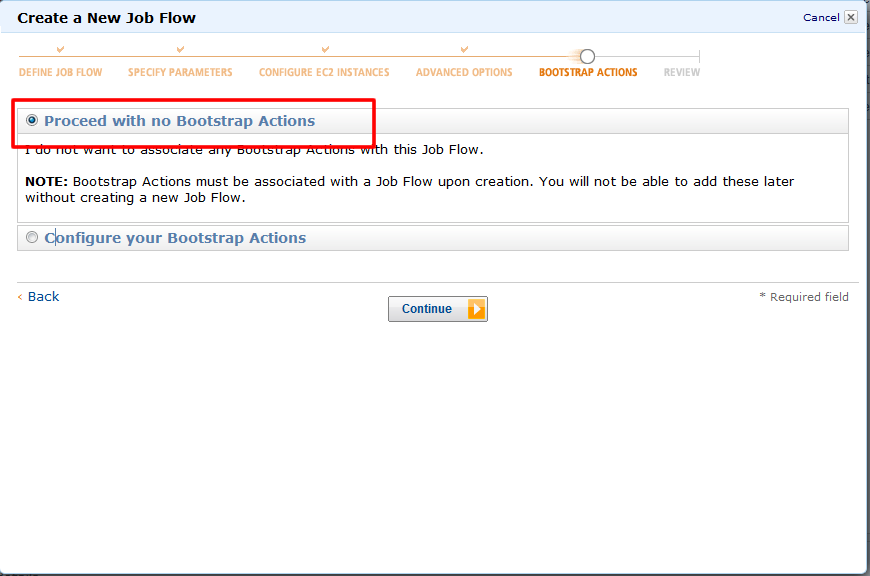
Bootstrap設定
11. 実行開始時の動作に関してもデフォルトで進みます。
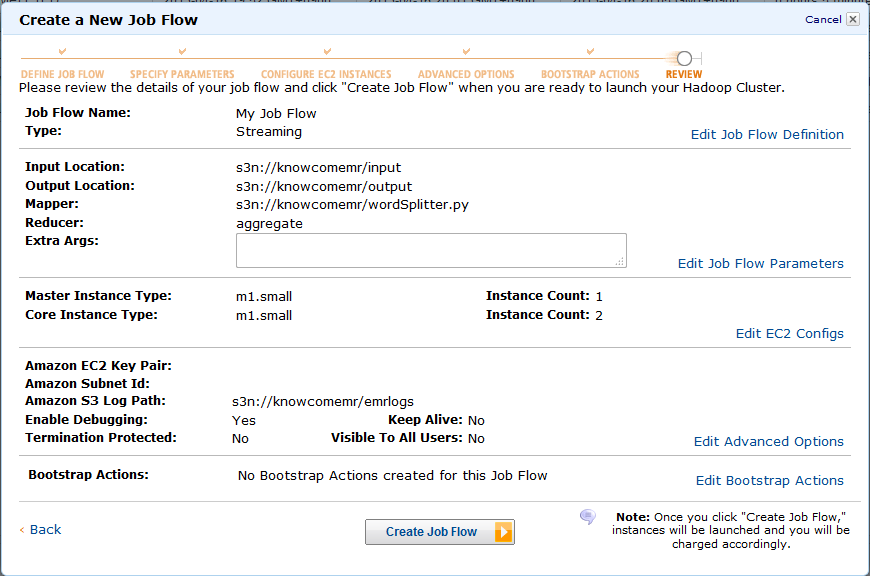
12. 確認後、問題なければ起動してみましょう!
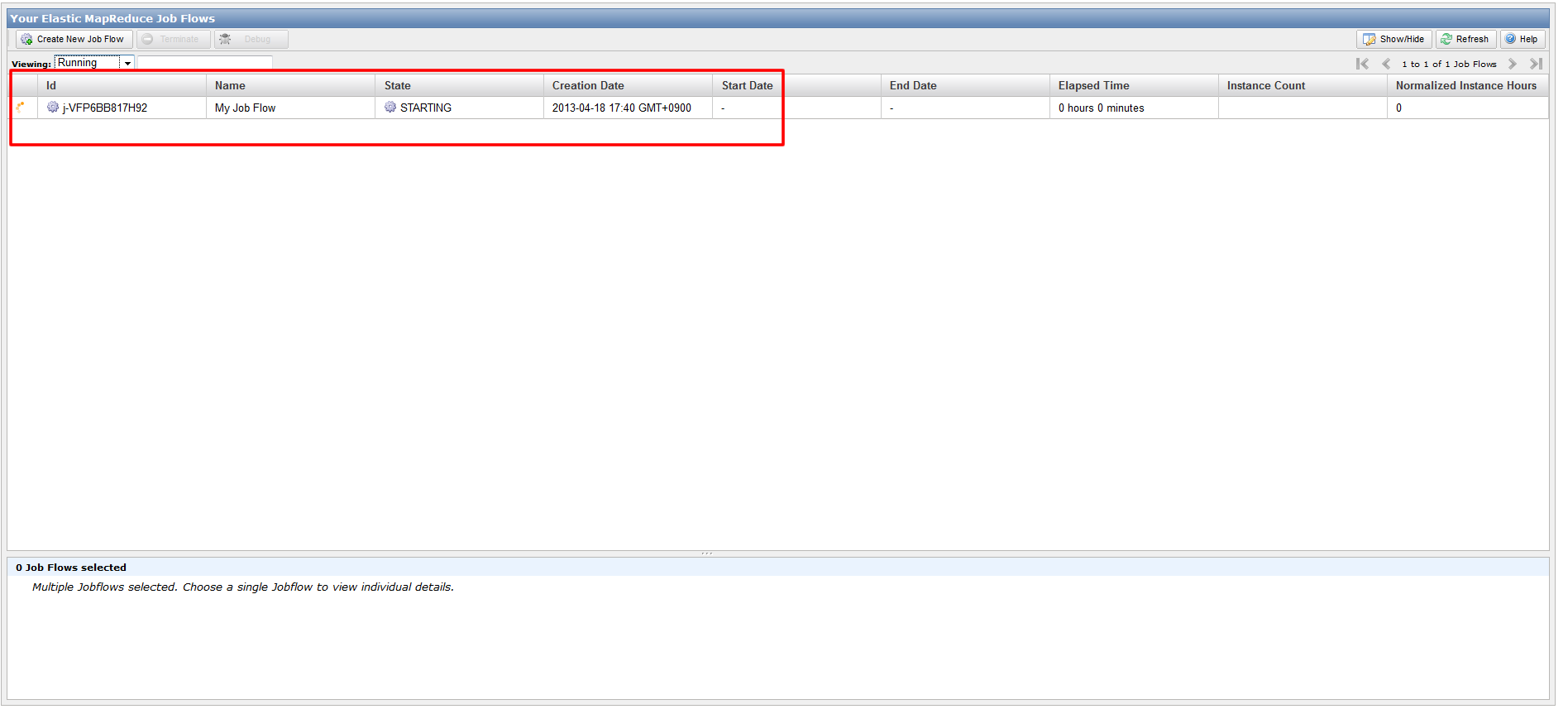
いかがでしたでしょうか?
次回も『Amazon EMR編~ElasticMapReduceの使い方パート③~』と題して、実際に出力された結果の確認を行いたいと思います。
お楽しみに!
