はじめに
databricks on AWSをdeployするまでの手順をご紹介したいと思います。
databricks on AWSのdeploy完了までには
databricks側とAWS側でいくつかの登録&設定作業が必要となっているため以下3章に分けてご説明いたします。
- その1 databricksアカウントの作成
- その2 AWSアカウントとの連携
- その3 databricks用S3バケットとの連携 ← 今回はここ
本題
長かったdatabricks on AWS のdeploy手順もいよいよ最後のその3まできました。
今回もAWSアカウントとdatabricksアカウントの両方使用するので、
ログインした状態でご準備をお願いいたします。
➀databricks用S3バケットの作成
databricks用のS3バケットを作成します。
databricks公式サイトでも、databricks専用のS3バケットを作成することがベストプラクティスとされているのでそちらに則って進めていきたいと思います。
S3のコンソール画面に移動します。
「バケットを作成する」をクリックしてdatabricks用新規バケット作成作業に入ります。
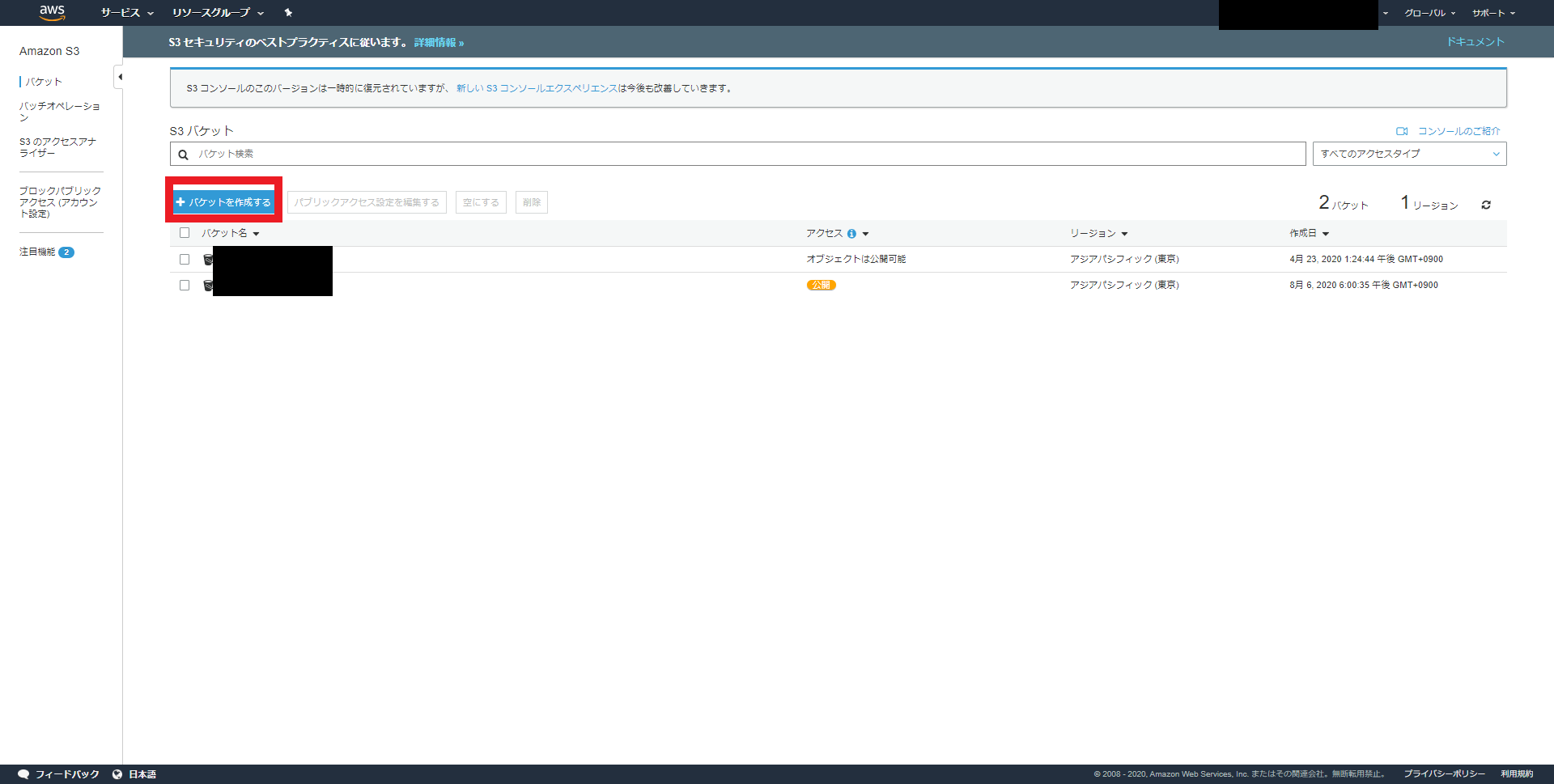
名前とリージョン
バケット名は任意のものでOK(私はs3-for-databricks-testという名前にしました)
リージョンは「アジアパシフィック(東京)」
既存のバケットから設定をコピーは入力不要です。
バケット名とリージョンを記入したら「次へ」をクリック
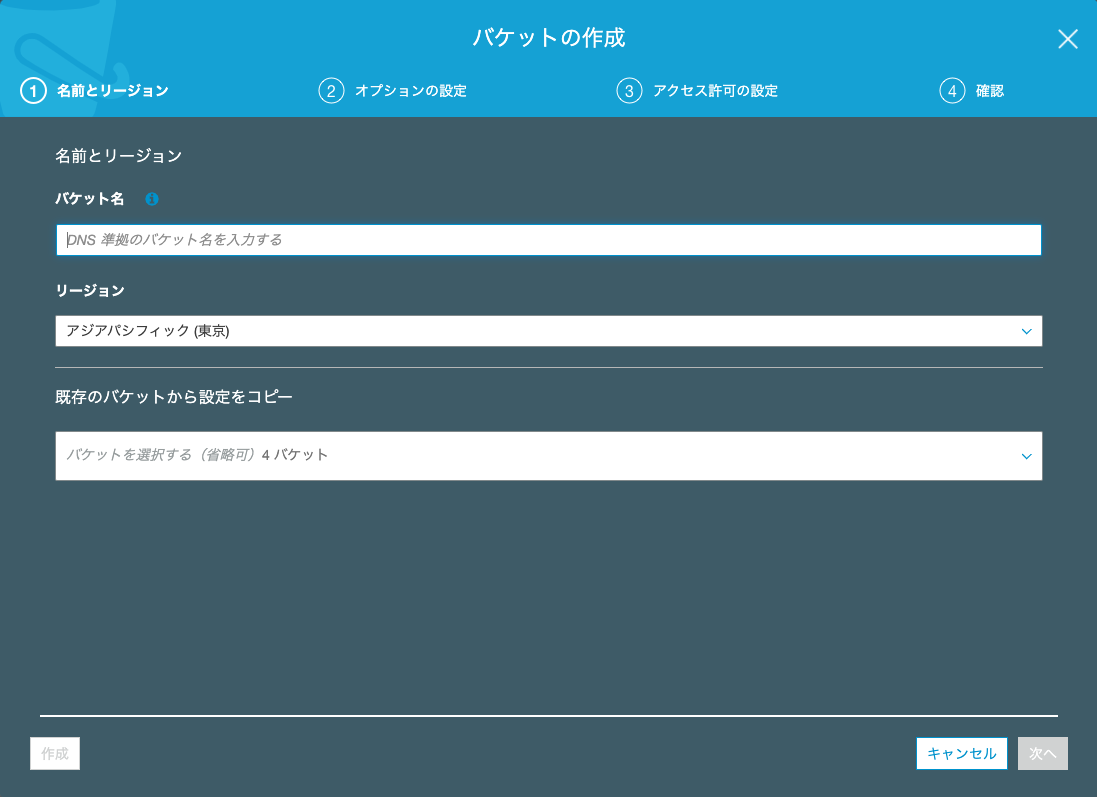
オプションの設定
ここでは様々なオプションを設定することができます。
今回は、databricks公式サイトの方で強く推奨されている「バージョニング」機能のみ設定してとりあえず先に進みたいと思います。
一番上の「バージョニング」にチェックを入れて「次へ」をクリック
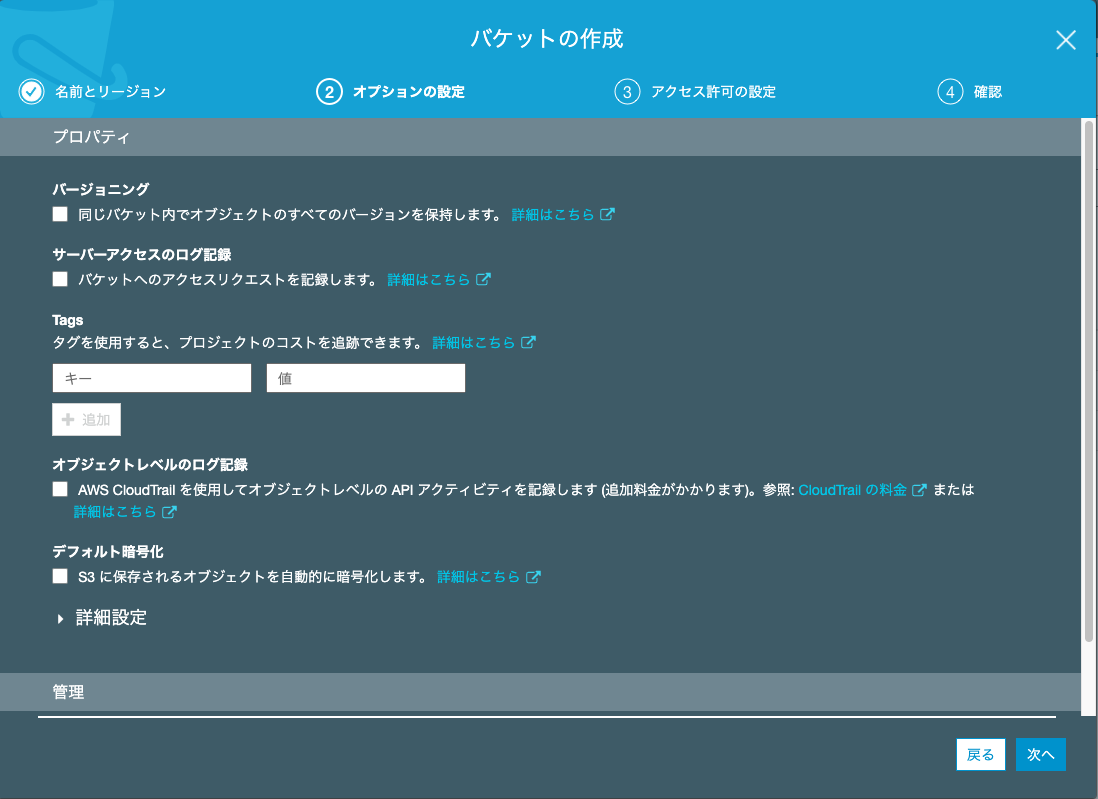
アクセス許可の設定
何も変更せずに「次へ」をクリック
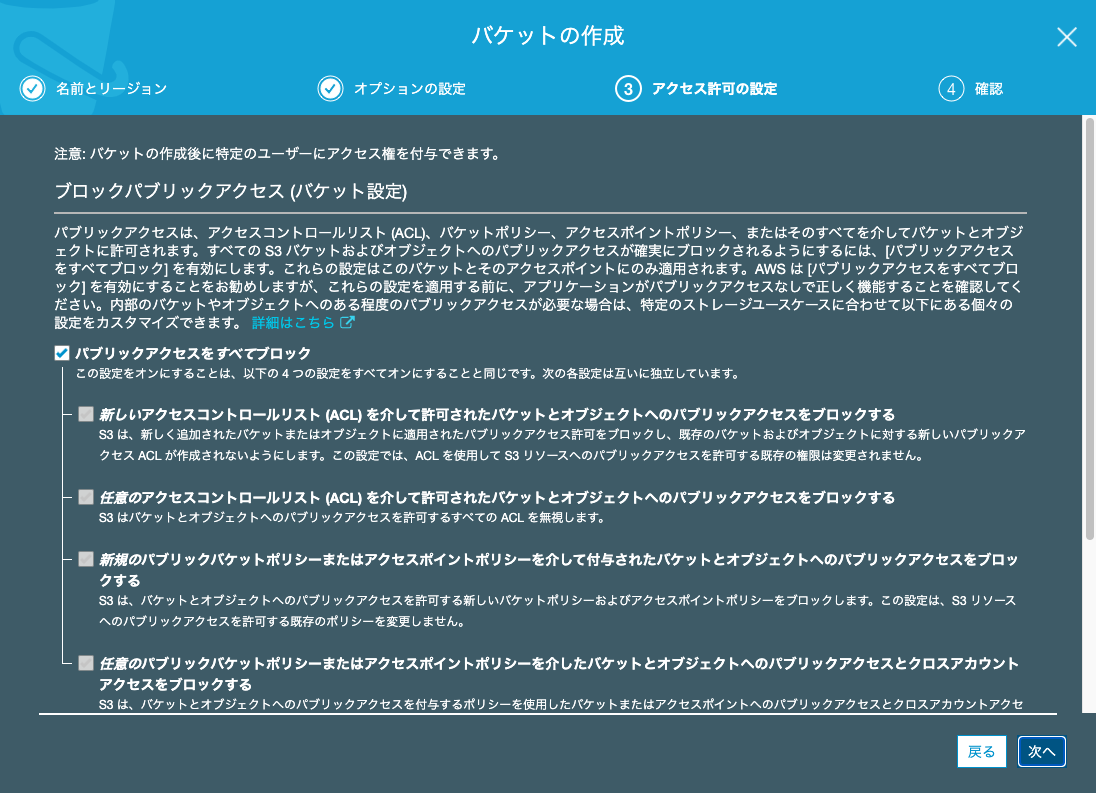
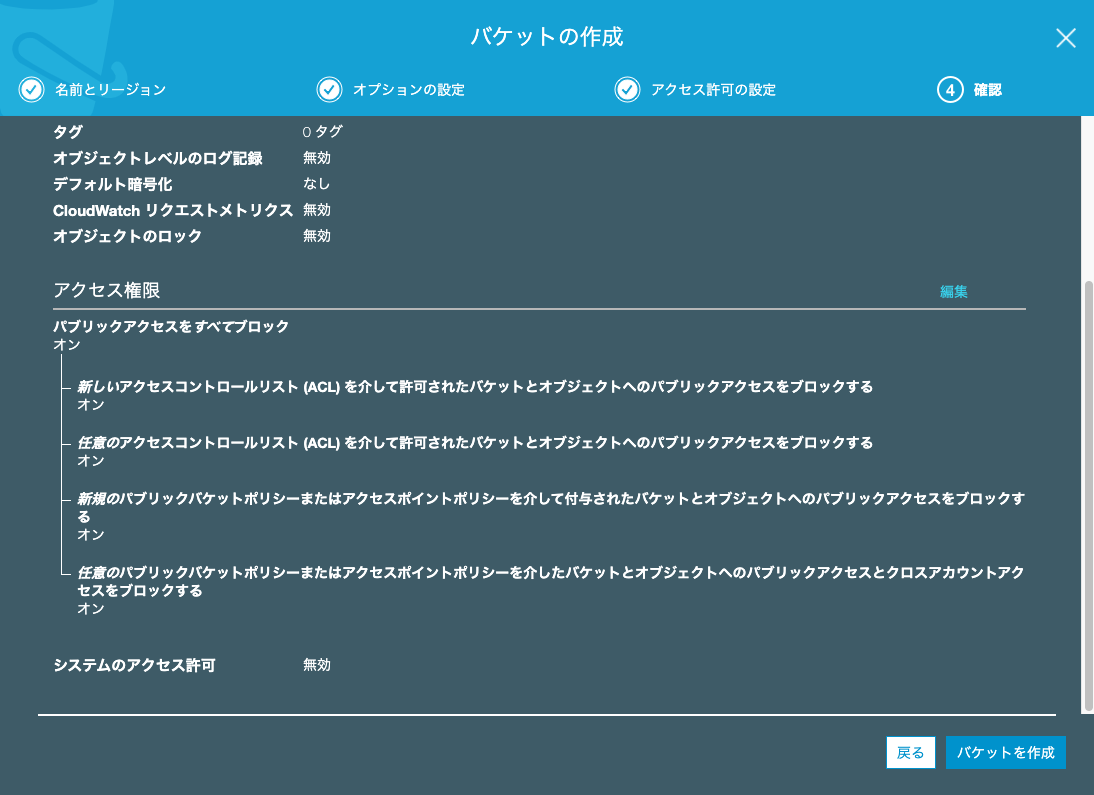
確認
バケット名
バージョニングの有効化
アクセス権限
を確認したら、「バケットを作成」をクリックして、
databricks用S3バケットの作成が完了です。
➁バケットポリシーの作成
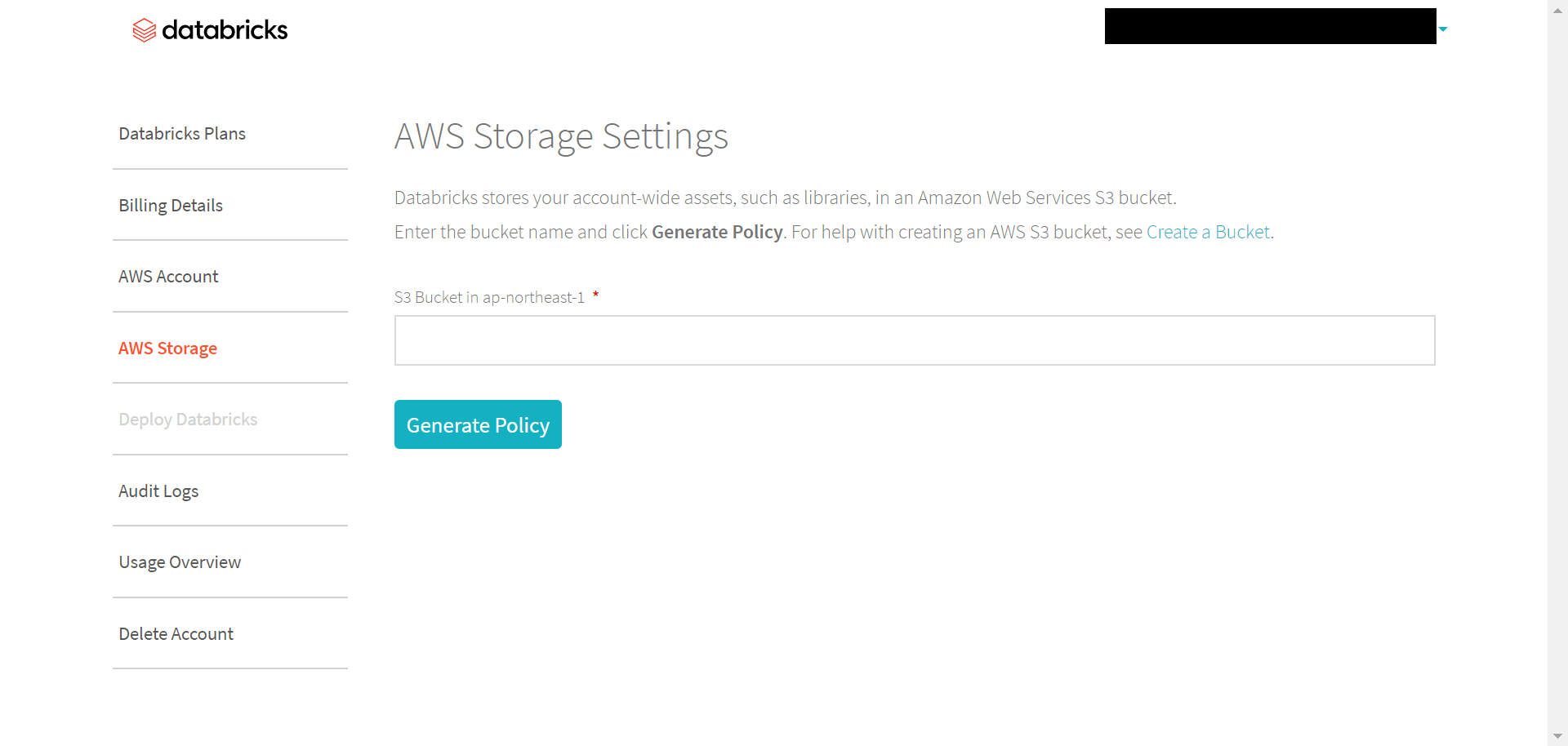
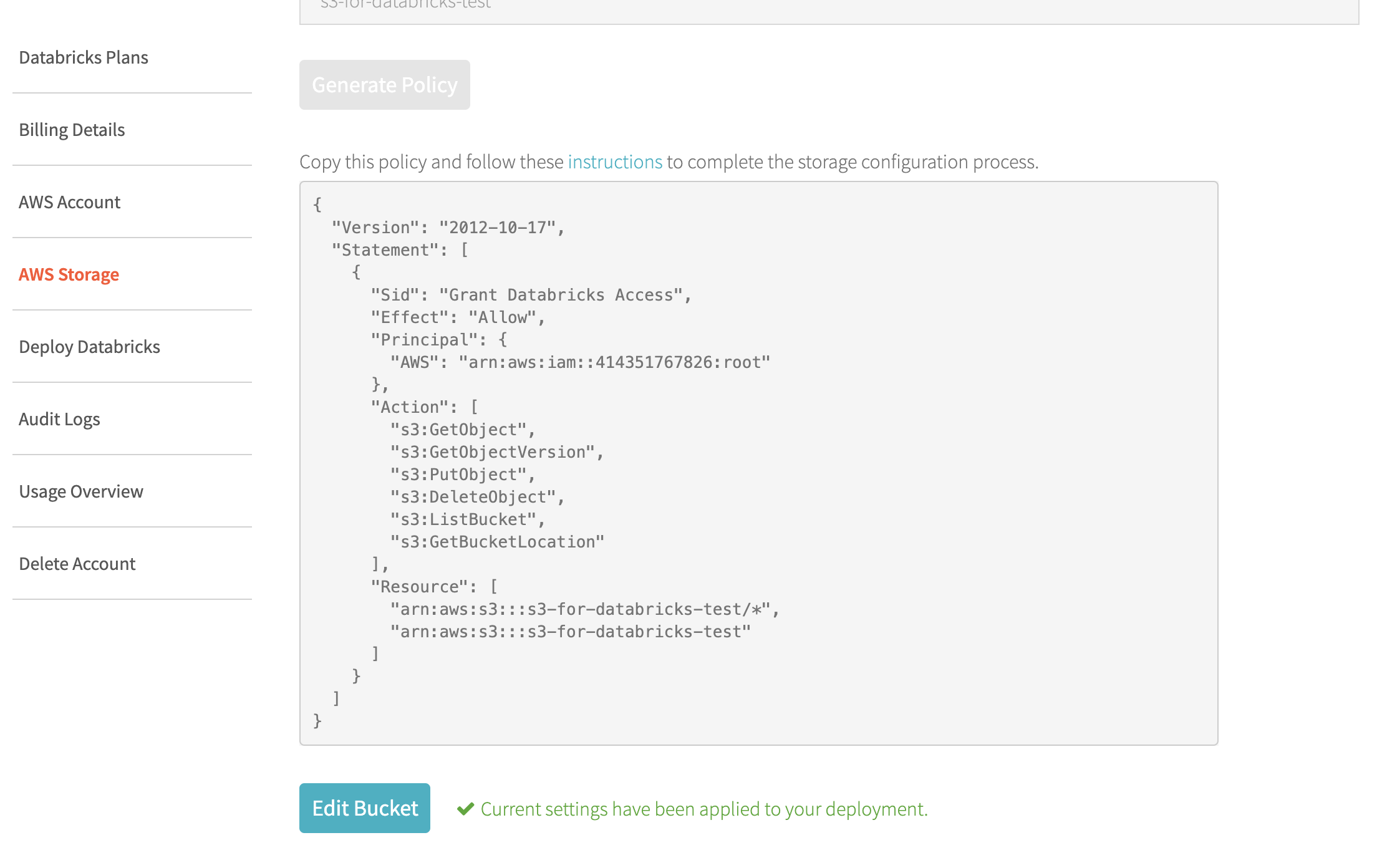
databricksコンソール画面から左部の「AWS Storage」欄を選択するとこの画面になります。
画面中央部の空欄に作成したdatabricks用S3バケット名を記入して「Generate Policy」をクリック。
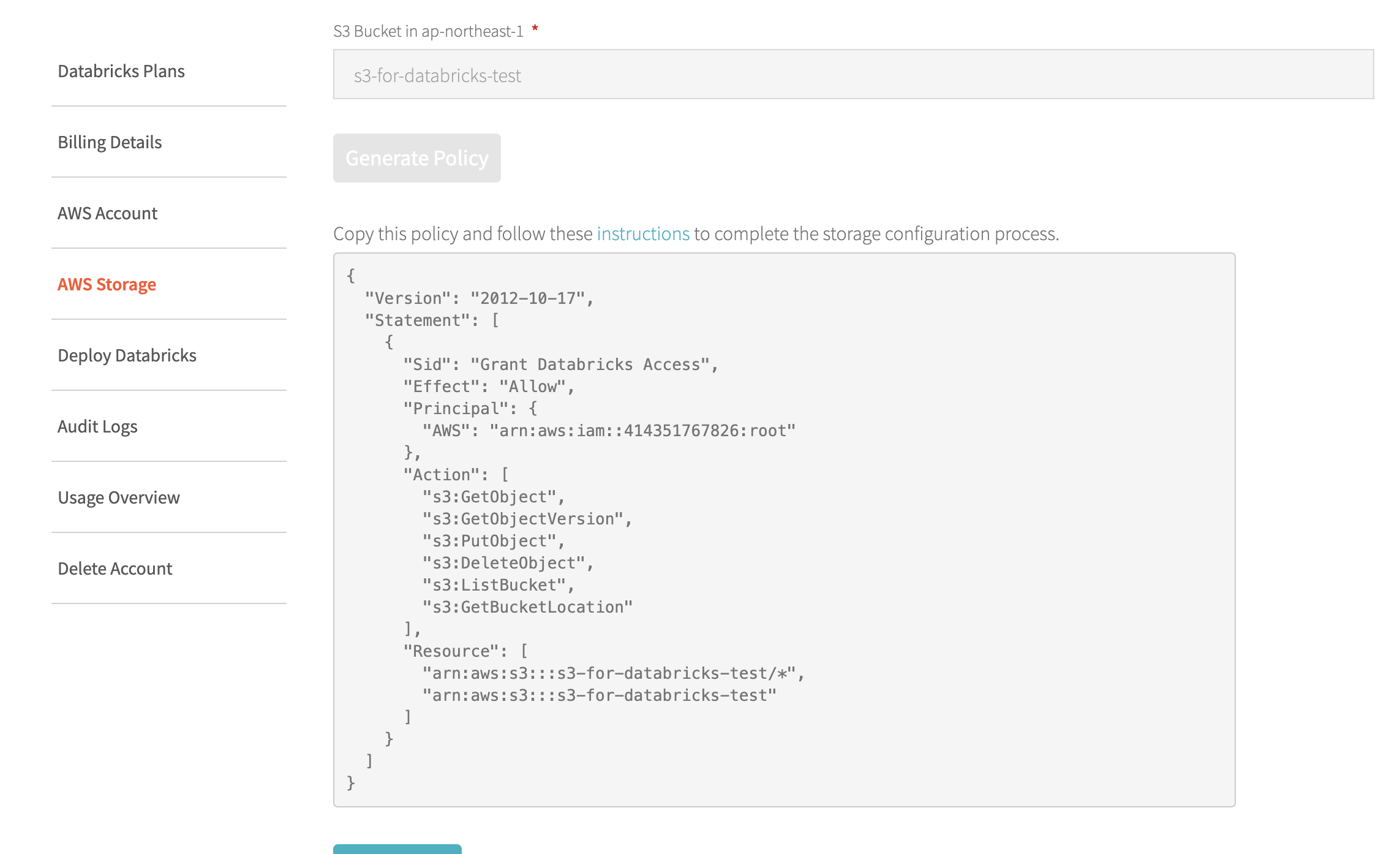
生成されたバケットポリシーをコピーしておく。
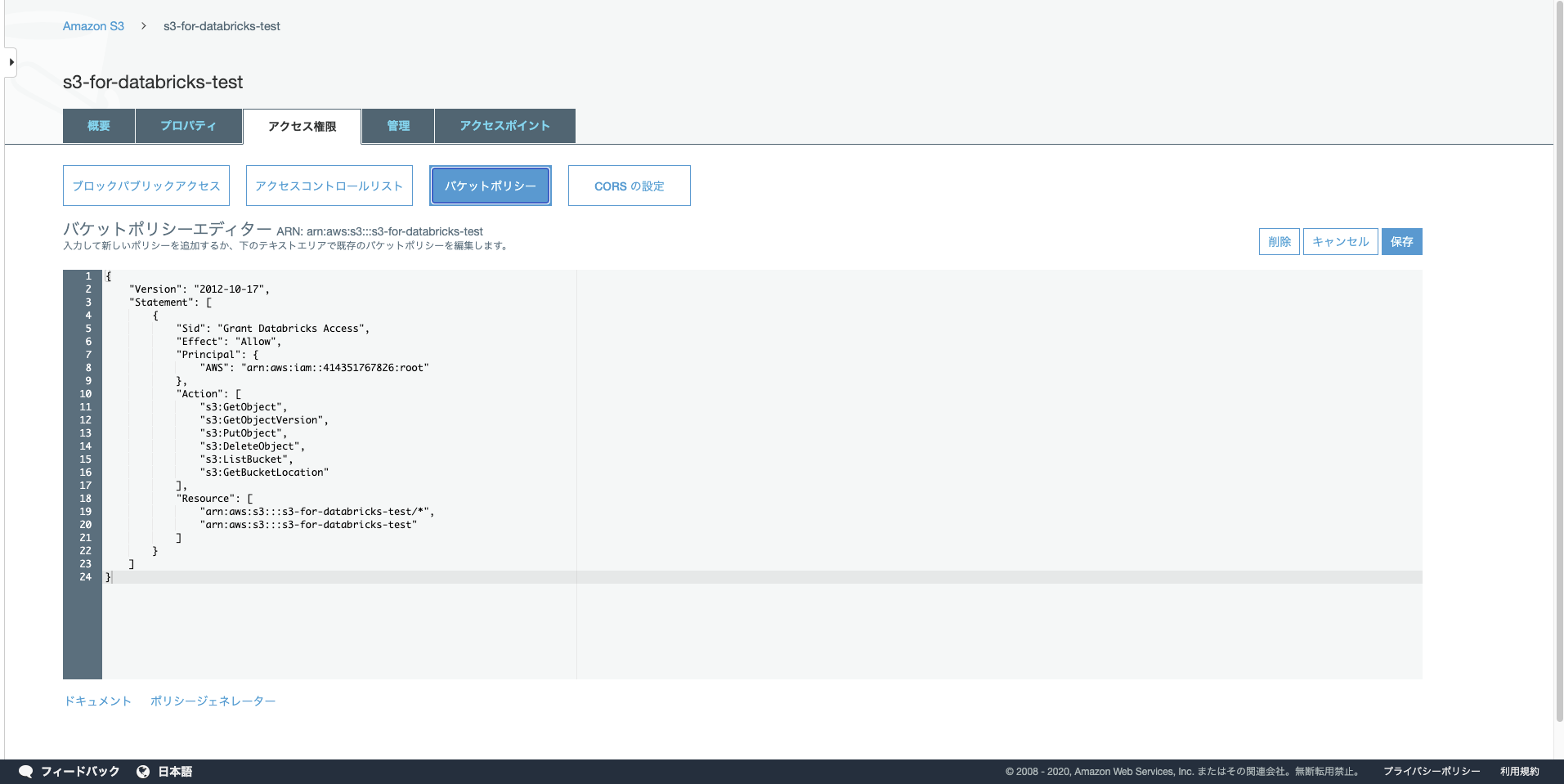
S3コンソール画面に戻って
「databricks用S3バケット」→「アクセス権限」→「バケットポリシー」の順に進みます。
バケットポリシーエディターに先ほどコピーしたバケットポリシーを貼り付けます。
画面右側の「保存」をクリック。
databricksのAWS Storage画面に戻り
「Apply Change」をクリック。
このような画面になったらS3の設定完了です。
➂Deploy Databricks
databricksのコンソール画面に戻り、
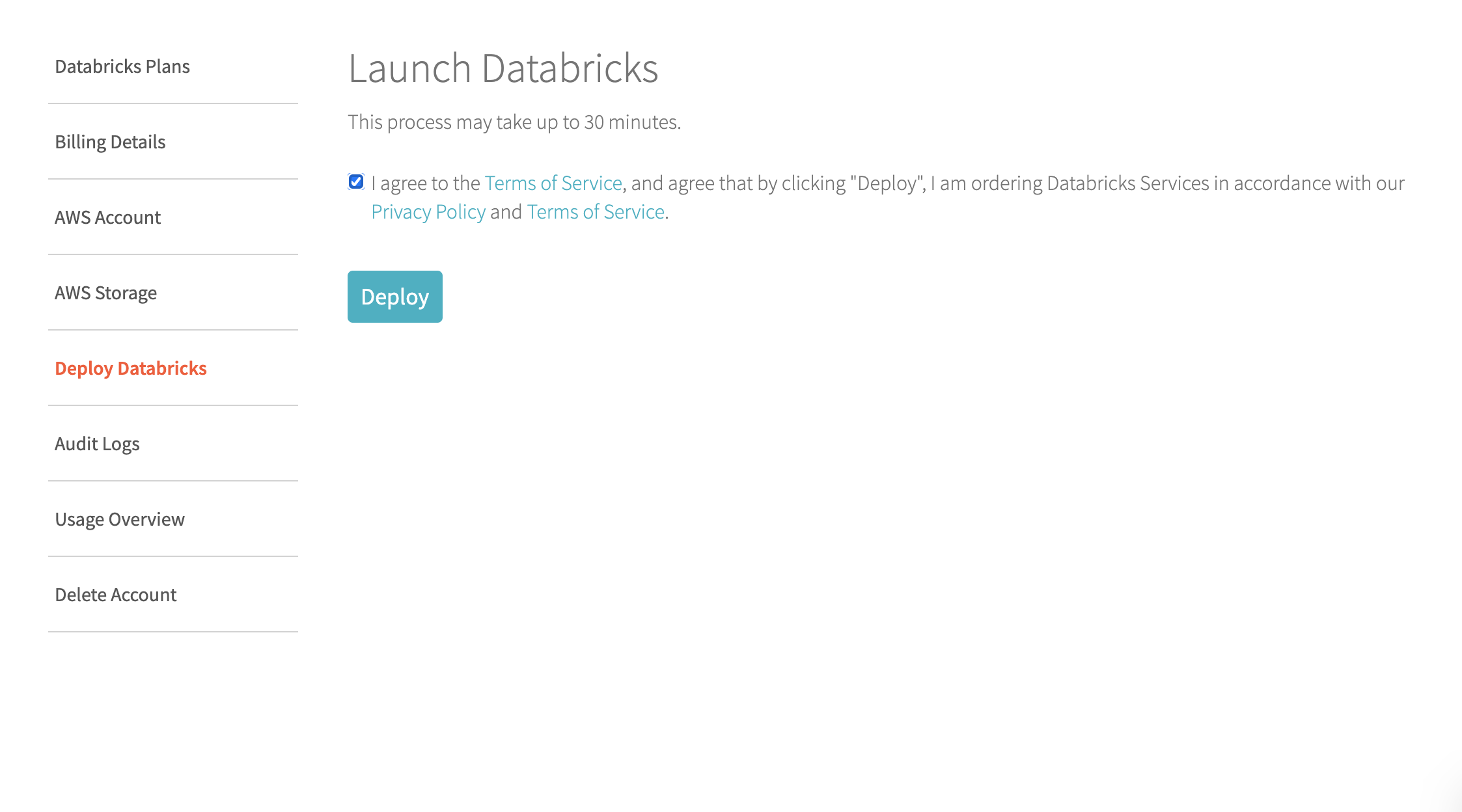
画面左部から「Deploy Databricks」を選択するとこの画面になります。
空欄にチェックをいれて「Deploy」をクリック。
Deployが完了するまで30分ほどかかります。
deployが完了するとdatabricksからこのようなメールが届き、

databricksコンソール画面でもこのような表示になります。
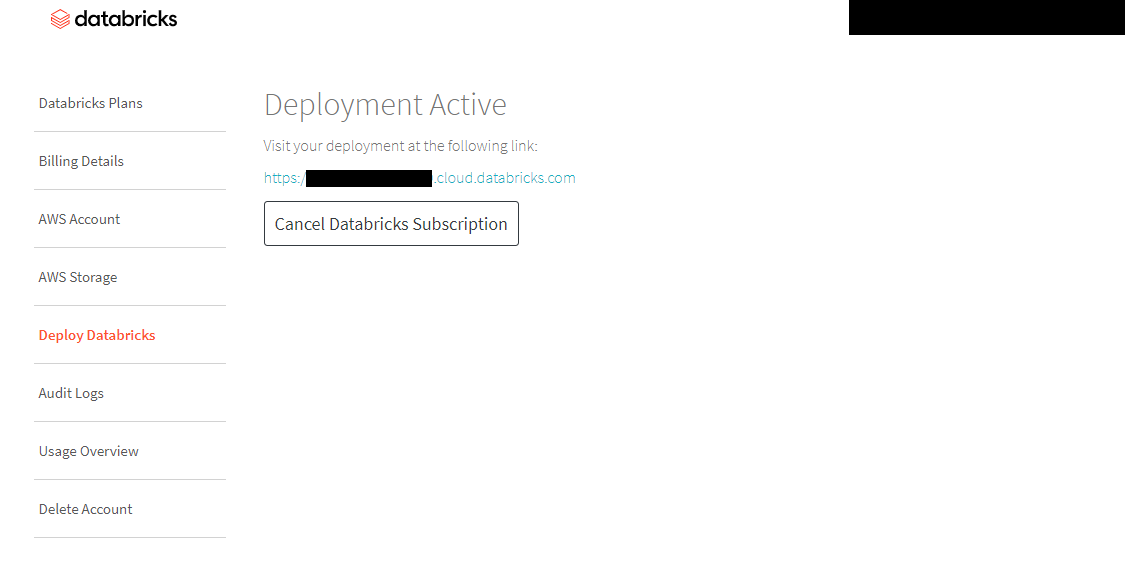
以上で、作業は終了です。
おわりに
3章にわたるdeploy作業も今回でついに終わりを迎えました。
お疲れさまでした。
本記事がどなたかのお役に立てていれば幸いです。
今後も引き続きdatabricks公式ドキュメントを参考に記事をupしていく予定です。
