渡邊です。
Amazon SageMaker(以下、SageMaker)が東京リージョンで利用可能となりました。
弊社は以前からSageMakerに注目しており、今後、日本でも利用が広がることを期待しております。
今回は、SageMakerのビルトインアルゴリズム(※)の1つ、『Random Cut Forest』(以下、RCF)を実行してみたいと思います。
※ビルトインアルゴリズムとは?
SageMakerのノートブックインスタンスには、あらかじめ複数のサンプルノートブックが用意されています。それらのノートブックには、機械学習でよく用いられるアルゴリズムのサンプルプログラムが実装されています。これらを利用することで、機械学習をすぐにでも実行することが出来ます。
2018年6月21日現在、用意されているアルゴリズムは次の通りです。
・Linear Learner
・Factorization Machines
・XGBoost Algorithm
・Image Classification
・Sequence2Sequence
・K-Means
・Principal Component Analysis (PCA)
・Latent Dirichlet Allocation (LDA)
・Neural Topic Model (NTM)
・DeepAR Forecasting
・BlazingText
・Random Cut Forest
ノートブック作成
ノートブックインスタンスを作成します。ステータスが『InService』になったら、アクションの『オープン』をクリックします。

Jupyter notebookの画面が開きます。『SageMaker Examples』タブをクリックします。

『Introduction to Amazon algorithms』をクリックします。
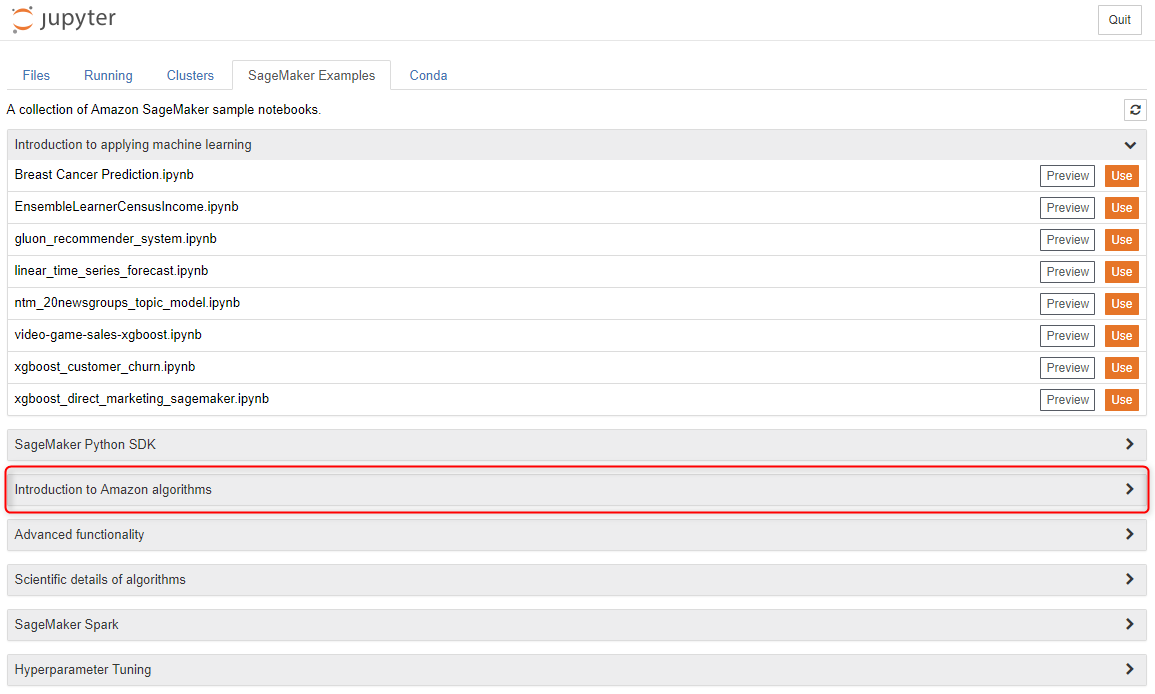
『random_cut_forest.ipynb』の『Use』ボタンをクリックします。
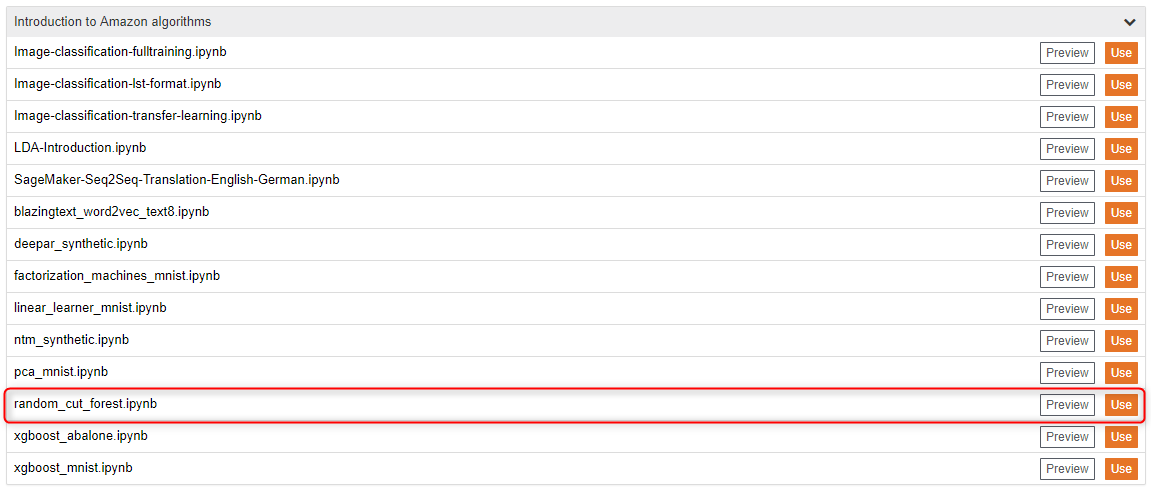
『Create copy』ボタンをクリックします。
RCFのノートブックが開きます。

先程の『Create copy』で作成されたフォルダとノートブックの所在は次の通りです(フォルダ名の末尾に、作成年月日がYYYY-MM-DD形式で付加されます)。


Random Cut Forestアルゴリズム実行
RCFを実行していきます。
まずは、使用するS3バケット名を入力します。必要に応じて、プレフィックスも入力します(今回はデフォルトのままとします)。
このノートブックで編集が必要なのはこのセルだけですが、今回は他のセルも編集して実行します。

ニューヨーク市のタクシー利用者数、6 か月間分で構成されるサンプルデータセット(CSV形式)をダウンロードします。

ダウンロードしたサンプルデータセットは、ノートブックと同じフォルダに格納されます。

サンプルデータセットの先頭5行を表示させます。

サンプルデータセットをプロットしてみます。
横軸6000付近にピークが見られます。

ピーク付近にズームして見るため、横軸5500から6500までの範囲をプロットしてみます。
通常時のデータの様子もより詳細に見て取れます。

RCFの学習は、他の多くのSageMakerアルゴリズムと同様、RecordIO Protobuf形式にエンコーディングされたデータで最もよく機能します。ここでは、CSV形式のサンプルデータセットをRecordIO Protobuf形式に変換し、S3バケットへ格納しています。
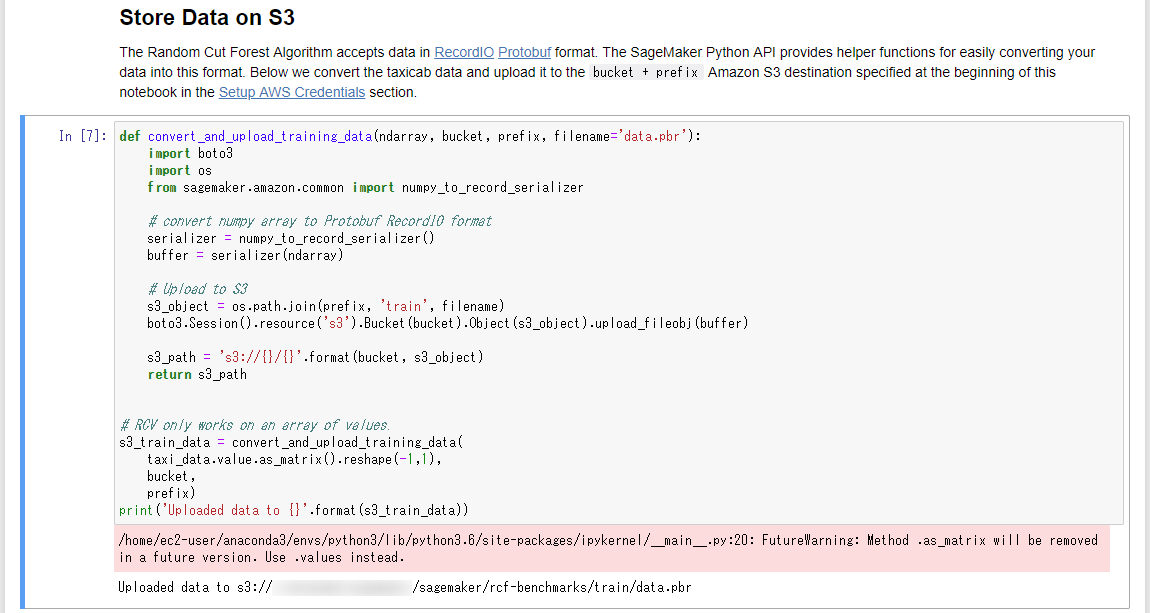
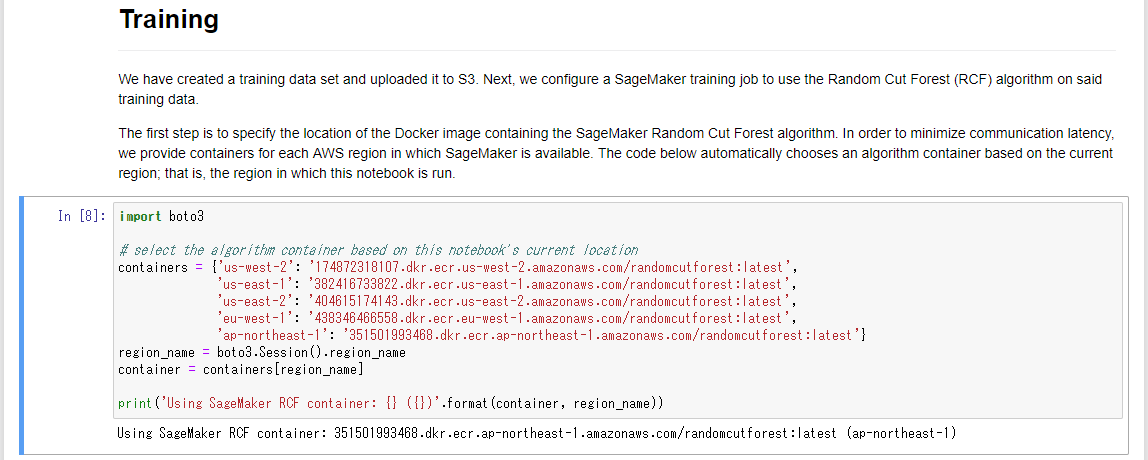
学習用Dockerコンテナイメージを設定します。このセルには、実行しているノートブックのリージョンから自動的に判定して設定されるようにプログラムが組まれています。
ハイパーパラメータの説明が記載されています。

今回は、学習用インスタンスのインスタンスタイプを、デフォルトの『ml.m4.xlarge』から『ml.t2.medium』に変更してみます。また、処理時間を計測して表示する処理を追加しました。

すると、下記のようなエラーメッセージが表示されます。

学習用インスタンスのインスタンスタイプに『ml.t2.medium』は指定出来ないようです。
指定出来るインスタンスタイプを下表にまとめました。
| 項番 | インスタンスタイプ | vCPU | GPU | メモリ (GiB) | GPU メモリ (GiB) | ネットワークパフォーマンス |
| スタンダード – 現行世代 | ||||||
| 1 | ml.m5.large | 2 | – | 8 | – | 高 |
| 2 | ml.m5.xlarge | 4 | – | 16 | – | 高 |
| 3 | ml.m5.2xlarge | 8 | – | 32 | – | 高 |
| 4 | ml.m5.4xlarge | 16 | – | 64 | – | 高 |
| 5 | ml.m5.12xlarge | 48 | – | 192 | – | 10 ギガビット |
| 6 | ml.m5.24xlarge | 96 | – | 384 | – | 25 ギガビット |
| 7 | ml.m4.xlarge | 4 | – | 16 | – | 高 |
| 8 | ml.m4.4xlarge | 16 | – | 64 | – | 高 |
| 9 | ml.m4.10xlarge | 40 | – | 160 | – | 10 ギガビット |
| 10 | ml.m4.16xlarge | 64 | – | 256 | – | 25 ギガビット |
| コンピューティング最適化 – 現行世代 | ||||||
| 11 | ml.c5.xlarge | 4 | – | 8 | – | 最大 10 Gbps |
| 12 | ml.c5.2xlarge | 8 | – | 16 | – | 最大 10 Gbps |
| 13 | ml.c5.4xlarge | 16 | – | 32 | – | 最大 10 Gbps |
| 14 | ml.c5.9xlarge | 36 | – | 72 | – | 10 ギガビット |
| 15 | ml.c5.18xlarge | 72 | – | 144 | – | 25 ギガビット |
| 16 | ml.c4.xlarge | 4 | – | 7.5 | – | 高 |
| 17 | ml.c4.2xlarge | 8 | – | 15 | – | 高 |
| 18 | ml.c4.4xlarge | 16 | – | 30 | – | 高 |
| 19 | ml.c4.8xlarge | 36 | – | 60 | – | 10 ギガビット |
| 加速コンピューティング – 現行世代 | ||||||
| 20 | ml.p3.2xlarge | 8 | 1xV100 | 61 | 16 | 最大 10 Gbps |
| 21 | ml.p3.8xlarge | 32 | 4xV100 | 244 | 64 | 10 ギガビット |
| 22 | ml.p3.16xlarge | 64 | 8xV100 | 488 | 128 | 25 ギガビット |
| 23 | ml.p2.xlarge | 4 | 1xK80 | 61 | 12 | 高 |
| 24 | ml.p2.8xlarge | 32 | 8xK80 | 488 | 96 | 10 ギガビット |
| 25 | ml.p2.16xlarge | 64 | 16xK80 | 732 | 192 | 25 ギガビット |
『ml.m5.large』を指定して再実行します。
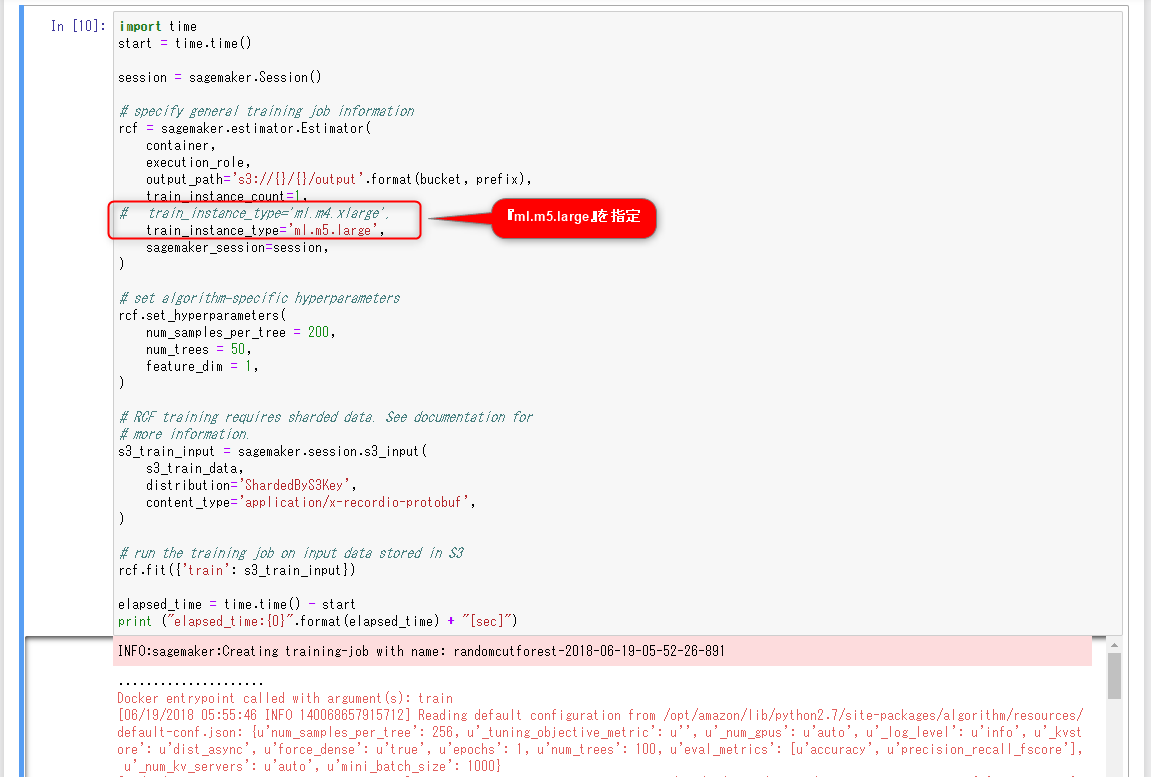
今回は、学習におよそ222秒(3分42秒)かかりました。

エンドポイントを作成します。説明に『ml.c5インスタンスタイプを推奨』とあるので、今回は『ml.c5.xlarge』を指定します。また、このセルでも処理時間を計測し、結果はおよそ330秒(5分30秒)でした。

学習済みモデルを使用して、異常スコア(異常の程度を表し、高ければ異常、低ければ通常と判断する)を算出します。

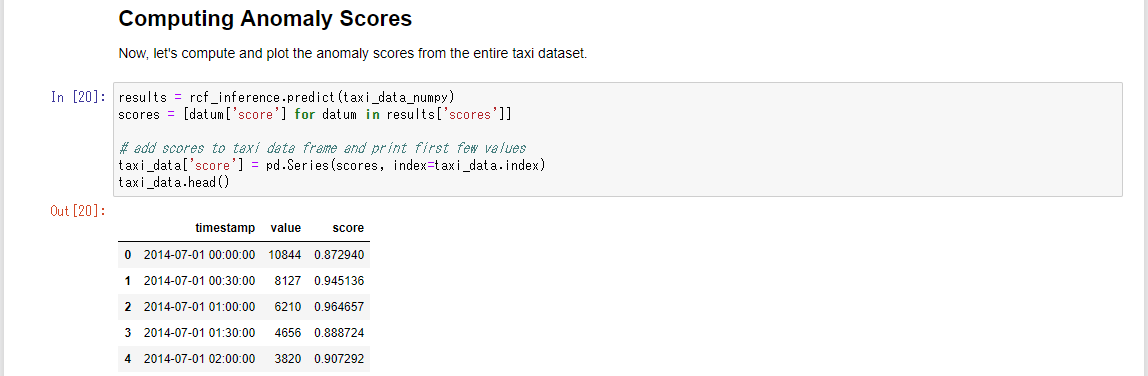
異常スコアをグラフにプロットしてみます。

ここでは、次の式を満たすデータを『異常』と判断する基準を採用します。
(異常スコア) > (異常スコアの平均値) + 3 × (異常スコアの標準偏差)

異常なデータポイントをプロットします。
既知の異常値をいくつか検出していることがわかります:
・ニューヨークシティマラソン( 2014-11-02; t = 5954 )
・大晦日( 2015-01-01; t = 8833 )
・暴風雪( 2015-01-27; t = 10090 )

最後にエンドポイントを削除します。

おわりに
以上、SageMakerのビルトインアルゴリズムの1つ、『Random Cut Forest』を、一部「処理時間の計測」や「インスタンスタイプの変更」をしながら実行してみました。
今回はサンプルデータセットを使用しましたが、これを別のデータセットに変更するなど、このノートブックをベースにカスタマイズすれば、比較的容易に『Random Cut Forest』による異常検知を導入出来る筈です。
最後までご覧頂きありがとうございました。
参考リンク
[1] 機械学習モデルとアルゴリズム | AWS での Amazon SageMaker
https://aws.amazon.com/jp/sagemaker/
[2] Amazon SageMaker ML インスタンスタイプ
https://aws.amazon.com/jp/sagemaker/pricing/instance-types/
[3] Algorithms Provided by Amazon SageMaker: Common Parameters
https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-algo-docker-registry-paths.html
[4] 20180308 AWS Black Belt Online Seminar Amazon SageMaker
https://www.slideshare.net/AmazonWebServicesJapan/20180308-aws-black-belt-online-seminar-amazon-sagemaker-90045719
[5] SageMaker | Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/category/artificial-intelligence/sagemaker/
[6] 異常検出にビルトイン Amazon SageMaker Random Cut Forest アルゴリズムを使用する | Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/use-the-built-in-amazon-sagemaker-random-cut-forest-algorithm-for-anomaly-detection/
[7] ランダムカットフォレスト
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/randomcutforest.html
[8] Robust Random Cut Forest Based Anomaly Detection on Streams
https://www.semanticscholar.org/paper/Robust-Random-Cut-Forest-Based-Anomaly-Detection-on-Guha-Mishra/8bba52e9797f2e2cc9a823dbd12514d02f29c8b9
[9] AWS SagemakerでJupyterを使ったり、独自機能を使う
http://catindog.hatenablog.com/entry/2018/05/05/194516
[10] Amazon SageMaker いじってみた1
http://recipe.kc-cloud.jp/archives/10841
[11] Amazon SageMaker いじってみた2
http://recipe.kc-cloud.jp/archives/10921
