こんにちは!Rookieです。
今回も、Amazon Glacier編です!
前回のレシピでは「Amazon Glacier編~Glacierとは?~」と題して、Amazon Glacierの概要について記述したかと思います。
今回のレシピでは、Amazon GlacierとAmazon S3との比較についてお話していきますが、その前にAmazon Glacierに関する情報をご紹介します!
Amazon Glacierにファイルをアップロードするなどの際は、AWS SDK等のツールを使用したプログラミングで行なう必要があります。
ですがプログラミングなしで、画面操作だけで簡単におこないたい!という場合もあるかと思います。
そういった場合に利用できるのが「FastGlacier」という製品です。
サードパーティ提供製品ではありますが、管理画面に従って操作をおこなうだけで簡単にファイルのアップロードなどを行なう事ができます。
このツールであれば、ボルトの作成やファイルのアップロードまで一括して画面操作でおこなうことができるので、Amazon Glacierでの作業がスムーズにおこなえそうですね!
※ FastGlacierページはこちら
さてここから本題に入りまして、今回はAmazon GlacierとAmazon S3との比較について簡単にまとめておきたいと思います!
前回のレシピ「Amazon Glacier編~Glacierとは?~」でも少しお話したかとは思いますが、Amazon Glacierは低頻度のアクセスを想定し、運用コストを最小限に抑えたバックアップおよびアーカイブストレージになります。
下記がAmazon GlacierとAmazon S3との簡単な比較表になります。
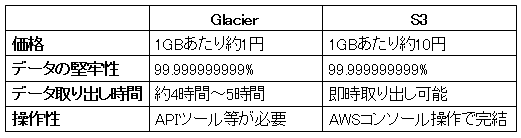
ご覧いただくと分かるようにデータの堅牢性などは全く同じで、Amazon Glacierではデータに対するアクセスに時間がかかる分、価格がAmazon S3の約10分の1となっています。
そのためAmazon Glacierは、大容量のデータを長期にわたって保存するといった場合などの用途に利用することが想定されています。
■Amazon S3との違い
Amazon GlacierがAmazon S3と大きく違う点は、
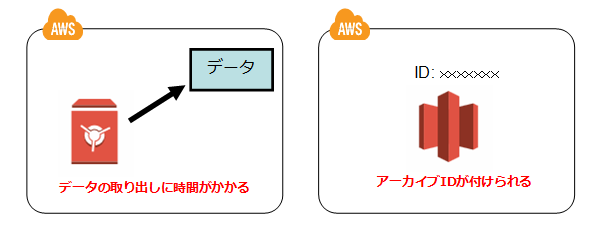
① ファイルの取り出しに時間がかかる(約4~5時間)
② 任意のファイル名を設定することは出来ず、ファイルごとにアーカイブID呼ばれるIDが付けられ、そのIDで管理される
という2点です。
①に関してですがGlacierでは、ファイルの取得のためにジョブと呼ばれるものを開始します。
ジョブというのはAmazon Glacierからデータを取り出す際のリクエストのことで、ジョブはキューに保存され順番に処理がおこなわれます。
ジョブがキューから取り出され実行されて完了すると、ファイルがダウンロード出来るようになります。このファイルがダウンロード出来るようになるまでの時間が約4~5時間と言われています。
更に②ですが、Amazon Glacierでのファイルのアップロード時にはアーカイブIDと呼ばれるIDが付けられます。
アップロード完了後、ファイルの取得・消去の際にはこのアーカイブIDを指定する必要があります。
このアーカイブIDによって、どのファイルと紐付けられているかを管理するということになります。
■Amazon S3との使い分け
上記に記述したようにGlacierの特徴を考えると、頻繁に出し入れが発生するファイルや、すぐにダウンロードできないと困るようなファイルはGlacierでの保存に向いていません。
このようなデータは今までどおりS3に保存するのが良いかと思います。
逆に一度保存すると出し入れがほとんど発生しないデータや、ダウンロードするのに時間がかかっても良いようなデータはGlacierでの保存に向いており、各種データのバックアップおよびアーカイブなどのデータの保存に最適です。
Glacier(氷河)という名前の通り、コールドデータを保存するのに適したストレージであることが分かります。
いかがでしたでしょうか?
Amazon Glacier・Amazon S3それぞれの用途を確認し、目的に合わせて利用することでストレージサービスとして有効に活用することができます。
是非、確認していただき効率の良いデータ運用をおこないましょう!
次回は「Amazon Glacier編~Glacierを使ってみよう!パート①~」と題して、Amazon Glacierにてファイルの保存をおこなうのに必要なボルトの作成をおこないたいと思います。
お楽しみに!
