はじめに
Databricks Community Edition の登録から Notebook を立ち上げるまでの手順を示します。
概要
Databricks は、特に海外で破竹の勢いを見せるデータ分析基盤です。
- データ分析のための統合プラットフォーム
- 2000 以上のグローバル企業がビッグデータおよび機械学習パイプラインの設計に活用
- 2020 Gartner Magic Quadrant では Leader に名を連ねた (データサイエンス及び機械学習プラットフォーム分野)
- Apache Spark、Delta Lake、MLflow の開発者が作っている
Azure であれば Azure Databricks を活用すれば OK ですが、AWS で使う場合は EC2 で動かすことになります。
どちらにせよコストが発生してしまうので導入をためらう人もいるかと思います。そんな人のために Databricks Community Edition という AWS 上で稼働する無償プランが用意されています。有償版との違いはざっくりと以下の通り。
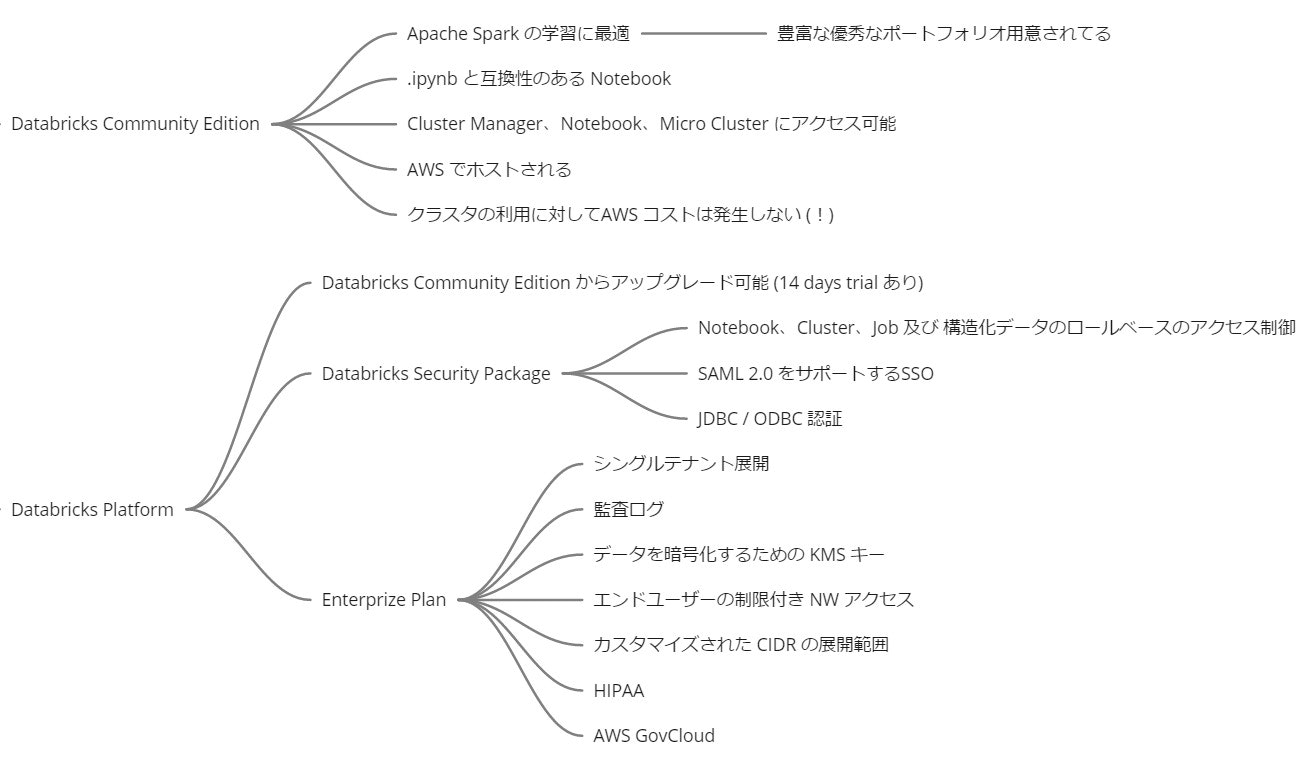
セキュリティやロール管理などを考慮すると仕事で使う場合にはアップグレード必須。無償版で使い勝手を検証 → 14日間トライアル → 本番運用という流れが良さそうです。
アカウント作成
Try Databricks にアクセスして、GET STARTED をクリック
全ての項目を入力し、 Sign Up をクリック
しばらくするとこちらの画面に遷移します。

メアドに届いたメールのリンクに遷移し、パスワードを設定します(初回登録でも Reset Password になるようです)。
これで完了。すぐにコンソール画面が表示されます。

クラスタの作成
Home 画面より、New Cluster をクリック
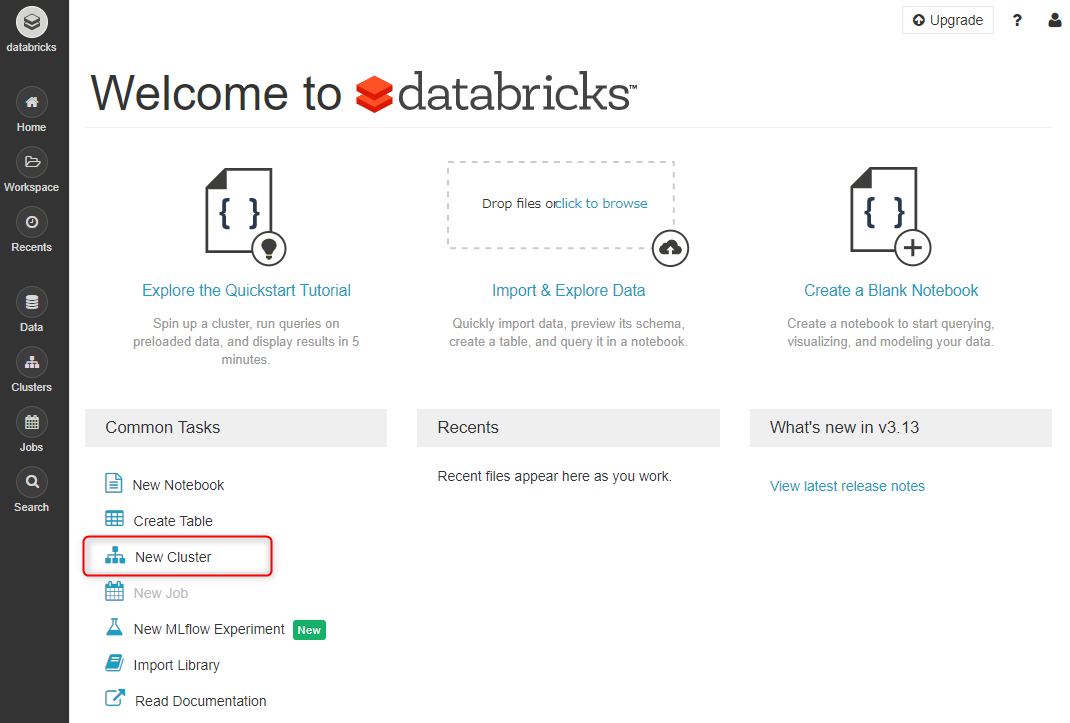
Community Edition では Driver クラスタのみ。 Cluster Name は任意で設定します。Runtime Version については、既存アーキテクチャやスクリプトとの兼ね合いを検討する必要がないのであれば、デフォルト値で良いでしょう(2020年2月25日 時点では 6.2)。
インスタンスは us-west に立ち上がるようです。どれかを選択して Create Cluster をクリック。
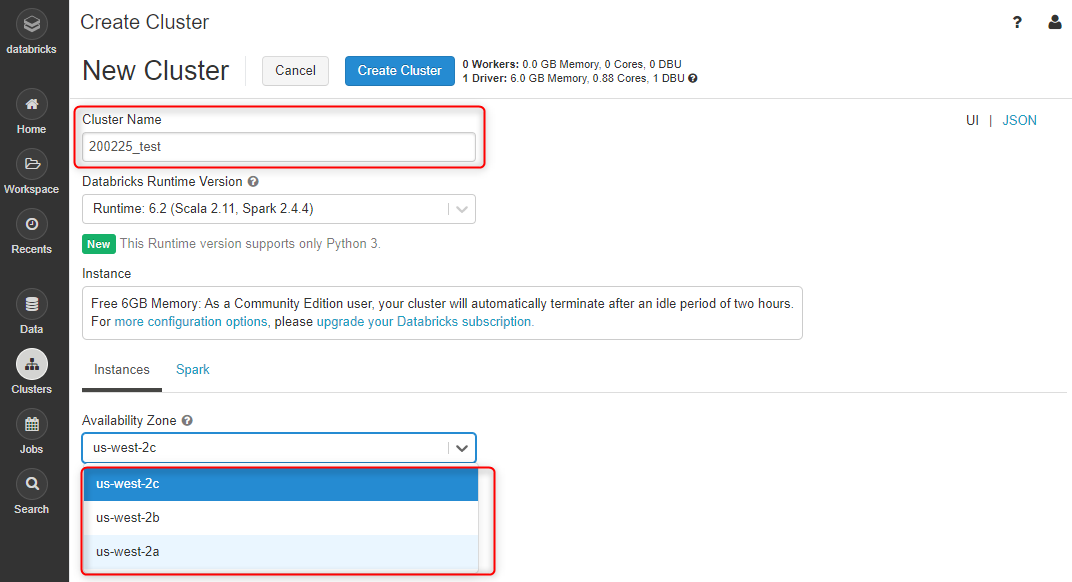
ちょっと待つとこちらのアイコンが緑になります。これで Cluster の準備完了です
Notebook の作成
トップ画面から New Notebook をクリックし、名称を任意で入力します。アカウントを作成したばかりであれば、先ほど作成したクラスタが選択されているはずです。Create をクリック。
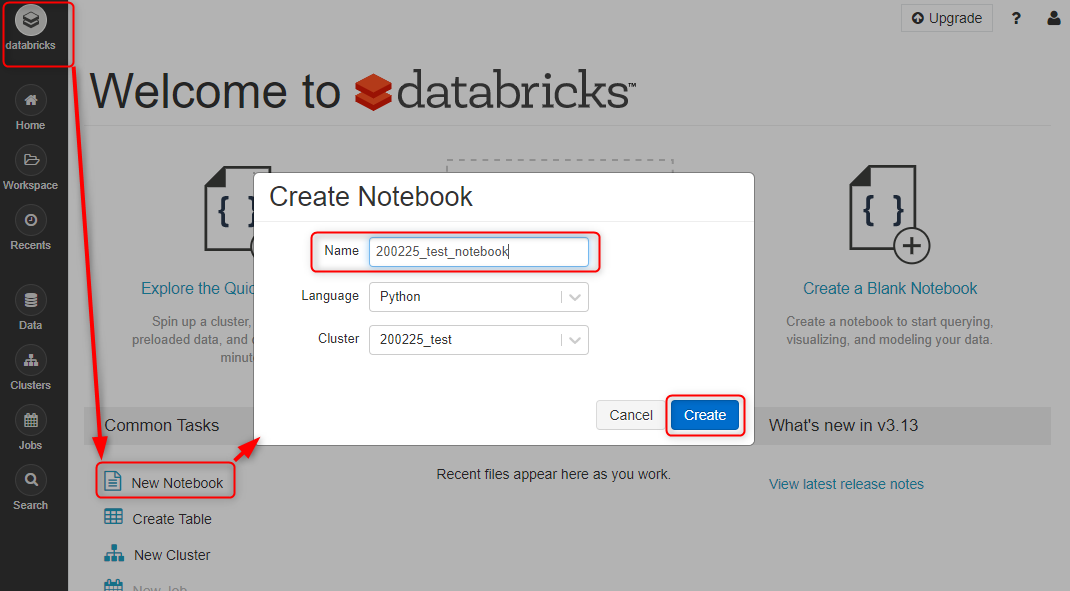
すぐに Notebook の画面が出てきます。
さいごに
一定規模以上のデータを保持していて、その解析に Spark 使っているのであれば、現時点では Databricks 一択になるかと思います。普段 Jupyter Notebook で分析をしている方は触っておくだけでも損はないはず。
