こんにちは! JQです。
前回は『Amazon Redshift編~Redshiftをはじめてみよう!パート③~』ということで、SQL workbenchを利用して実際に接続するまでをお話しました。
今回は『Amazon Redshift編~Redshiftをはじめてみよう!パート④~』と題して、AWSのSampleDataを試してみたいと思います。
Tableの作成
1.下記のサンプルクエリーを実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); |
|
1 2 3 4 5 6 |
create table venue( venueid smallint not null distkey sortkey, venuename varchar(100), venuecity varchar(30), venuestate char(2), venueseats integer); |
|
1 2 3 4 5 |
create table category( catid smallint not null distkey sortkey, catgroup varchar(10), catname varchar(10), catdesc varchar(50)); |
|
1 2 3 4 5 6 7 8 9 |
create table date( dateid smallint not null distkey sortkey, caldate date not null, day character(3) not null, week smallint not null, month character(5) not null, qtr character(5) not null, year smallint not null, holiday boolean default('N')); |
|
1 2 3 4 5 6 7 |
create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); |
|
1 2 3 4 5 6 7 8 9 |
create table listing( listid integer not null distkey, sellerid integer not null, eventid integer not null, dateid smallint not null sortkey, numtickets smallint not null, priceperticket decimal(8,2), totalprice decimal(8,2), listtime timestamp); |
|
1 2 3 4 5 6 7 8 9 10 11 |
create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); |
2. パート③で設定したSQL workbenchで流し込みます。
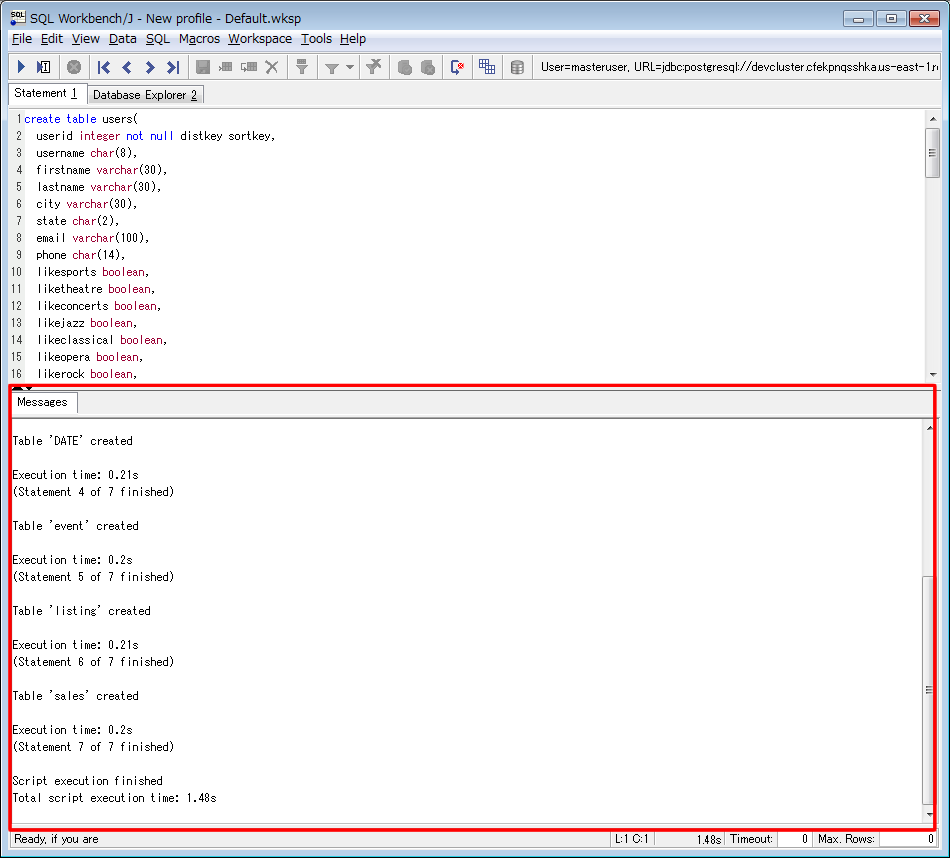
画面下部に実行結果が出力されます。
データアップロード
3. 公開されているサンプルデータをS3からコピーします。
下記のサンプルで必要箇所を書き換えて実行します。
|
1 2 3 4 5 6 7 8 9 |
copy users from 's3://<region-specific-bucket-name>/tickit/allusers_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|'; copy venue from 's3://<region-specific-bucket-name>/tickit/venue_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|'; copy category from 's3://<region-specific-bucket-name>/tickit/category_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|'; copy date from 's3://<region-specific-bucket-name>/tickit/date2008_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|'; copy event from 's3://<region-specific-bucket-name>/tickit/allevents_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS'; copy listing from 's3://<region-specific-bucket-name>/tickit/listings_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|'; copy sales from 's3://<region-specific-bucket-name>/tickit/sales_tab.txt'CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS'; |
※サンプルがあるS3のバケット
US East (Northern Virginia) awssampledb
US West (Oregon) awssampledbuswest2
EU (Ireland) awssampledbeuwest1
4. 今回はNorthern Virginia なので「awssampledb」バケットを指定します。
サンプルは大体16,17MBぐらいで大体4分弱でした。
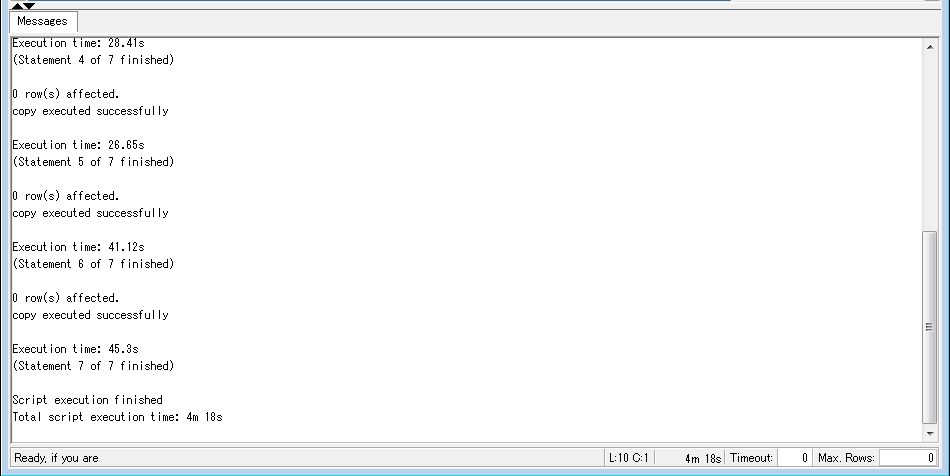
これでデータのインストールは完了です!
サンプルクエリーで確認
5. それでは実際にクエリーを叩いて確認してみましょう。
|
1 2 3 4 |
-- Get definition for the sales table. SELECT * FROM pg_table_def WHERE tablename = 'sales'; |
|
1 2 3 4 5 |
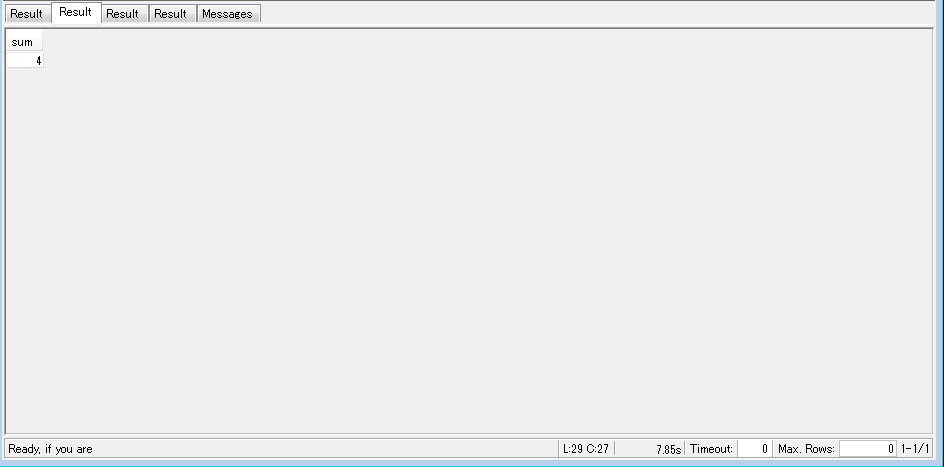
-- Find total sales on a given calendar date. SELECT sum(qtysold) FROM sales, date WHERE sales.dateid = date.dateid AND caldate = '2008-01-05'; |
|
1 2 3 4 5 6 7 8 |
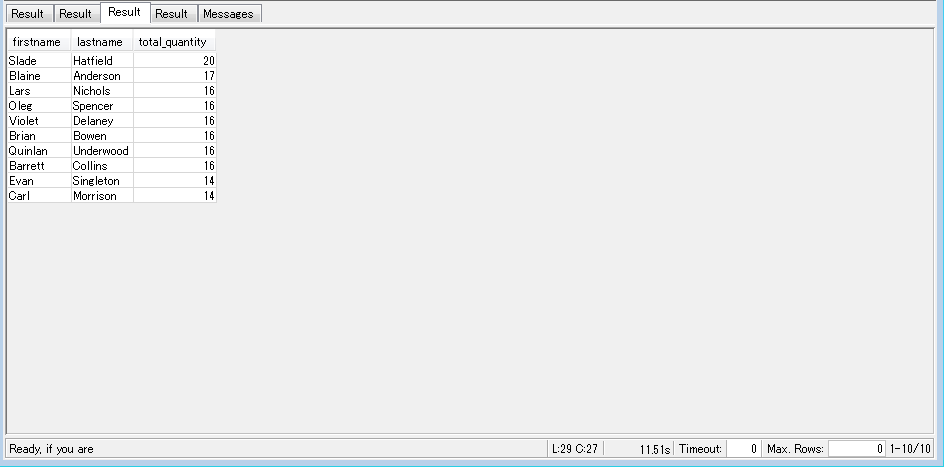
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; |
|
1 2 3 4 5 6 7 8 9 |
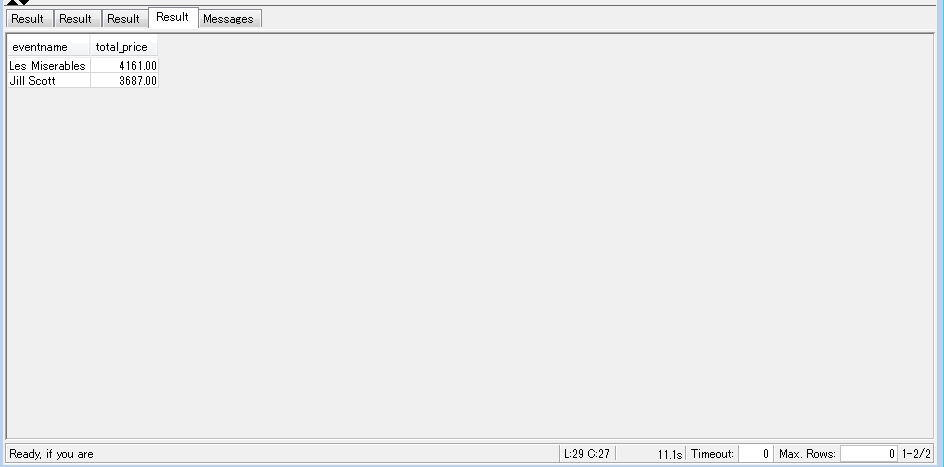
-- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc; |
成功すれば以下のような結果が出力されるかと思います!
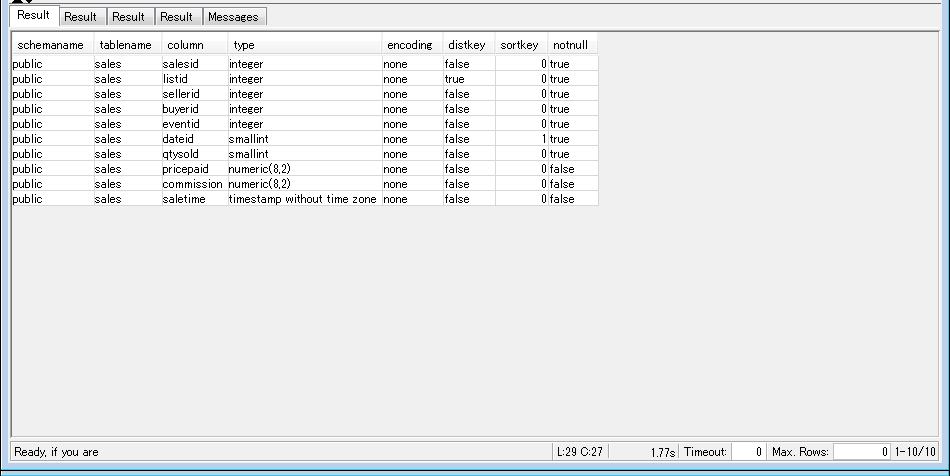
今回はここまでとなります!
いかがでしたでしょうか?
次回は『Amazon Redshit編~Redshiftをはじめてみよう!パート⑤~』ということで、WEBコンソール画面でパフォーマンス等を確認をしてみたいと思います。
お楽しみに!
