はじめに
公式ドキュメントに沿ってdatabricks on AWSを動かしてみたいと思います。
今回のテーマは
「Get EC2 instance information」です。
その名の通り、databricks上でコードを実行してEC2インスタンスの情報を表示させるという内容です。
本題
今回行う作業としては、
- 作業ページまでのログイン
- クラスターの作成
- Notebookの作成
- スクリプトの実行
の4ステップです。
早速初めて行きましょう。
作業ページにログインする
1.以下URLからdatabricksにログインします。
https://accounts.cloud.databricks.com/registration.html#login
2.「Deploy Databricks」を選択し、水色文字になっているURLをクリックします。
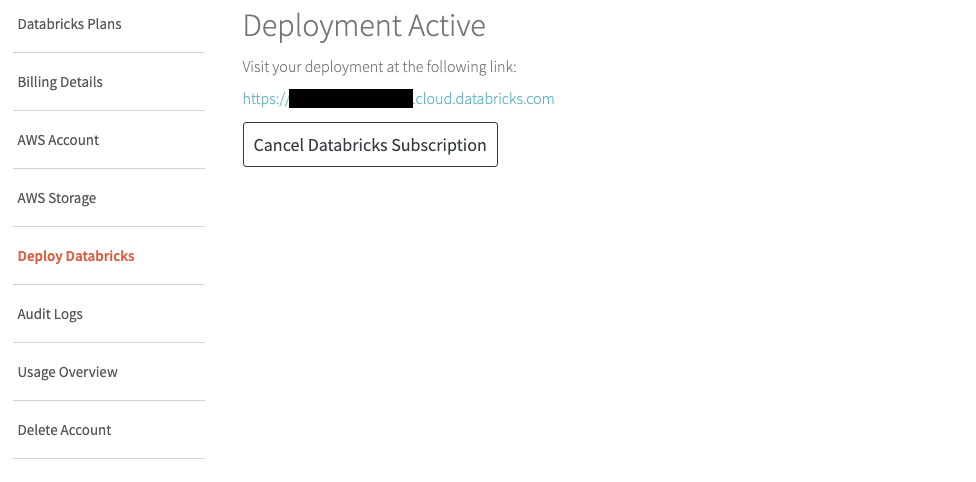
3.1でログイン時に使用したメールアドレスとパスワードを使用してログインします。
この画面に辿りついたらOKです。
クラスターの作成
1.先ほどの画面Common Tasks欄のNew Clusterをクリック。
※左のメニューバーからClustersを選択してもOKです。
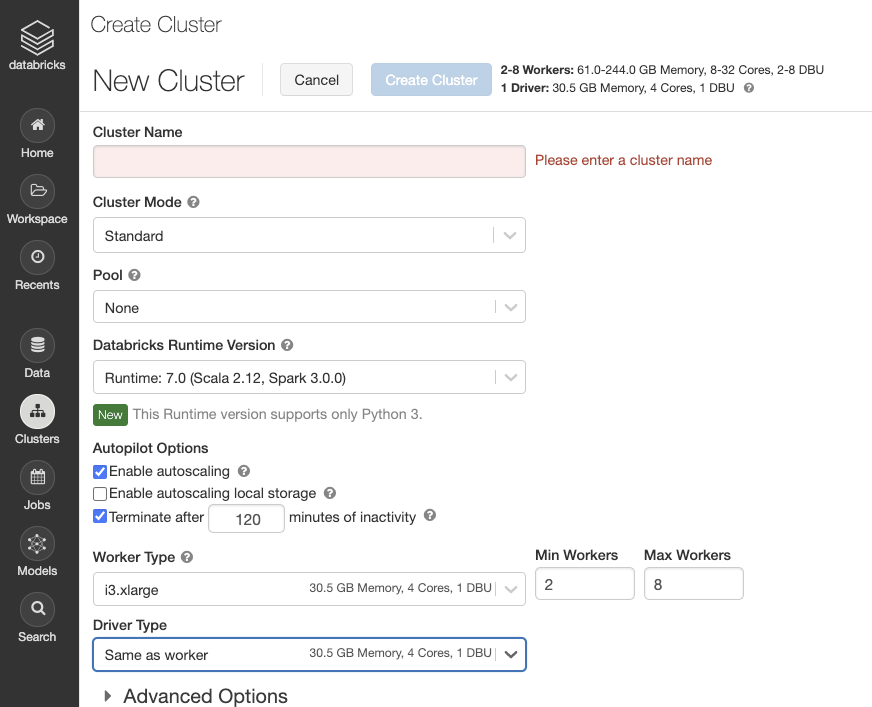
2.ここではクラスターの詳細設定ができますが、とりあえずデフォルトのもので構いません。
(コストが気になるという方は
Worker Typeのところをm4.largeなどの変更しても大丈夫です。)
Cluster Nameを記入したらCreate Clusterをクリックします。
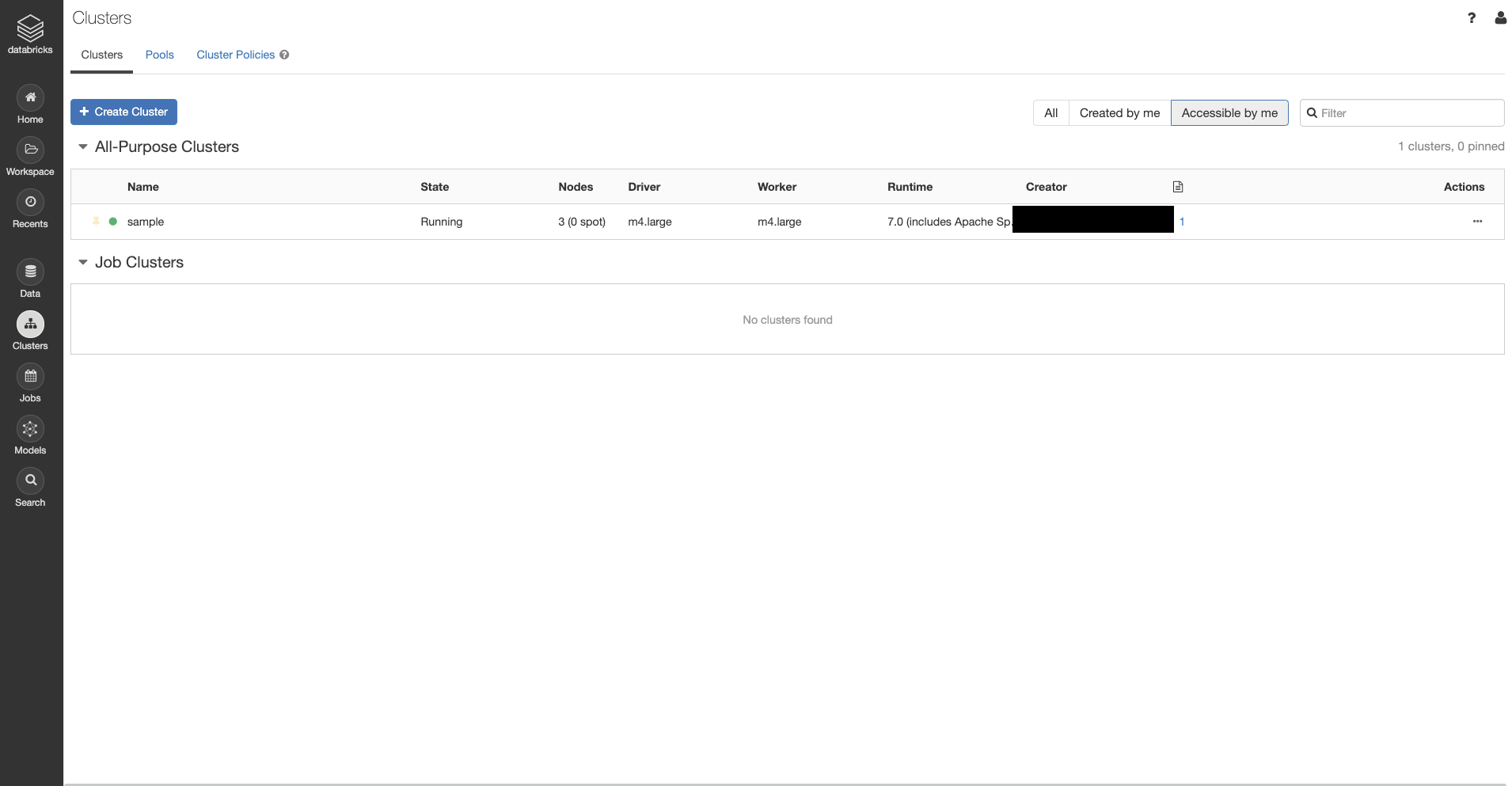
3.左のメニューバーからClusterページにいき
このようにStateがRunningになったらクラスターの設定が完了です。
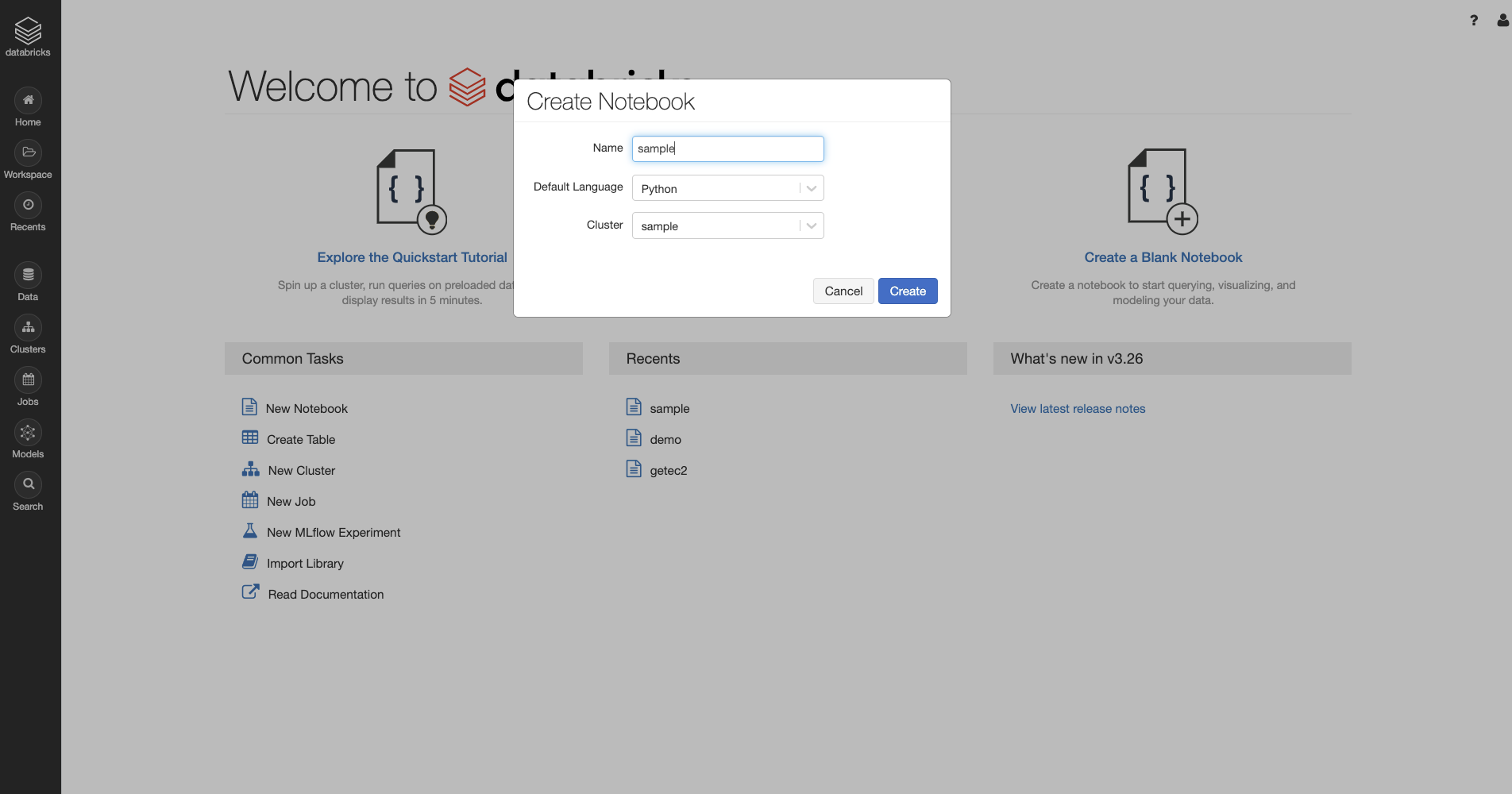
Notebook作成
左上のメニューバーからHome画面に戻ったら
画面右のCreate a Blank Notebookをクリックします。
Name : 任意
Default Language : Python
Cluster : 先ほど作成したもの
を記入してCreateをクリック。
スクリプトの実行
以下のスクリプトを実行していきましょう。
基本的な動作はjupyter notebookと同じです。
1.今回使うモジュールのimport
|
1 2 |
import urllib.request import json |
2.インスタンス情報取得
|
1 2 |
instance = json.loads(urllib.request.urlopen('http://169.254.169.254/latest/dynamic/instance-identity/document').read()) instance |
3.マスター/ドライバーのパブリックホスト名を取得
|
1 2 |
public_hostname = urllib.request.urlopen('http://169.254.169.254/latest/meta-data/public-hostname').read() public_hostname |
4.全てのワーカーのパブリックホスト名とIP情報を取得
numWorkersはClusterページから確認して各自変更してください。
|
1 2 3 4 5 6 7 |
numWorkers = *** worker_instance_ids = sc.parallelize(range(numWorkers)).map(lambda x: (urllib.request.urlopen('http://169.254.169.254/latest/meta-data/public-hostname').read(), urllib.request.urlopen('http://169.254.169.254/latest/meta-data/public-ipv4').read()) ) print worker_instance_ids.distinct().collect() |
※今回の内容は以下公式サイトを参考に作成しました。
ドキュメント内のスクリプトはPython2のモジュールになっているので、本記事ではPython3用に修正しております。
https://docs.databricks.com/administration-guide/cloud-configurations/aws/describe-my-ec2.html
さいごに
公式ドキュメントに基づいて実際にNotebookを動かしてみました。
非常に簡単でしたが、databricksとAWSが連携していることが確認できたと思います。
最後までお読みいただきありがとうございました。
