渡邊です。
データ分析や機械学習などにおいて、単一または複数のデータソースからデータを集約し、必要に応じて変換・加工した上で、データベースやデータウェアハウスなどに格納することがあります。これをETL(Extract, Transform and Load)処理と呼びます。
AWS GlueはこのETL処理を『分散処理』かつ『サーバレス』で提供するサービスです。
今回はこのAWS Glueを動かすこと自体を目的として、なるべく簡単な構成と処理内容で試してみようと思います。
構成
構築する構成は下図の通りです。
S3バケットからデータをインプットし、同じS3バケットへアウトプットします。
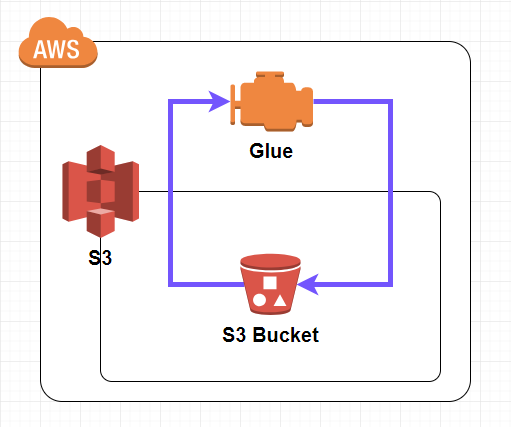
全体の流れ
今回の構築は第1回・第2回に分けて、次のように進めます。
第1回
・サンプルデータの準備
・S3バケットとフォルダの作成
・Databaseの作成
・Crawlerの作成と実行
・Tableの確認
第2回
・IAMの変更
・Jobの作成と実行
・結果の確認
サンプルデータの準備
機械学習でよく用いられるアヤメのデータを今回のサンプルデータとします(※1、※2)。
下記URLで公開されています。
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.names
先頭行に列名を付加して、下記のようにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
sepal length in cm,sepal width in cm,petal length in cm,petal width in cm,class 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa (中略) 6.7,3.0,5.2,2.3,Iris-virginica 6.3,2.5,5.0,1.9,Iris-virginica 6.5,3.0,5.2,2.0,Iris-virginica 6.2,3.4,5.4,2.3,Iris-virginica 5.9,3.0,5.1,1.8,Iris-virginica |
※1:アヤメのデータをサンプルとするのは何故か?
→アヤメのデータでなければならない理由はありませんが、次の三点からこのデータを選びました。
・オープンデータであること →この記事をご覧になった方が、データ作成の手間無くすぐに、同じデータで、同じことが出来る
・データ量が小さい →ダウンロードや処理に時間がかからない
・CSV形式 →AWS Glueで扱えるデータ形式の中で恐らく最も広く知られている
※2:アヤメのデータで何をするのか?
→この構築では、AWS Glueを動かすこと自体を目的として、なるべく簡単に試すことにしました。従って、データの変換・加工も、『列の順番を変える』『特定の列を削除する』など、ごく簡単な内容にとどめました(第2回で実行します)。勿論、AWS Glueでは、Jobのスクリプト次第で、データの結合などのより高度な処理も実現出来ます。
S3バケットとフォルダの作成
S3バケットを作成し、『input』『output』『script』『temp』の4フォルダを作成します。

『input』フォルダにサンプルデータを格納します。

Databaseの作成
AWS Glueを選択します。
左ペインの『Database』を選択します。
『Add database』ボタンをクリックします。
Database名を入力して、『Create』ボタンをクリックします。
Databaseが作成されました。左ペインの『Crawlers』を選択します。
Crawlerの作成と実行
『Add crawler』ボタンをクリックします。
Crawler名を入力します。

『Inclue path』欄の横に表示されるフォルダマークをクリックします。
先程作成したS3バケットの『input』フォルダを選択します。
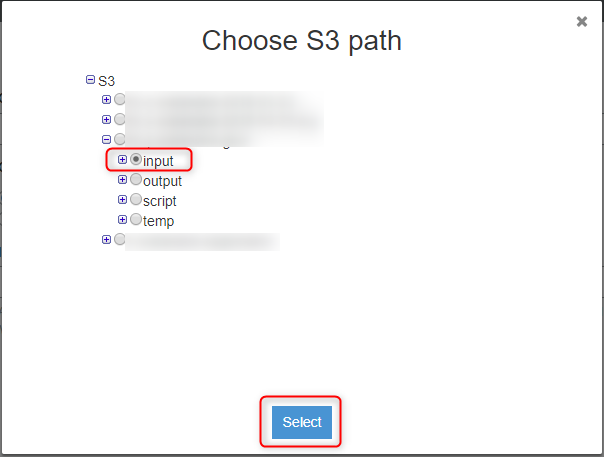
『Include path』の末尾に『/(スラッシュ)』を付けて、『Next』ボタンをクリックします。
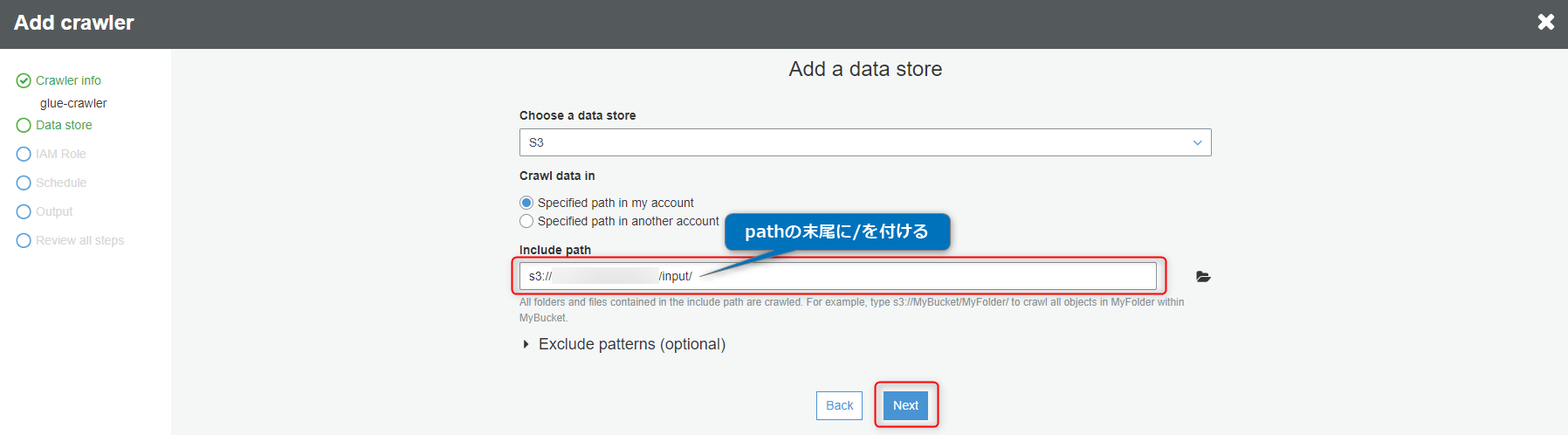
『Next』ボタンをクリックします。

作成するIAMロール名を入力して、『Next』ボタンをクリックします。
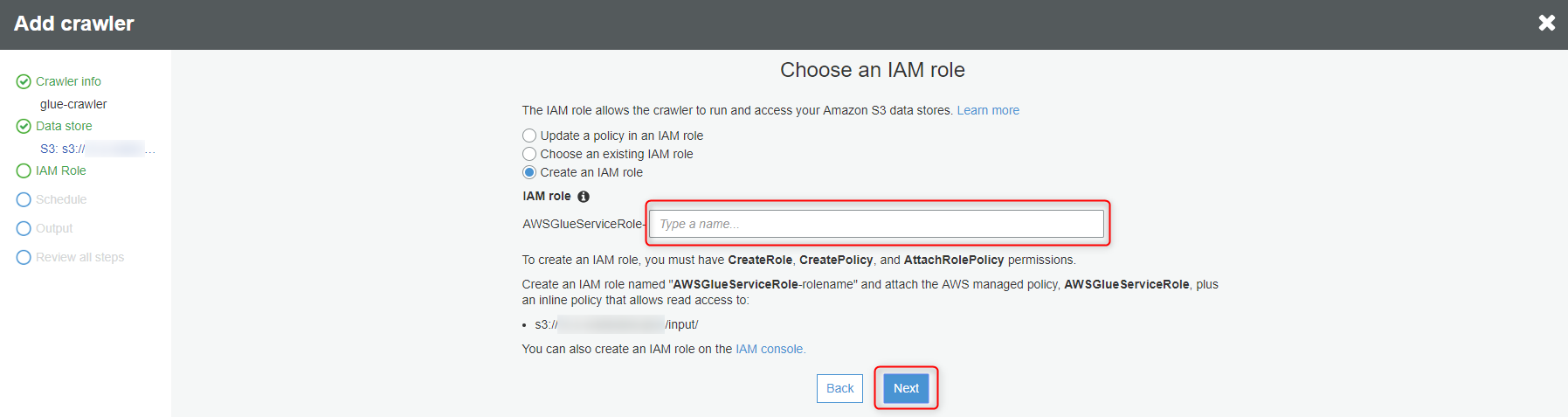
『Next』ボタンをクリックします。
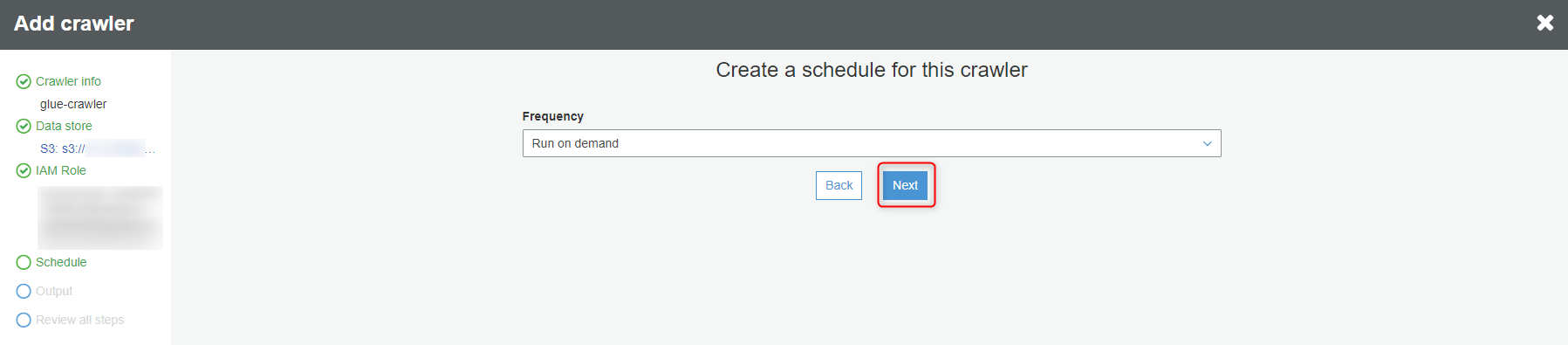
先程作成したDatabaseを選択して、『Next』ボタンをクリックします。
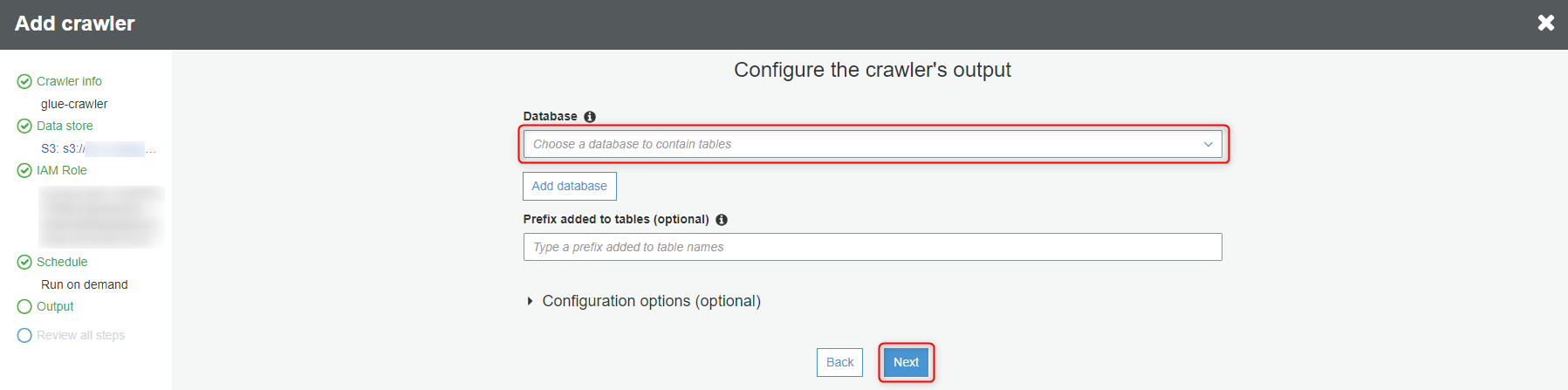
『Finish』ボタンをクリックします。
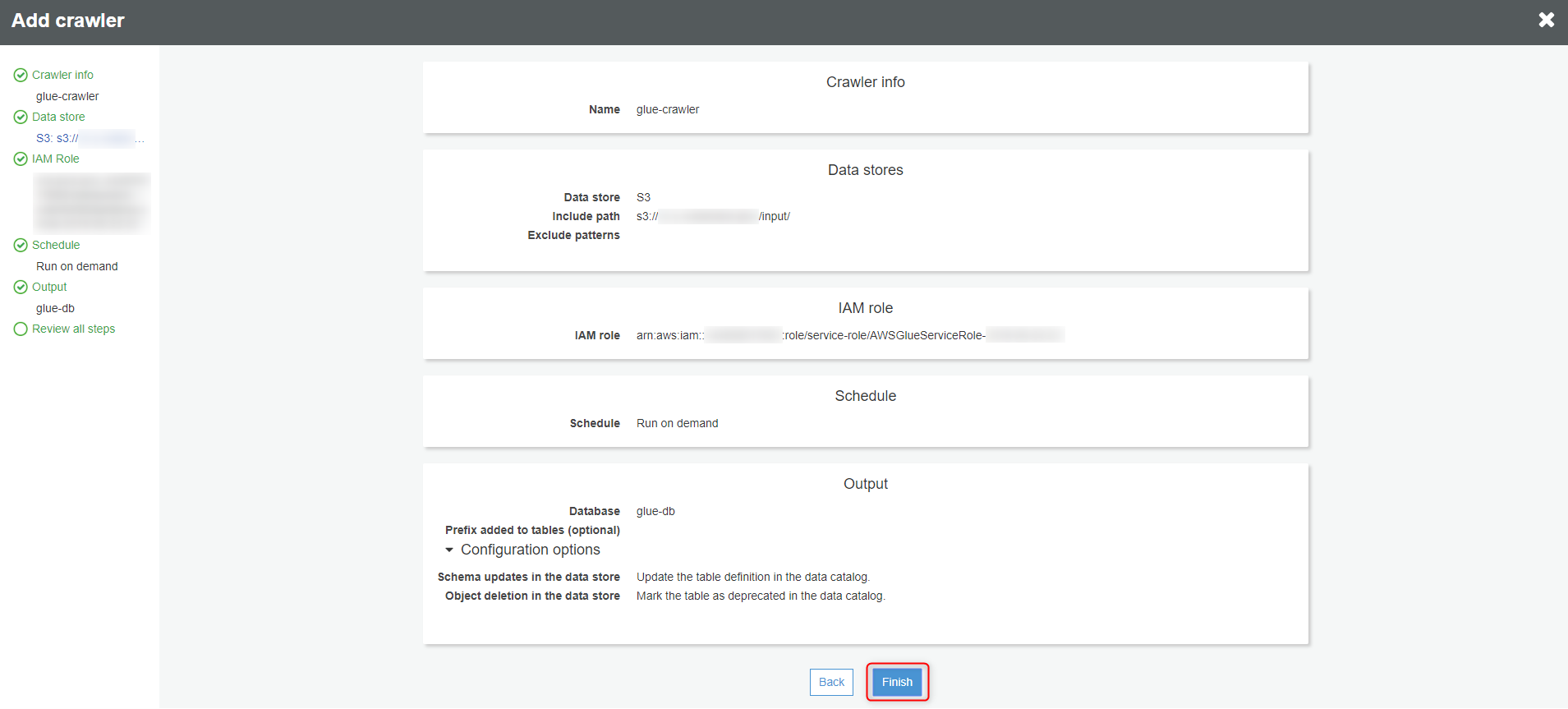
Crawlerが作成されました。作成したCrawlerのチェックボックスをチェックします。
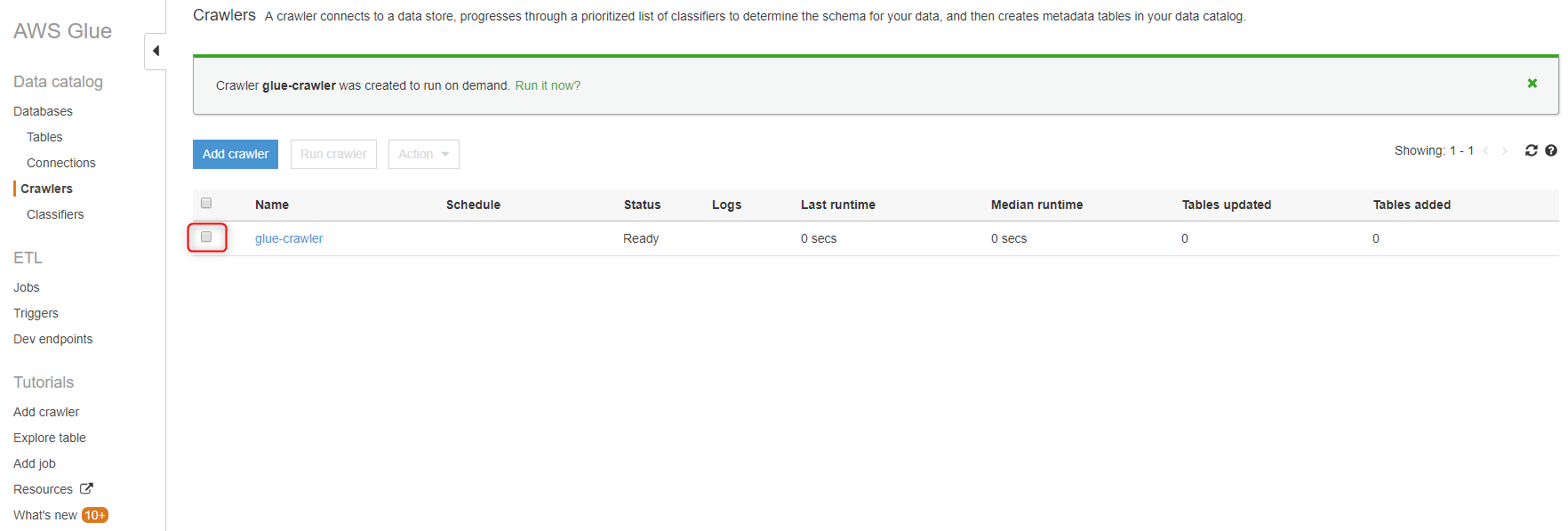
『Run crawler』ボタンをクリックします。

Crawlerが開始され、『Status』が『Starting』になります。

Crawlerが終了すると、『Status』に処理時間が表示されます。

Tableの確認
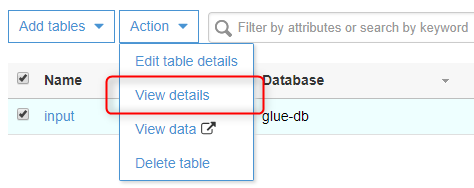
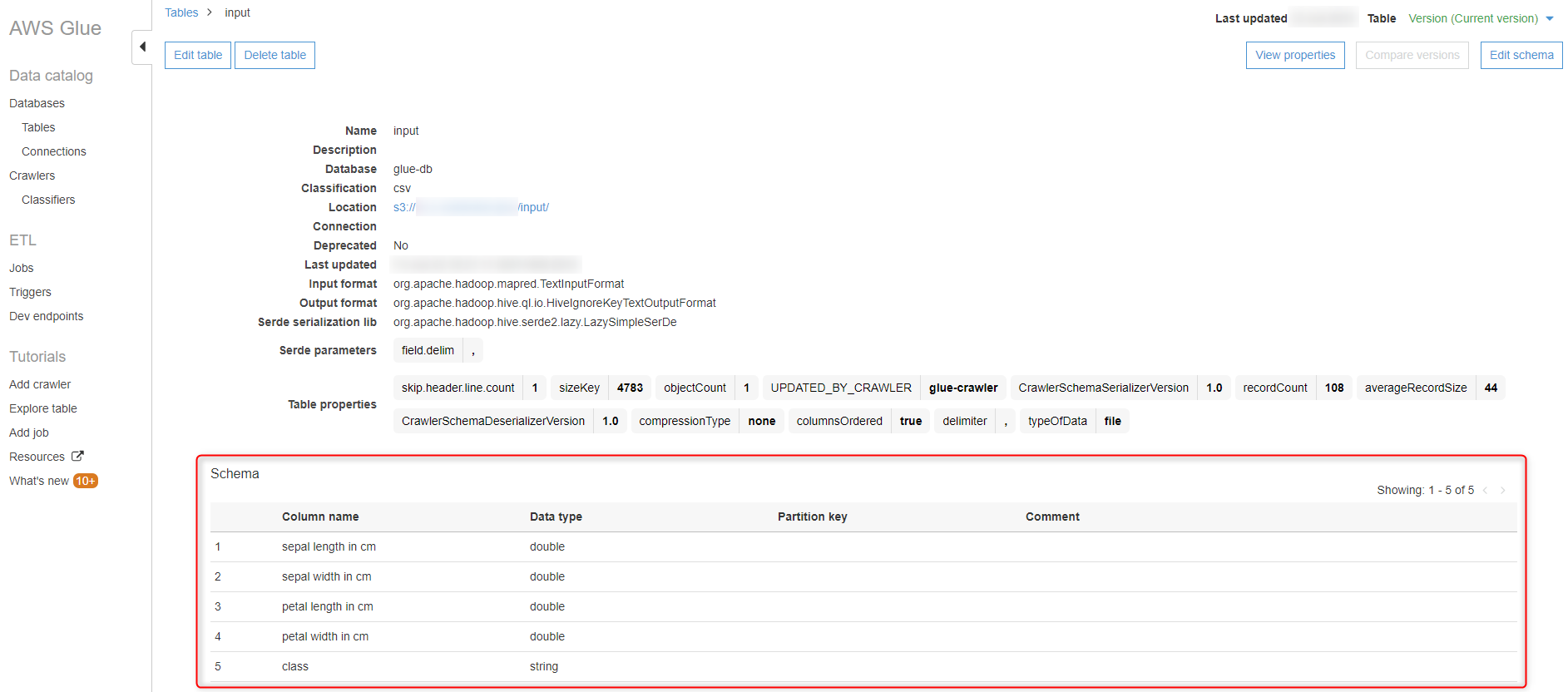
左ペインの『Tables』を選択し、作成されたTableのチェックボックスをチェックします。

『Action』から『View details』を選択します。
Tableの詳細が表示されます。『Schema』にデータの列名、データ型が表示されていることが確認出来ます。
まとめ
第1回はサンプルデータの準備から、データの列名や型(メタデータ)を取得するまでを実行しました。
第2回(http://recipe.kc-cloud.jp/archives/11753)へ続きます。
