はじめに
Amazon から発売されている Alexa のように、精密な発音をする音声の読み上げの機能について
AWS はどのようにして最適化を行っているのか、について記事があったのでご紹介いたします。
Amazon Polly とは
- 高度な深層学習テクノロジーを使用して、29 の言語および 61 の音声を使える
- 人間のように聞こえる音声を合成するテキスト読み上げ( TTS )を提供するクラウドサービス
- 自動コンタクトセンター、言語学習プラットフォーム、翻訳アプリ、および記事の読み上げ。 幅広い用途に対応する音声合成を使用するデジタル製品の開発に役立つ
Amazon Polly は現在、2 つの日本語音声を提供しています。
日本語は書記体系が複雑であるため、TTS システムに多くの課題をもたらします。
日本語は TTS にとって課題が多い言語
日本語の書記体系は、主に 3 つの書記法(漢字、平仮名、片仮名)で構成されています。
多くの場合、書記法は互換できます。
例:『ロウソク』を表す単語は、漢字『蝋燭』、平仮名『ろうそく』、片仮名『ロウソク』
と書くことができる。
- 漢字の読み方には音読みと訓読みがあり、さらに熟語の読みは、当て字の場合など、構成文字の読みから予想されるものとは異なる場合がある
- 人名の場合に特に顕著であり、文字列からその名前の発音を常に予測できるとは限らない
TTS システムを最適化するには
文を単語に分割する
英語の場合、単語はスペースで分かれているため、この作業は簡単ですが、日本語の場合は一筋縄にはいきません。
- 日本語は、間にスペースを入れずに単語をつなぎ合わせるため、単語と単語の境界を予測するモデルが必要になる
- 英語で、『Applesonatable』 などの文字列を個々の単語に分解する場面では、 言語的な知識を用いると、“Apple son at able” ではなく “Apples on a table” であり これを自動的に行うにはモデルを学習する必要がある
日本語の単語の発音は、周囲の文脈に大きく依存
同じ漢字の連なりの単語であっても、発音が異なり、文脈に応じて異なる意味を有することがあります (同形異義語)
例:1
例:2
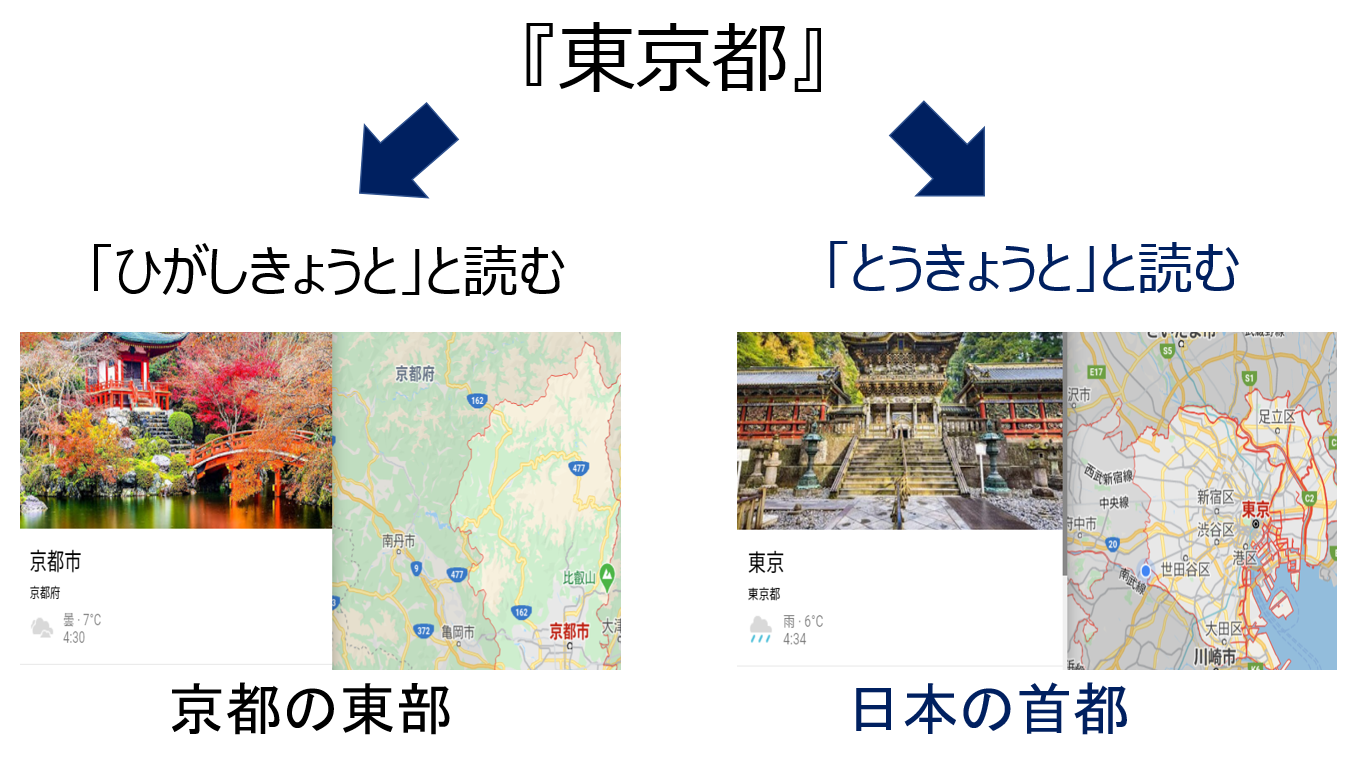
「東京都に行った」⇒「東京/都/に/行った」と分割でき、この場合は「とうきょうとにいった」と読みます。
「東/京都/に/行った」⇒「ひがしきょうとにいった」と読みます。
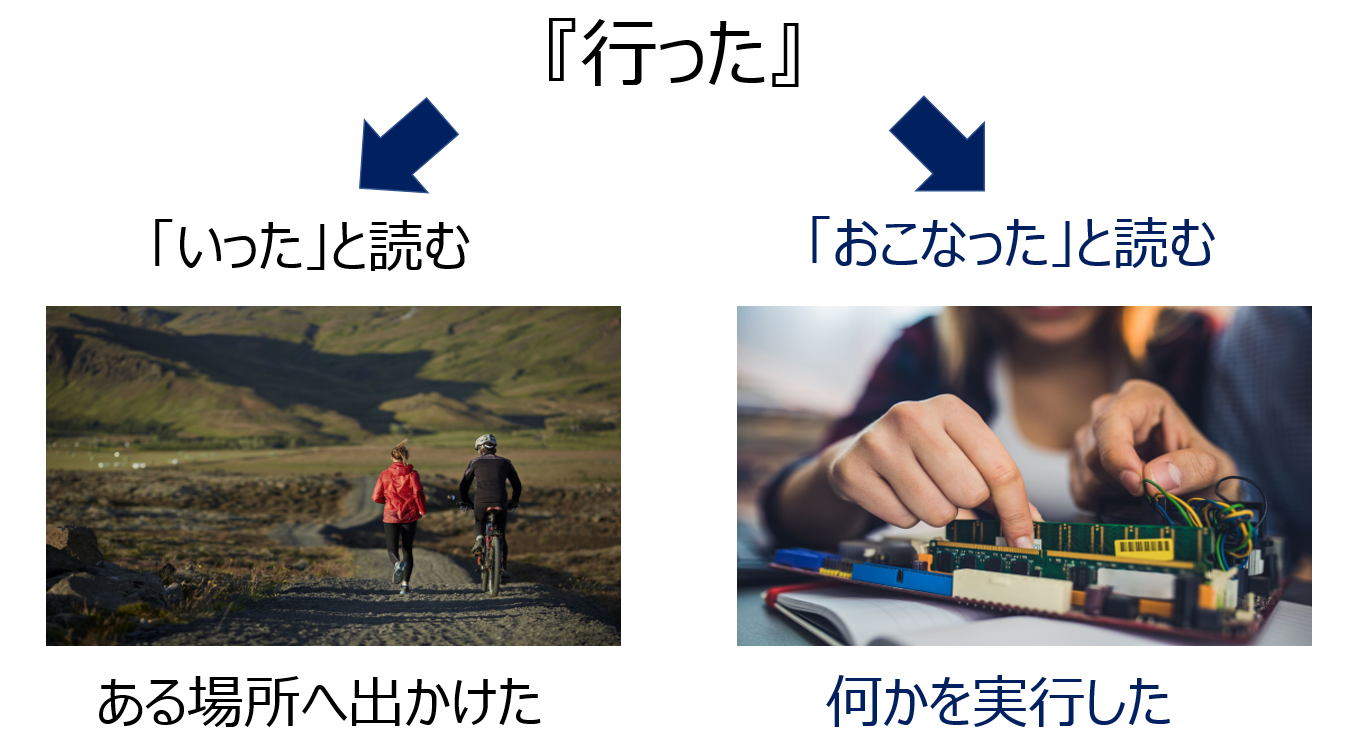
これらの両方の場合に、「行った」は「いった」と読みますが、
「東京都に行った事業の報告をする」という文脈では、2 番目の意味『何かを実行したこと』となり、
「いった」ではなく「おこなった」と読みます。
日本語は高低アクセント言語
アクセントの違いによって単語の意味に違いが生じる可能性があります。
例:雨(頭高型アクセント)と飴(平板型アクセント)
平仮名で書くと両方とも「あめ」ですが、アクセントの表記がありません。
Amazon Polly のソリューション
- Amazon Polly は日本語のTTS システムで機械学習(ML)モデルを採用。
- ML モデルは、周囲の単語およびその構文(文法)および形態(単語構造)情報に関する情報を使用して、単語の発音または高低アクセントおよび抑揚を予測
- モデルは、言語のパターンを一般化するのに役立ち、合成されたことのない文の発音および抑揚を予測できる
正確な発音をさせるのは難しい
人は、書かれた文脈が不十分でも、より広い文化的または状況的知識から文脈情報を推測し、筆記された文を理解できます。
現在の TTS モデルでは、利用可能な情報はあってもモデルがそれを使って正確な予測を行うことができないこともあります。
母国語話者でさえ、背景知識がないために正しい発音を予測するのに苦労する場合があります。
人名や地名で特によくあることで、
例:「愛」という名前は、「あい」、「めぐみ」、「まなみ」、「まな」
このように少なくとも 28 通りの読み方があります。
この問題を回避するために、日本語テキストの発音をコントロールする方法がいくつかありますので、後編でご紹介していきます。
