はじめに
RedshiftMLを実際に触ってみた手順を書きたいと思います。
大まかな手順は、
- サンプルデータをAWS Redshiftにインポート
- Amazon RedshiftMLで機械学習モデルを構築
- 機械学習の結果を見る
RedshiftMLで機械学習モデルを構築していきたいと思います。
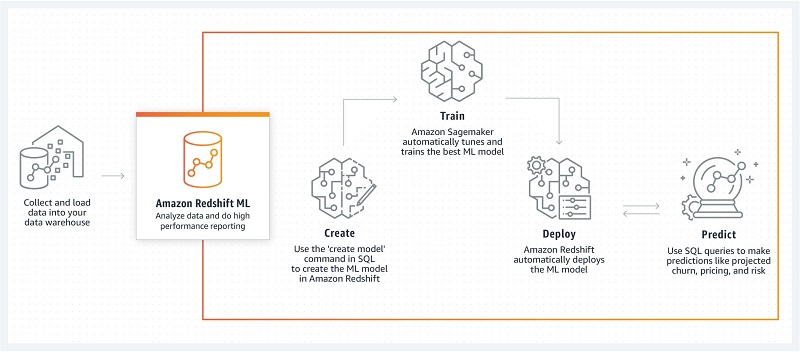
RedshiftMLって何?という方はAWS Redshift 活用術 ①をご覧ください。
この記事ではAWS環境の構築、後半では機械学習モデルを構築するまでの手順をまとめました。
RedshiftML第3回 機械学習モデル構築の記事URL:
メインターゲット
- SQLをメインで使用しているデータベース開発者、アナリスト
- Amazon Redshiftを普段から利用している方
利用するAWSサービス
Amazon Sagemaker Autopilot
- 自動機械学習(AutoML)のタスクを自動化
- 最適な機械学習アルゴリズムを自動的に選択してくれる
- モデルのトレーニング、チューニングが簡単にできる
- 初期費用¥0からスタートできる
- 回帰、二項分類、複数クラスの分類をサポートしてくれる
詳しくはこのページをご覧ください。
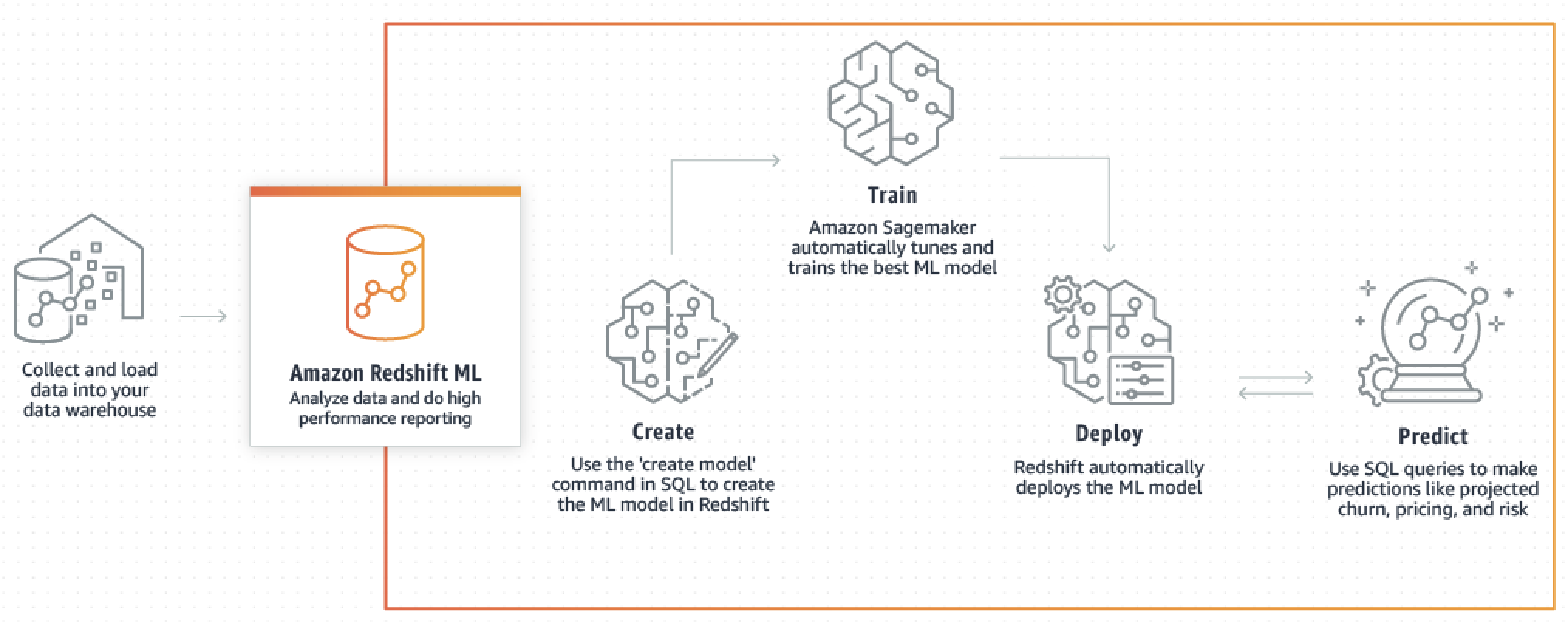
Amazon Redshift ML
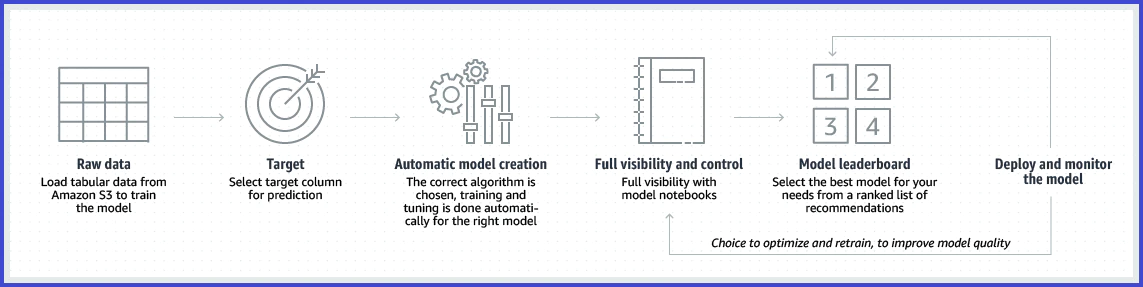
- SQLを使ってRedshift内のデータから機械学習モデルを構築・デプロイ
- 予測結果もSQLを叩いて取得
- Redshift ML のバックエンドでは Amazon Sagemaker Autopilot が動いている
データセット
本記事ではこちらのウェブサイトの情報とデータを利用します。
イーコマースのログデータが基になっているCSVデータです。
データセットの詳細
- 顧客をランダムに3つに分類して、販促キャンペーンのメールを配信します。
- メンズ商品のキャンペーン
- レディース商品のキャンペーン
- 配信なし
- ウェブサイトの訪問履歴・購入金額をトラッキング
- トラッキングの期間はキャンペーンメール配信から2週間
目的
やみくもにキャンペーンをするのは販促費などの無駄になります。よって、
- 普段は商品購入意欲が高くない
- キャンペーンを行うと商品購入する可能性が大幅に上がる
といったユーザーに絞って販促費を投入できればROI(Return On Investment、その投資でどれだけ利益が上げられたかを知る指標)が最大化できるはずです。
ROI最大化の手法の一つに、Uplift Modeling というものがあります。


本記事では Uplift Modeling のロジックへの組み込みを想定し、特定のキャンペーンを打つべきユーザーを予測する機械学習モデルを作成します。
モデル作成には2020年12月にパブリックプレビューになった Amazon Redshift ML を利用します。
データセット
- 過去12か月以内に物品を購入した64,000人の顧客情報
- ダウンロードURL
- Windows であれば、リンクを右クリック > リンク先を保存
スキーマ
| カラム名 | データ型 | 概要 |
|---|---|---|
| Recency | int4 | 前回の購入から経過した月数 |
| History_Segment | varchar(256) | 過去1年間の購入金額の区分 |
| History | float (8) | 過去1年間の購入金額 |
| Mens | boolean | 過去に男性向け製品を購入したかどうか |
| Womens | boolean | 過去に女性向け製品を購入したかどうか |
| Zip_Code | varchar(256) | 顧客の居住カテゴリ。Urban, Sunurban, Rural |
| Newbie | boolean | 過去1年で新規顧客になったかどうか |
| Channel | varchar(256) | 過去に顧客が購買した経路 |
| Segment | varchar(256) | 受け取ったキャンペーンメールの種類。Mens E-mail, Womens E-mail, No E-mail |
| Visit | boolean | 過去2週間にウェブサイトを訪問したかどうか |
| Conversion | boolean | 過去2週間に購買に至ったかどうか |
| Spend | float (8) | 過去2週間の購入金額 |
AWS環境構築
IAMロール
Redshift ML 経由で SageMaker Autopilot を操作できるようにするため、対応する権限を設定します。
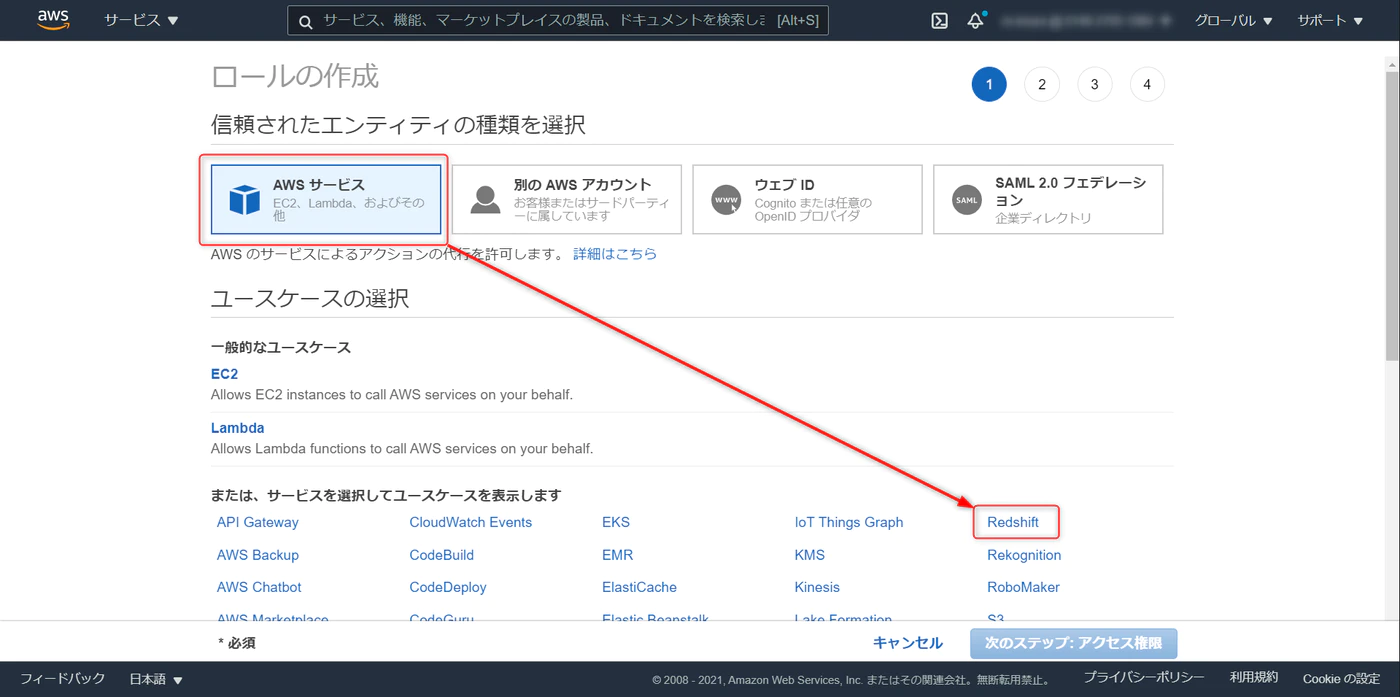
IAM > ロール > ロールの作成
AWS サービス > Redshift と進み、
画面下部の Reedshift – Customiable を選択
ロール名を任意で設定、ロールの作成をクリック
作成したロールを開き、アクセス権限のタブで
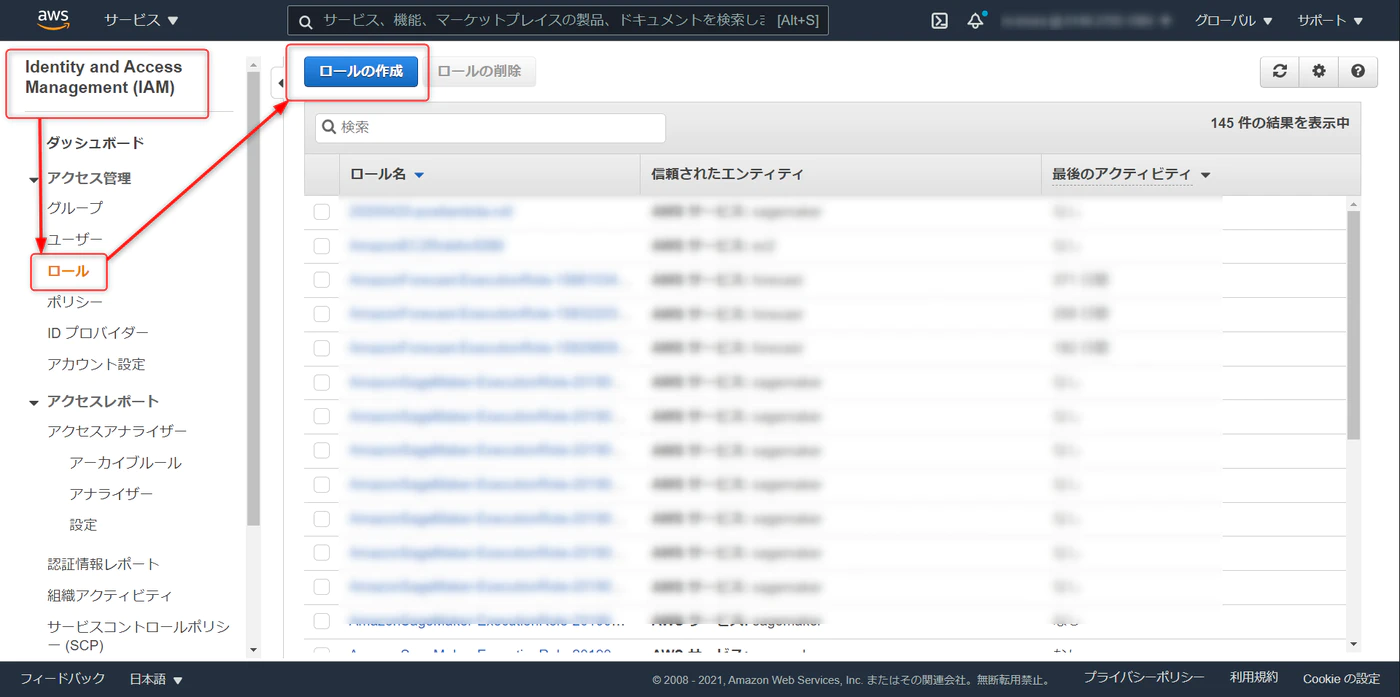

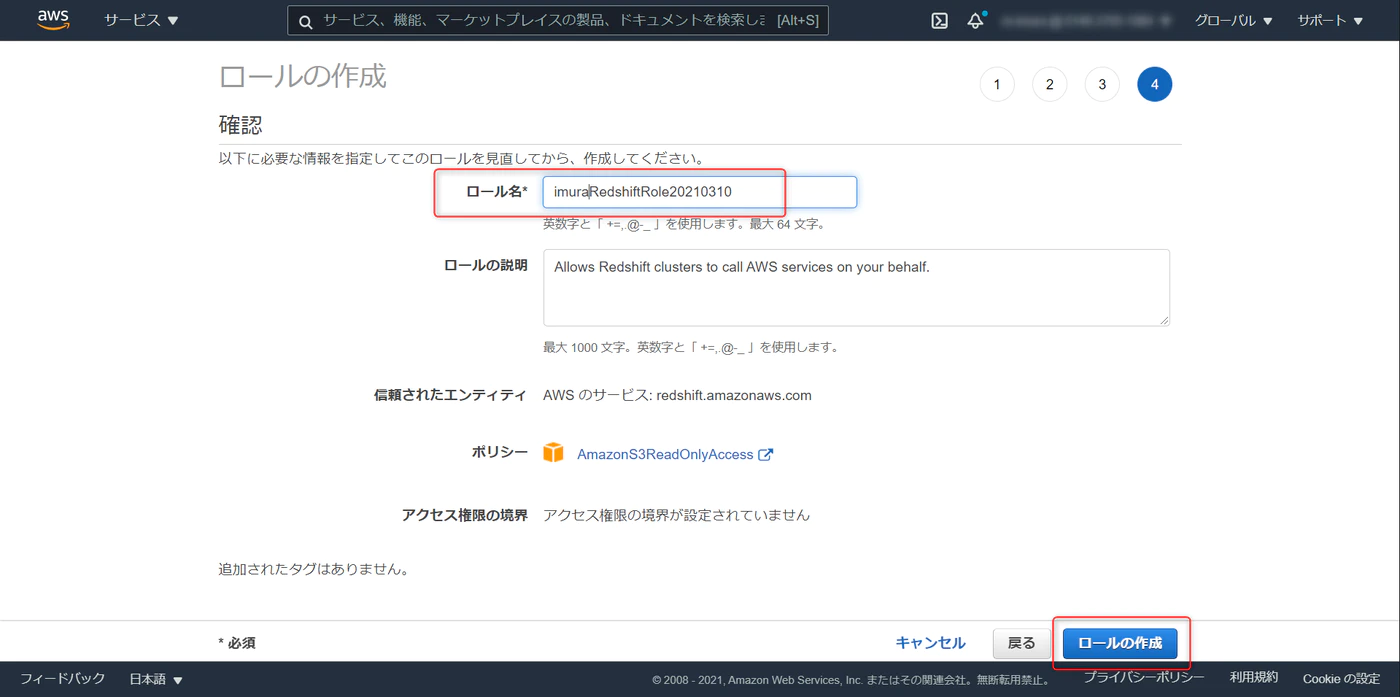
- AmazonS3ReadOnlyAccess(Amazon S3 バケットに読み取り専用アクセスを付与します)
- AmazonSageMakerFullAccess(Amazon Sagemakerのフルアクセル権限をふよします)
のポリシーをアタッチします。
上記のポリシーは実行権限が大きいので、本番デプロイ時には以下の公式ドキュメントをご覧いただき、権限を絞ることをおすすめします。
信頼関係のタブで、redshift と sagemaker を追加
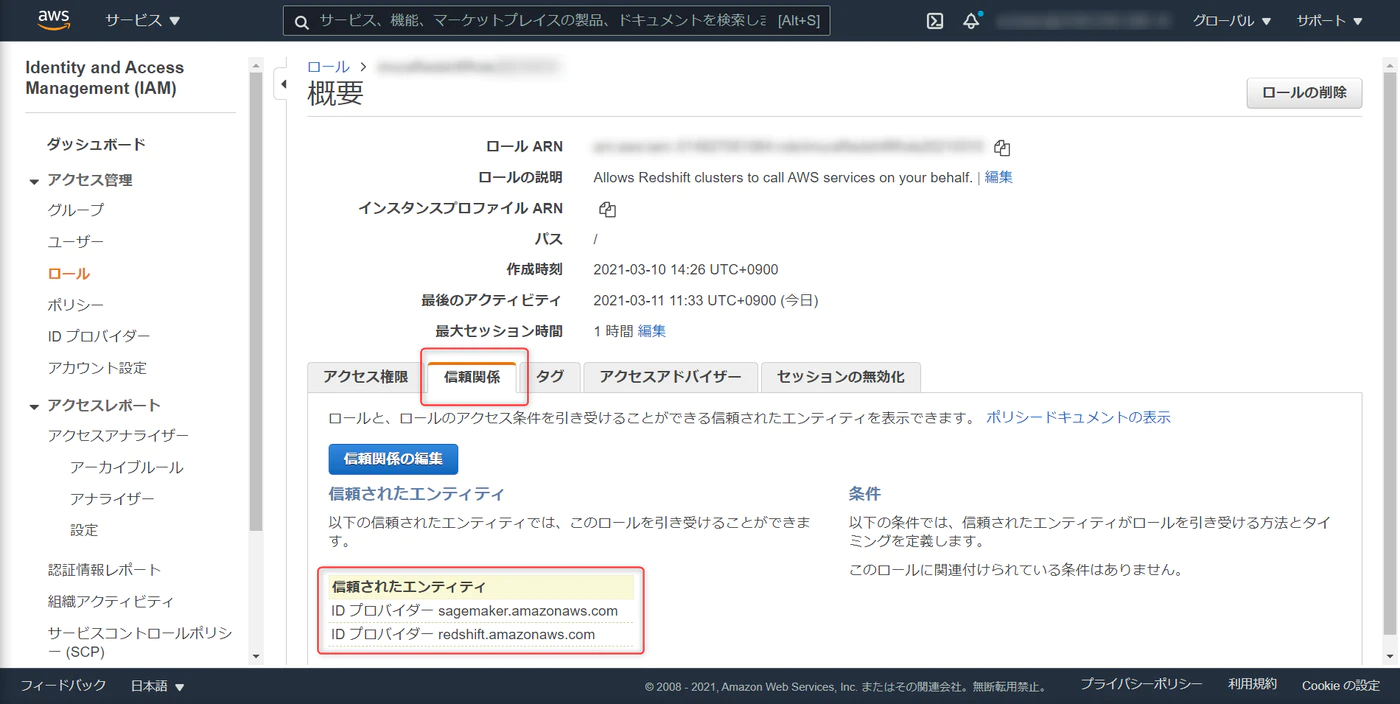
TrustedEntity
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com", "sagemaker.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] } |
これでRedshiftとSagemakerのサービスを信頼します。
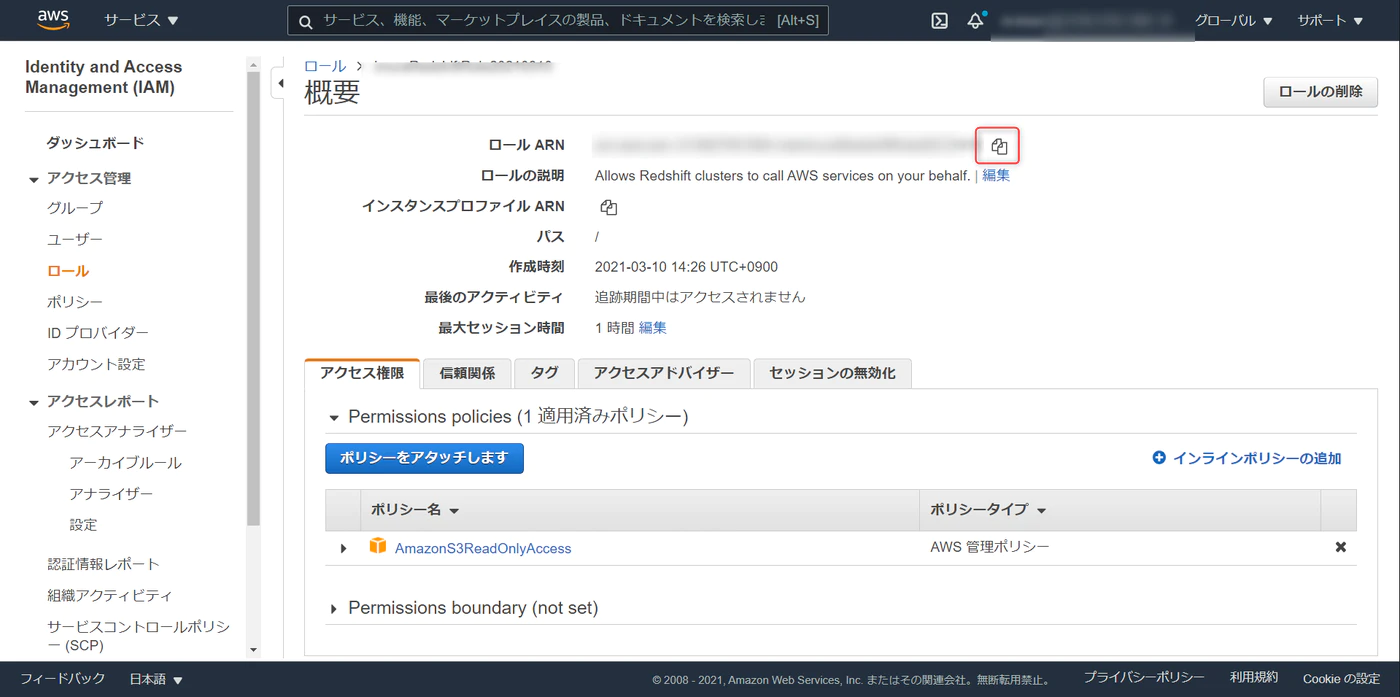
最後に iam role arn をコピーします。(Redshiftクラスタの構築で必要になります)
S3
今回はシンプルな構築にするため、以下の条件を満たす単一S3バケットを構築します。
- Redshift テーブル用データの保存
- Redshiftml Amazon S3 からデータを読み込むための Amazon ML アクセス許可の取得
- Amazon S3 に予測を出力するために Amazon ML のアクセス許可を得る
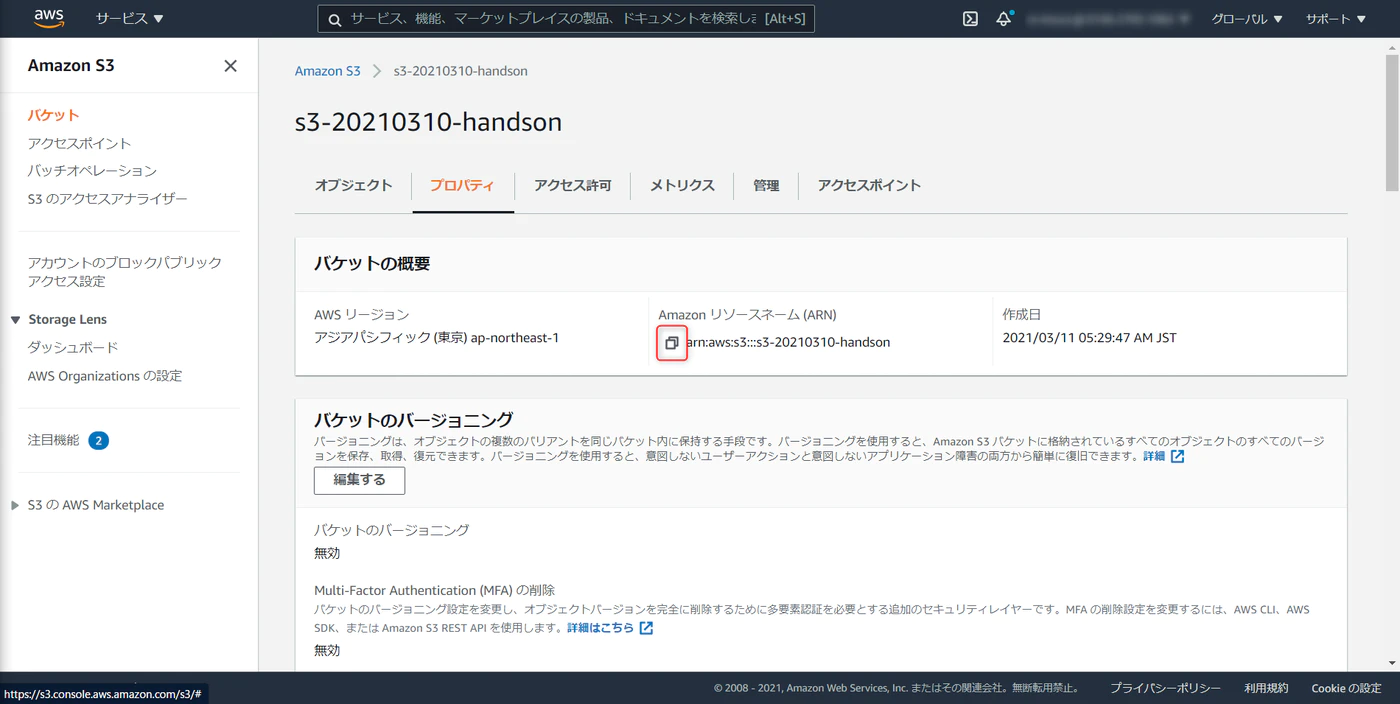
S3バケットをデフォルト値で構築、S3 ARN をコピーします。(こちらもRedshiftクラスタの構築で必要になります)
アクセス許可 > バケットポリシーと進み、Amazon Redshift と SageMaker Autopilot が利用できるように以下の通りバケットポリシーを変更します。
先ほど作成したロールをプリンシパルに設定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "Version": "2008-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "{iam-role-arn}" }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "{s3-arn}/*" }, { "Effect": "Allow", "Principal": { "AWS": "{iam-role-arn}" }, "Action": "s3:ListBucket", "Resource": "{s3-arn}" } ] } |
Redshiftクラスタ
Redshiftクラスタの構築に iam role arn と S3 ARN が必要です。
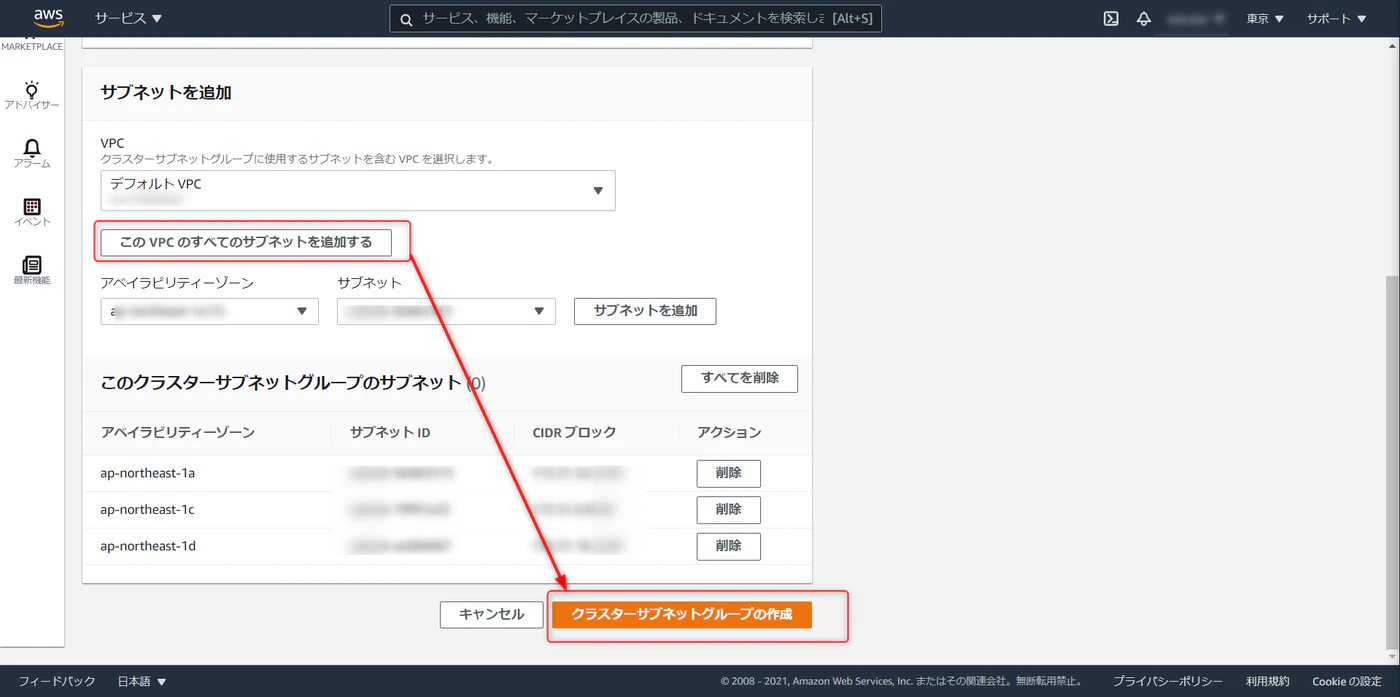
設定 > サブネットグループと進み、任意で名称を設定、VPC のすべてのサブネットを追加、クラスターサブネットグループの作成をクリックします。
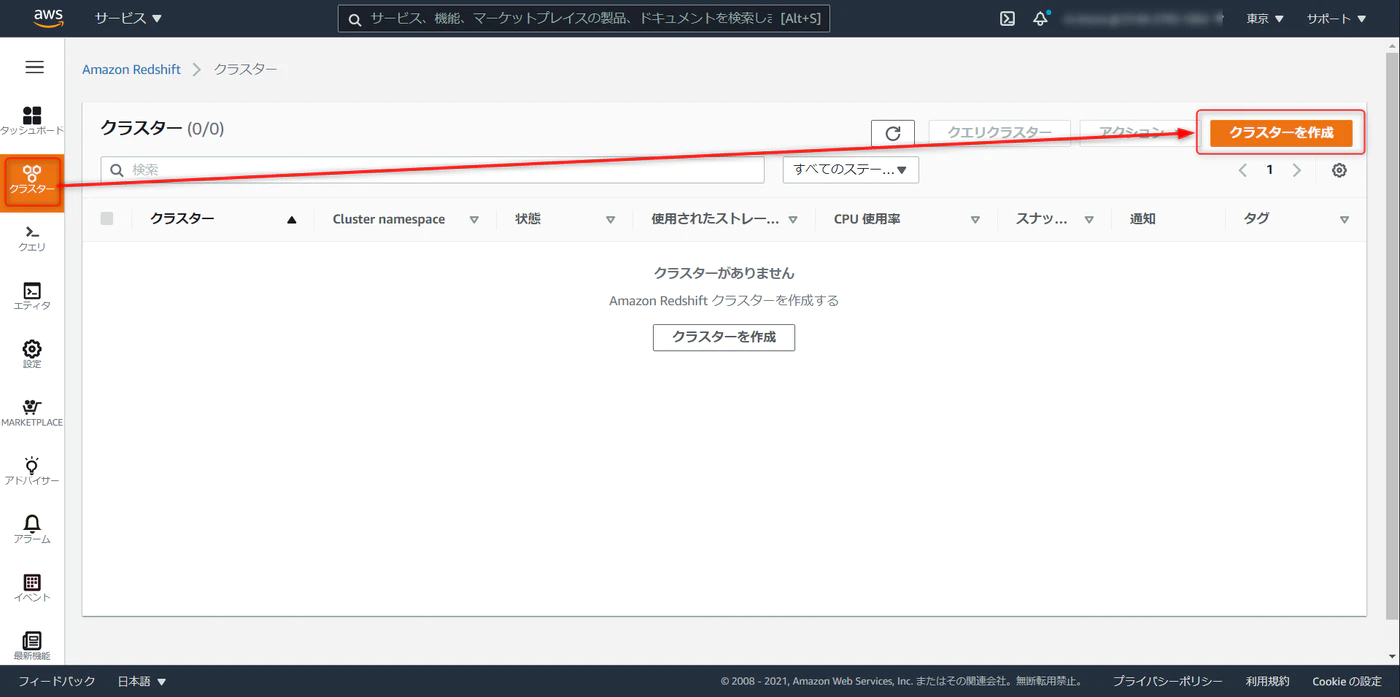
クラスタ > クラスタの作成
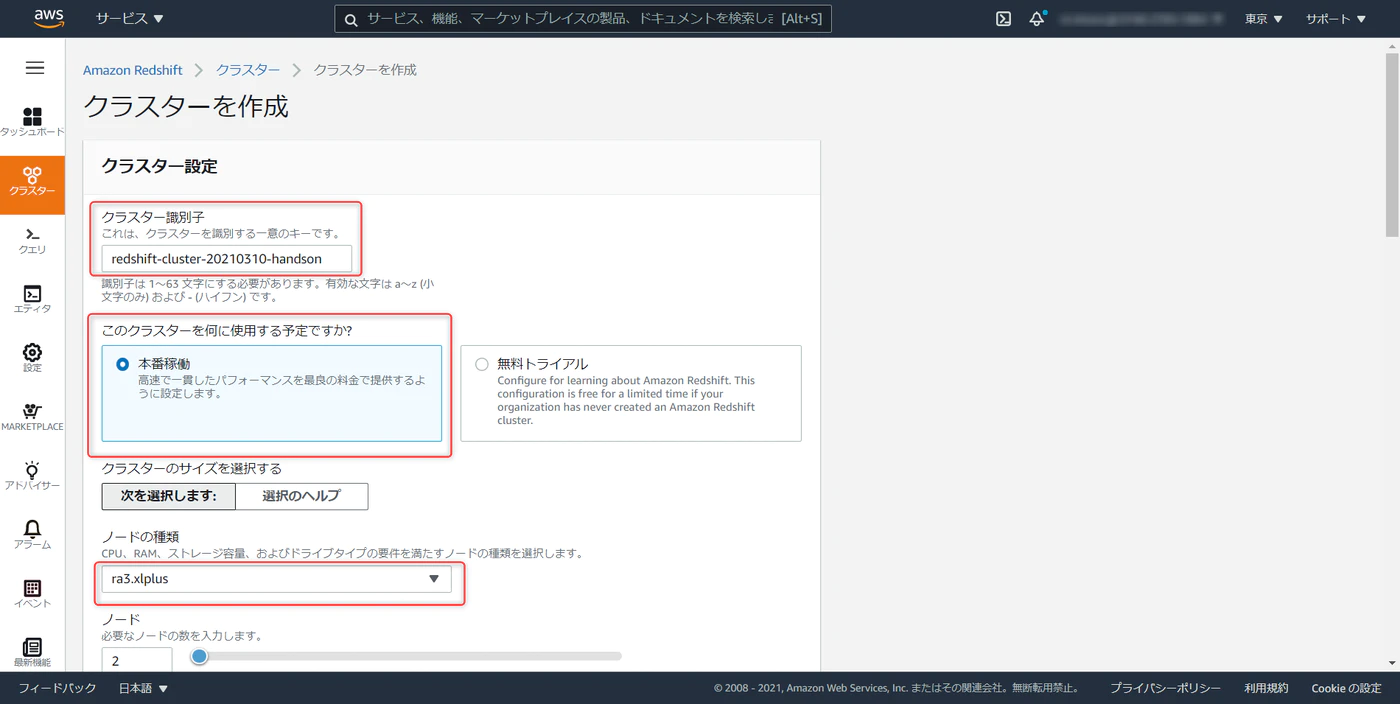
クラスタ識別子を任意で入力。dc2.large が最も安価なクラスタだが Redshift ML は対応していないので注意してください。 (2021年5月11日時点)
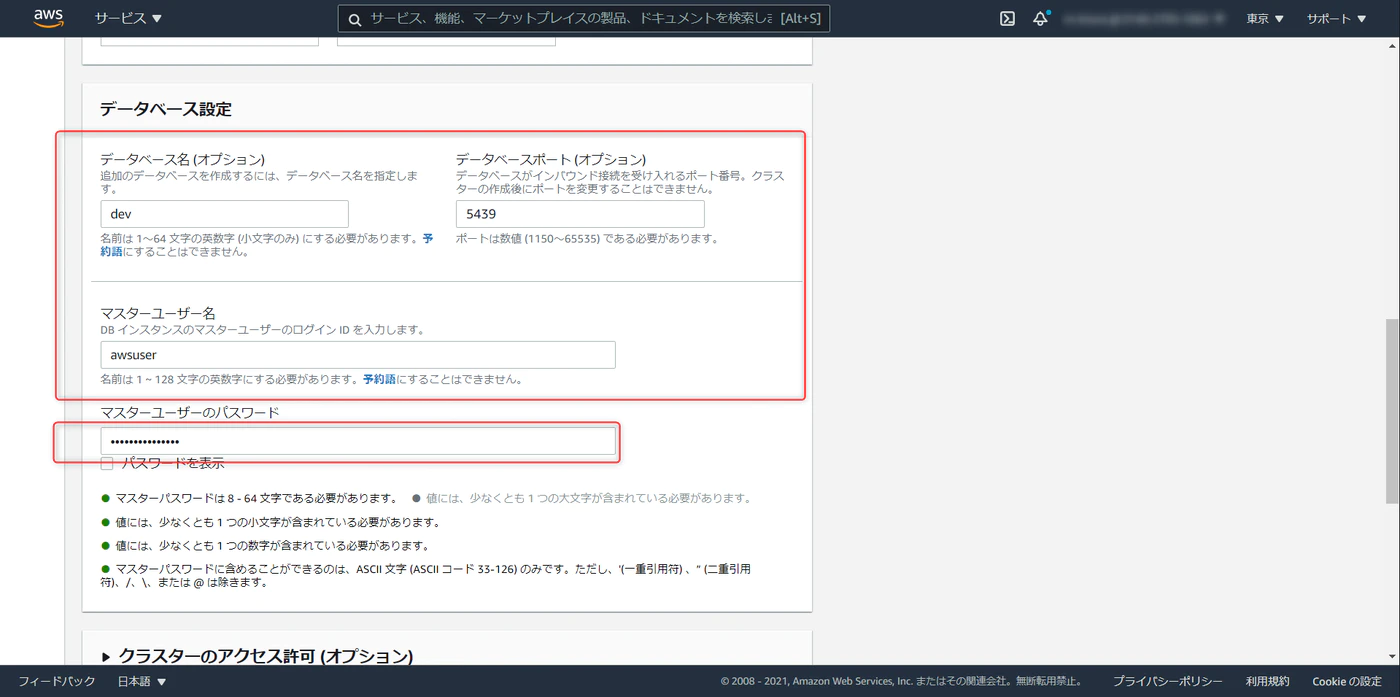
Database Name、Port、Master User Name はデフォルト値でOKです。
Password を任意で入力します。Master USer Name と Password を控えておいてください。(Redshiftにデータセットをアップロードするときに必要になります)
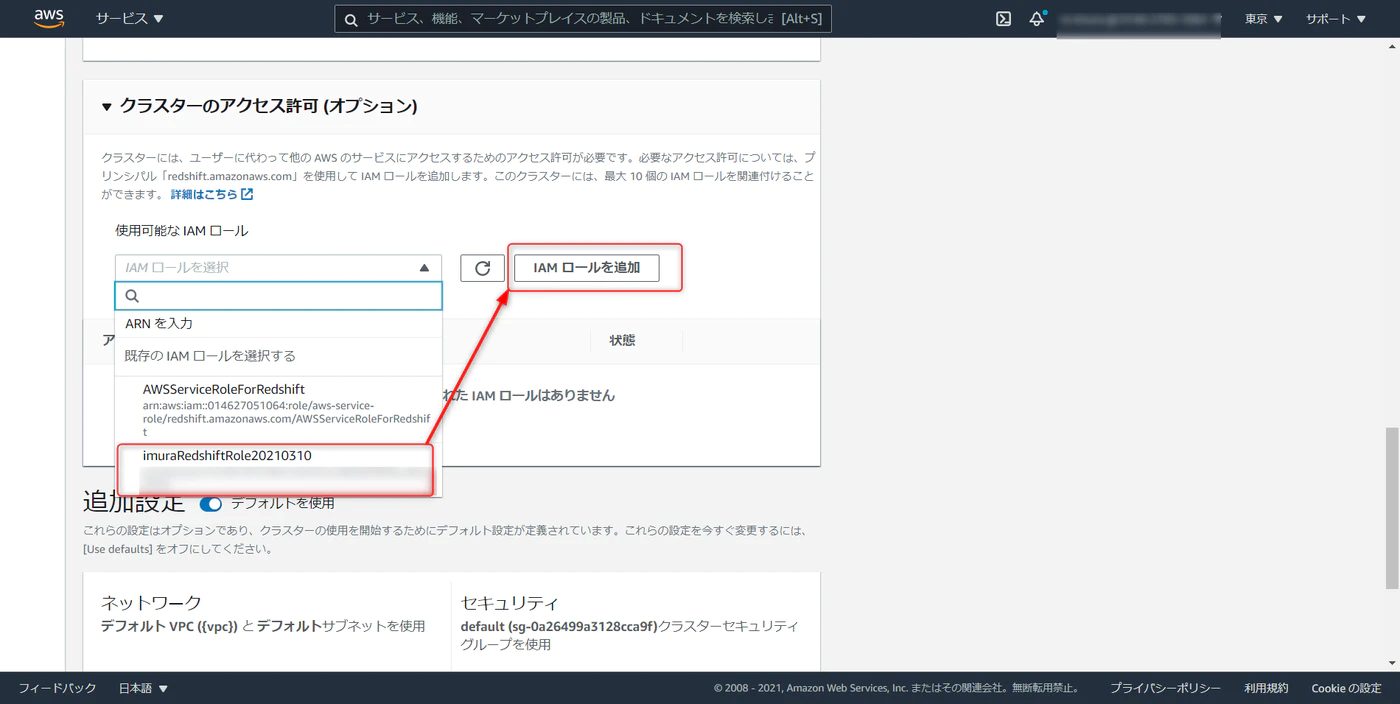
クラスタのアクセス許可から先ほど作成した IAM ロールの iam role arn を選択、「IAM ロールを追加」を選択します。
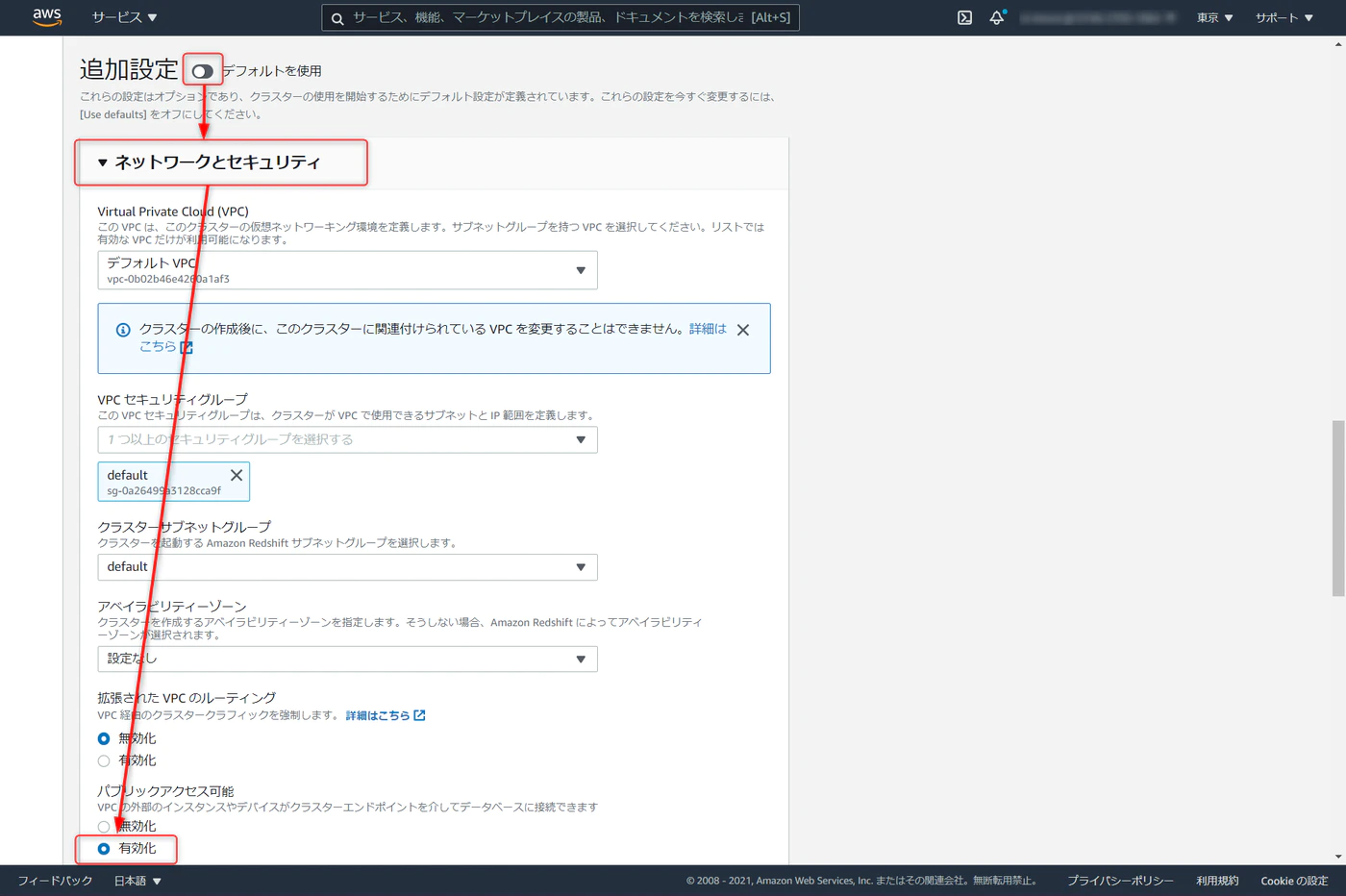
今回ローカルの SQL クライアントからクエリをたたく。追加設定のデフォルトを使用を解除し、ネットワークとセキュリティの項目で、パブリックアクセスの有効化にチェックを入れます。
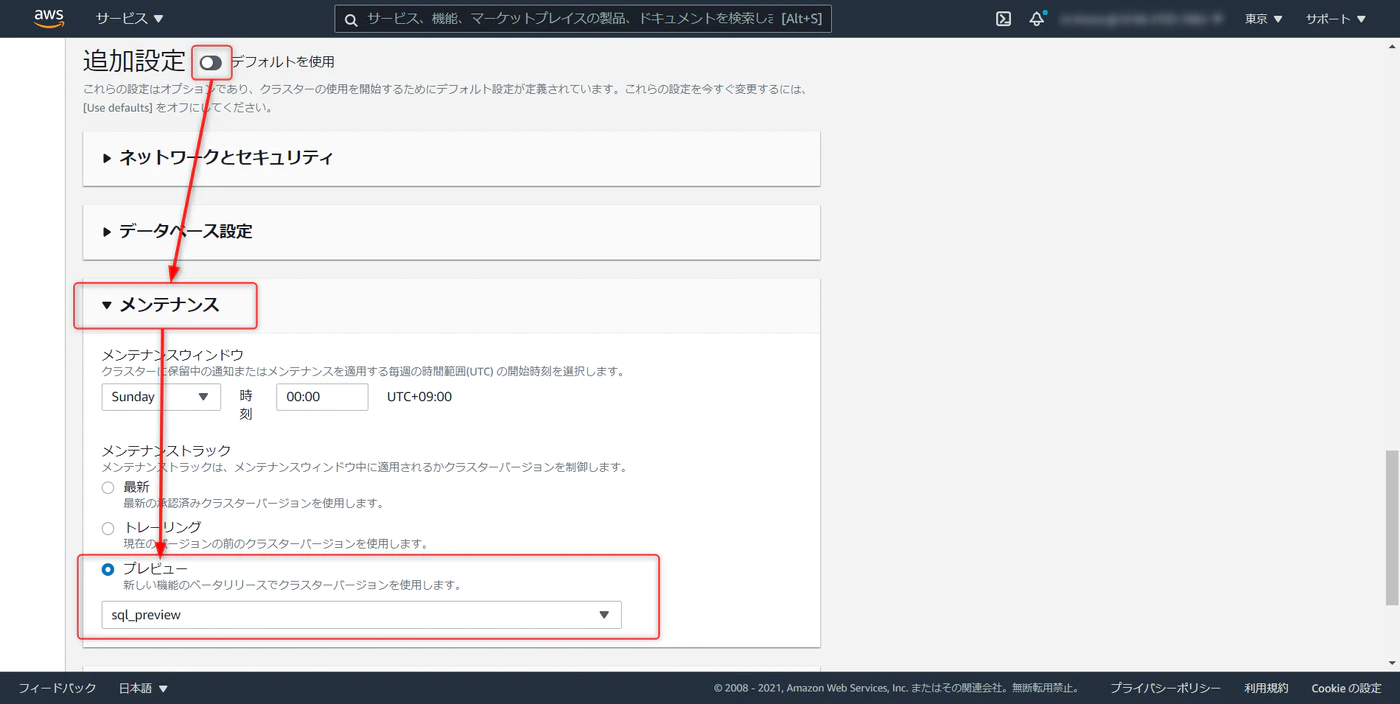
メンテナンスタブ > メンテナンストラックでプレビューの sql_preview を選択。ここまで設定が完了したらクラスタの作成へと進みます。
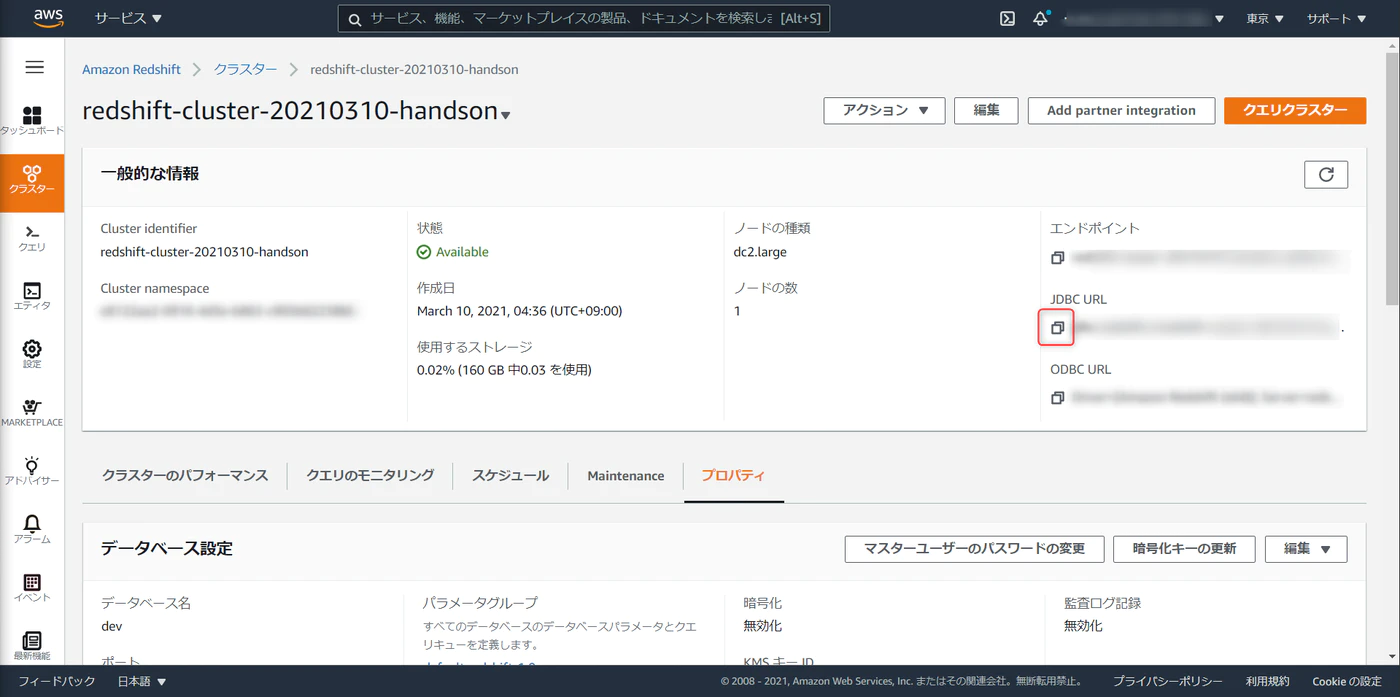
デプロイが完了したら、JDBC URL を控えておきます。
VPC
Redshift クラスタをインターネット経由で操作できるよう、ネットワークを構成します。
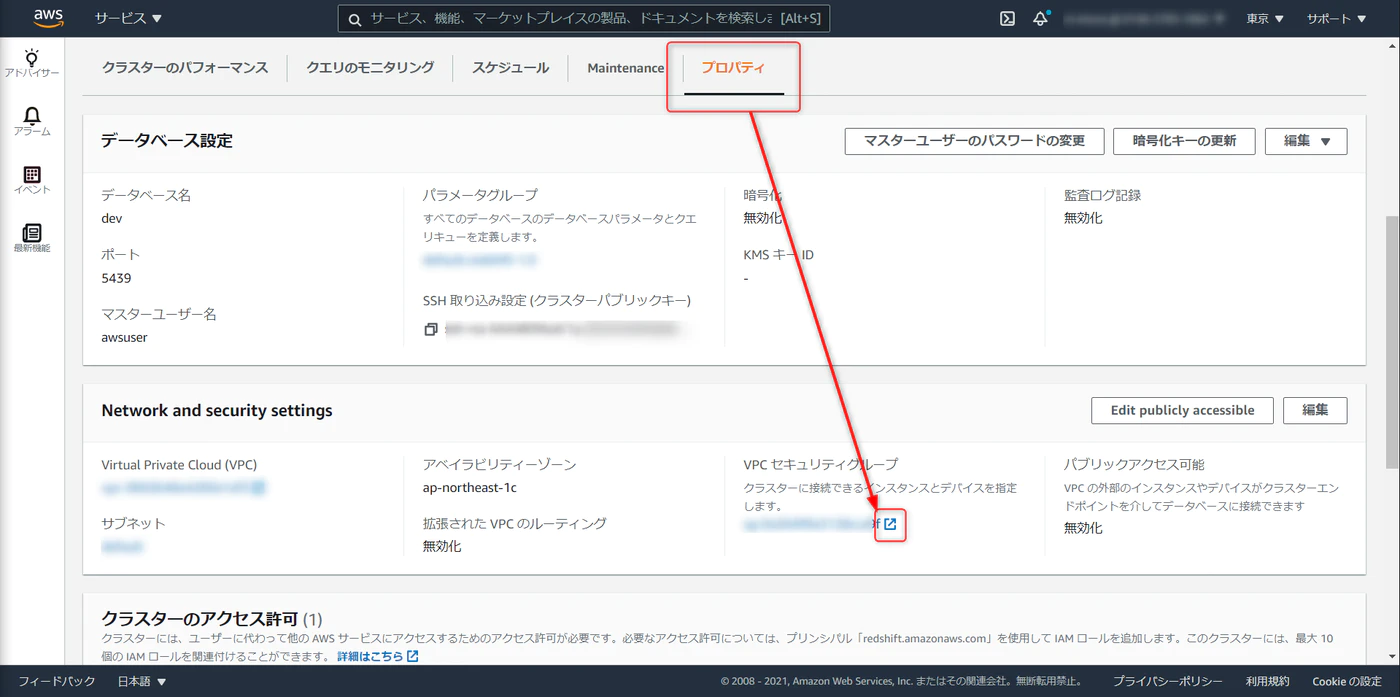
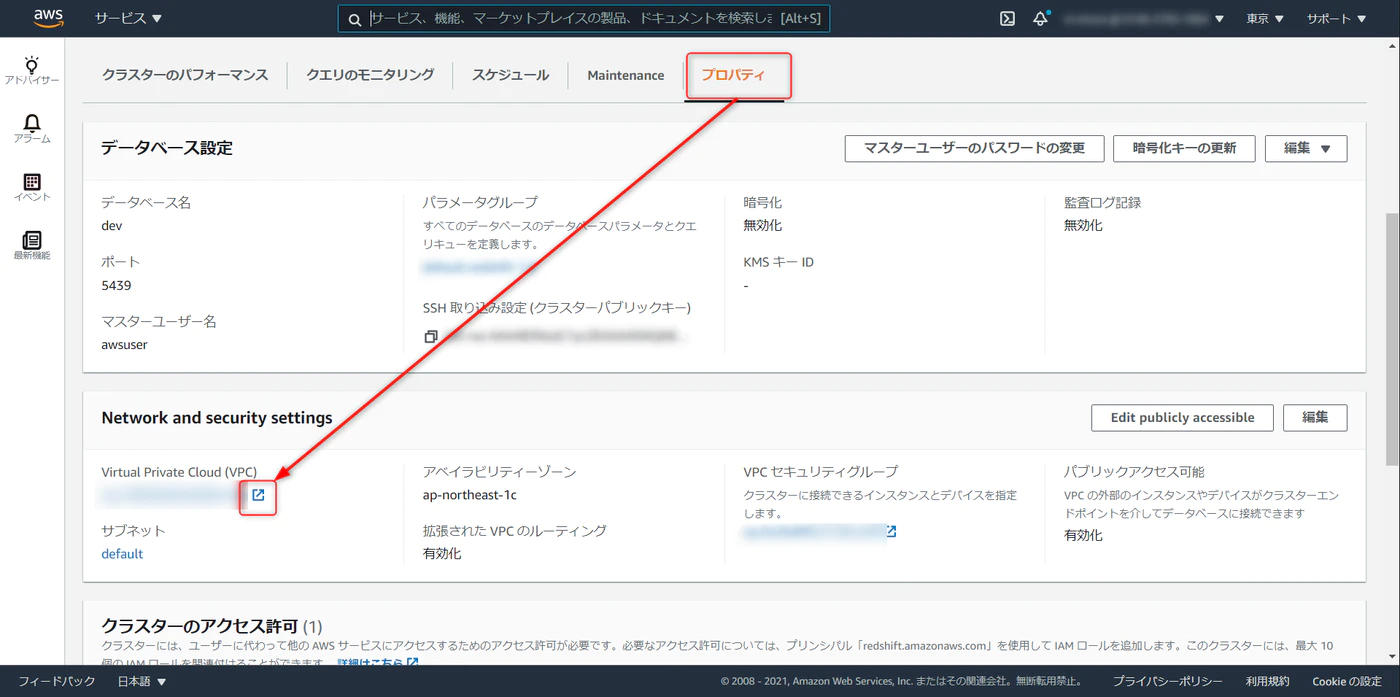
先ほど作成したクラスタのプロパティから、VPC セキュリティグループと進みます。
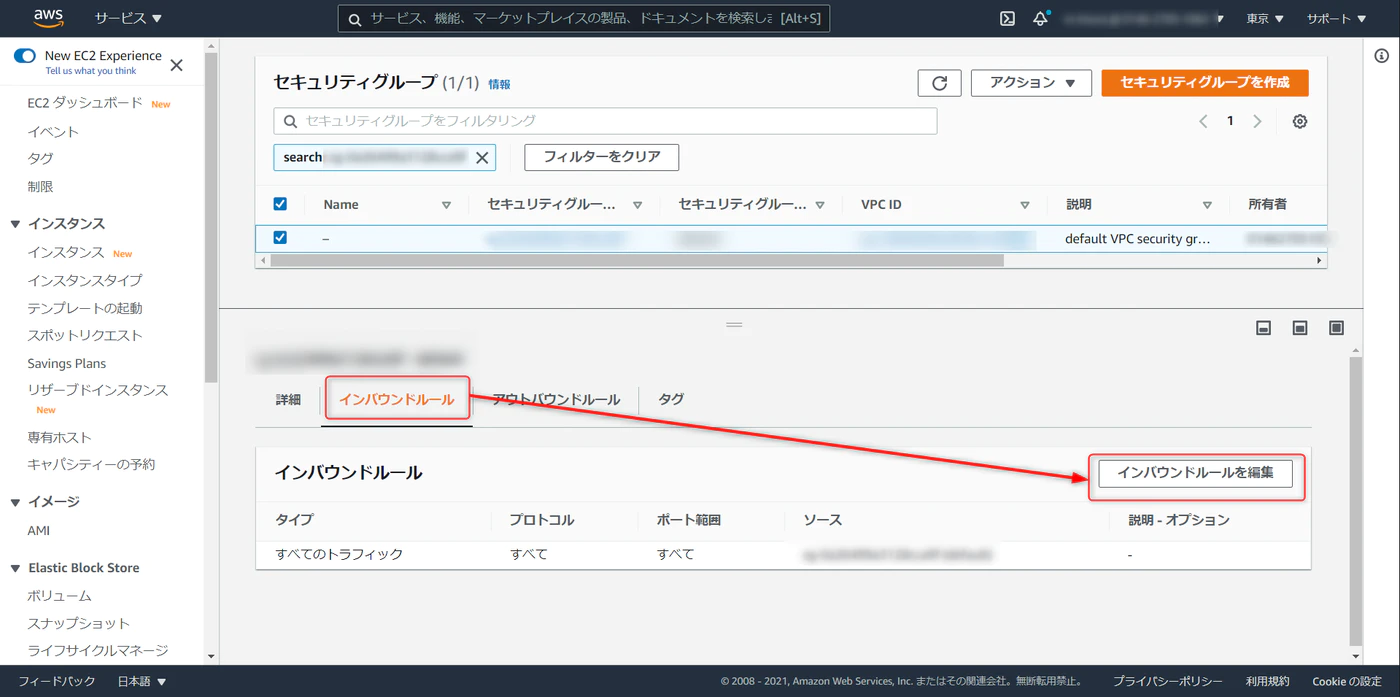
デフォルトだと下記の状態。インバウンドルール > インバウンドルールを編集
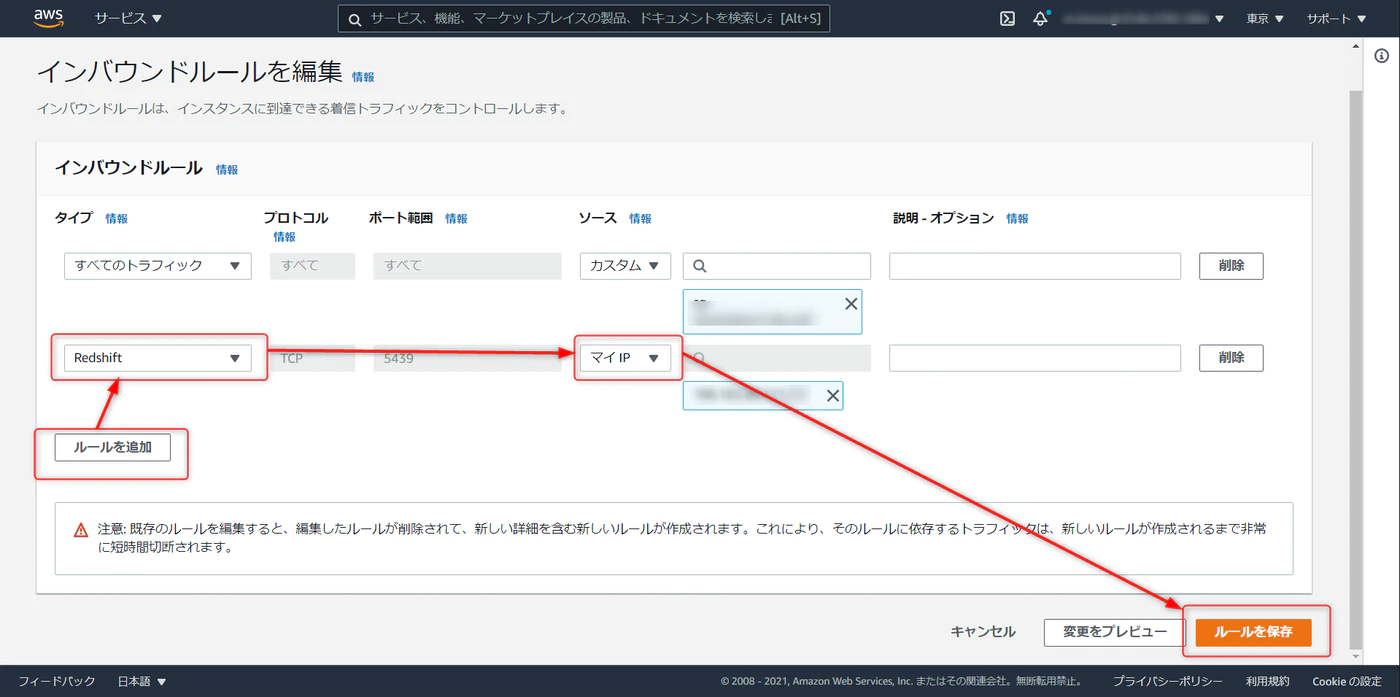
ルールの追加 > タイプを Redshift に選択 > マイIP と進み、ルールを保存をクリック。この作業でローカル環境から Redshift への接続が通るようになる。
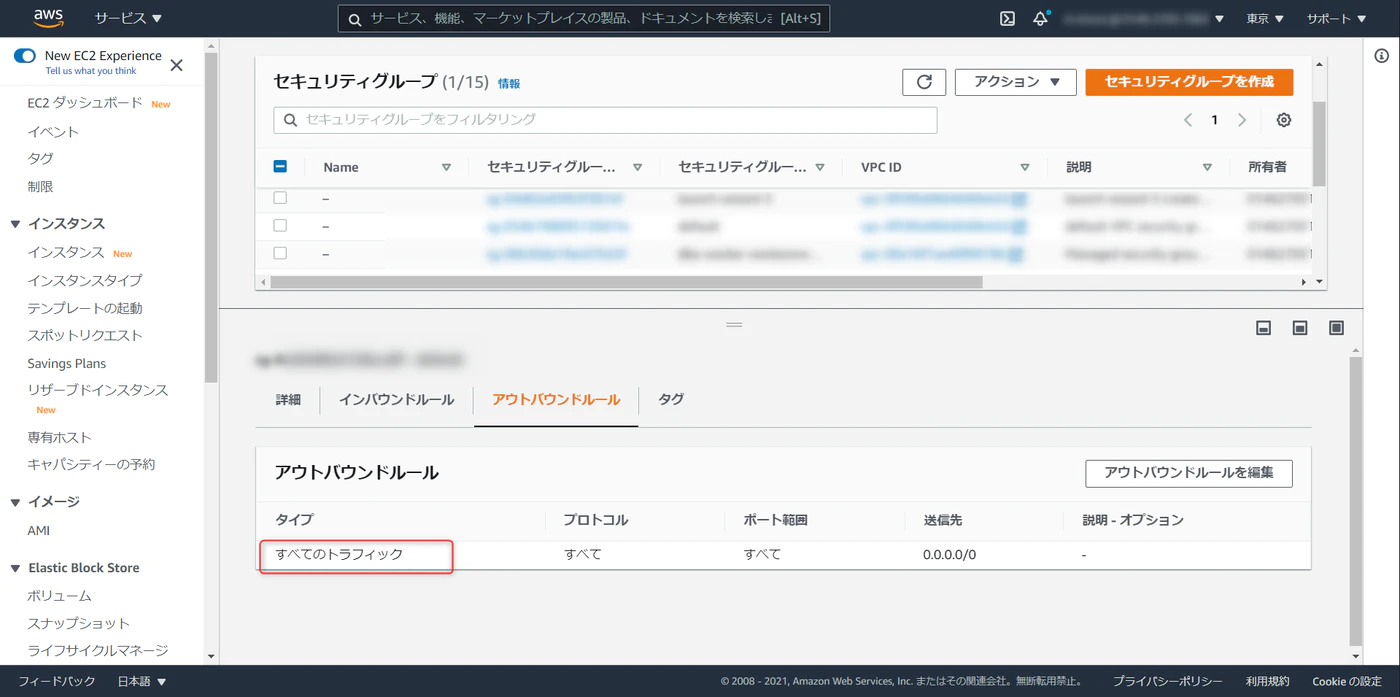
アウトバウンドルールが以下の状態になっていることを確認します。
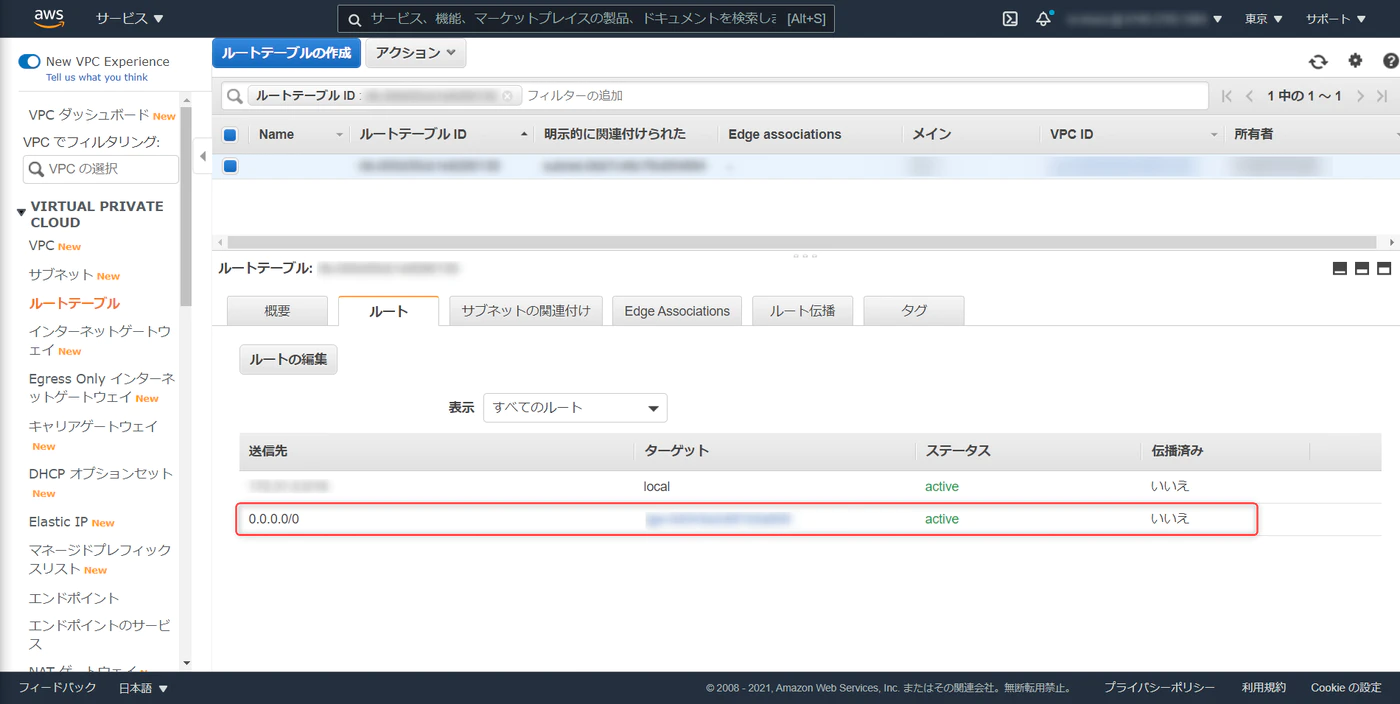
備考:Redshift クラスタの VPC サブネットのルートテーブルで、送信先 0.0.0.0/0 が blackhole になっている場合、SQL クライアントから接続する際、Connection Timeout が発生する。ルートの編集と進み、該当設定を再設定する


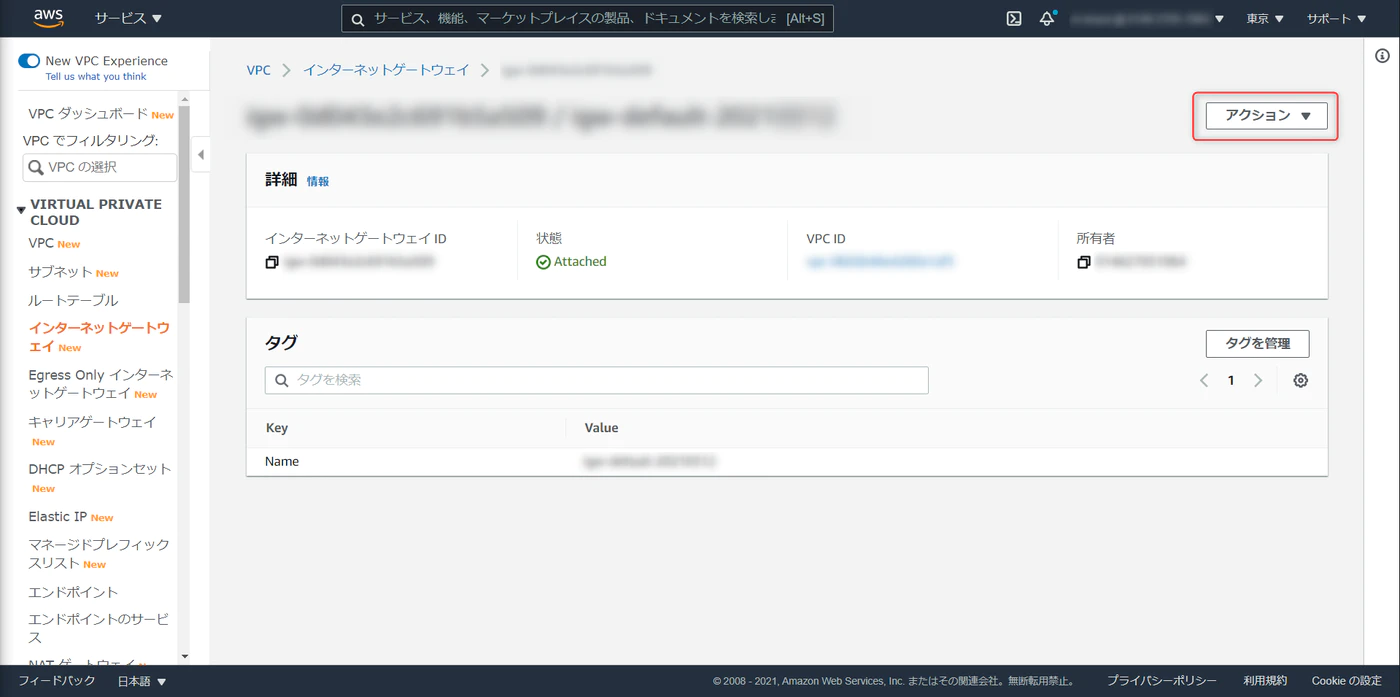
IGW(インターネットゲートウェイ)
インターネットに接続するためのゲートウェイがない場合は以下手順で構築します。
Redshift クラスタのプロパティから VPC と進み、別タブで開いておく
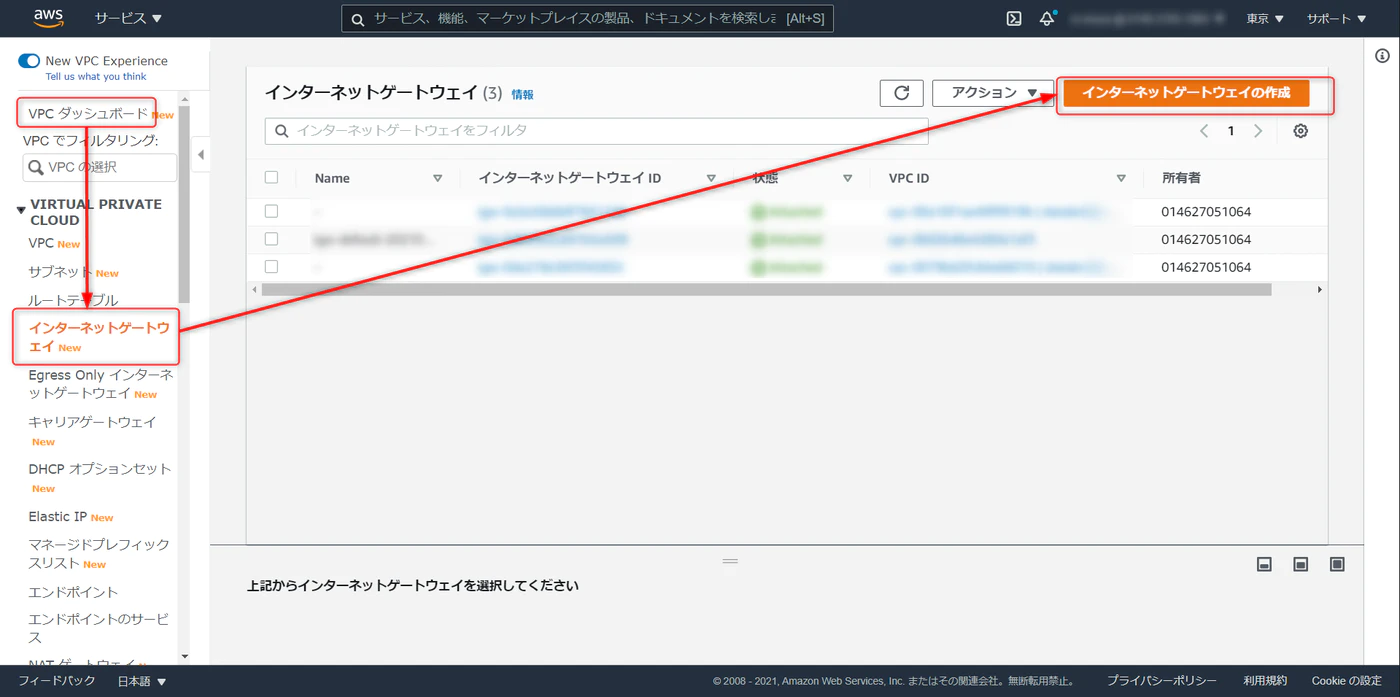
VPC ダッシュボード > インターネットゲートウェイ > インターネットゲートウェイの作成
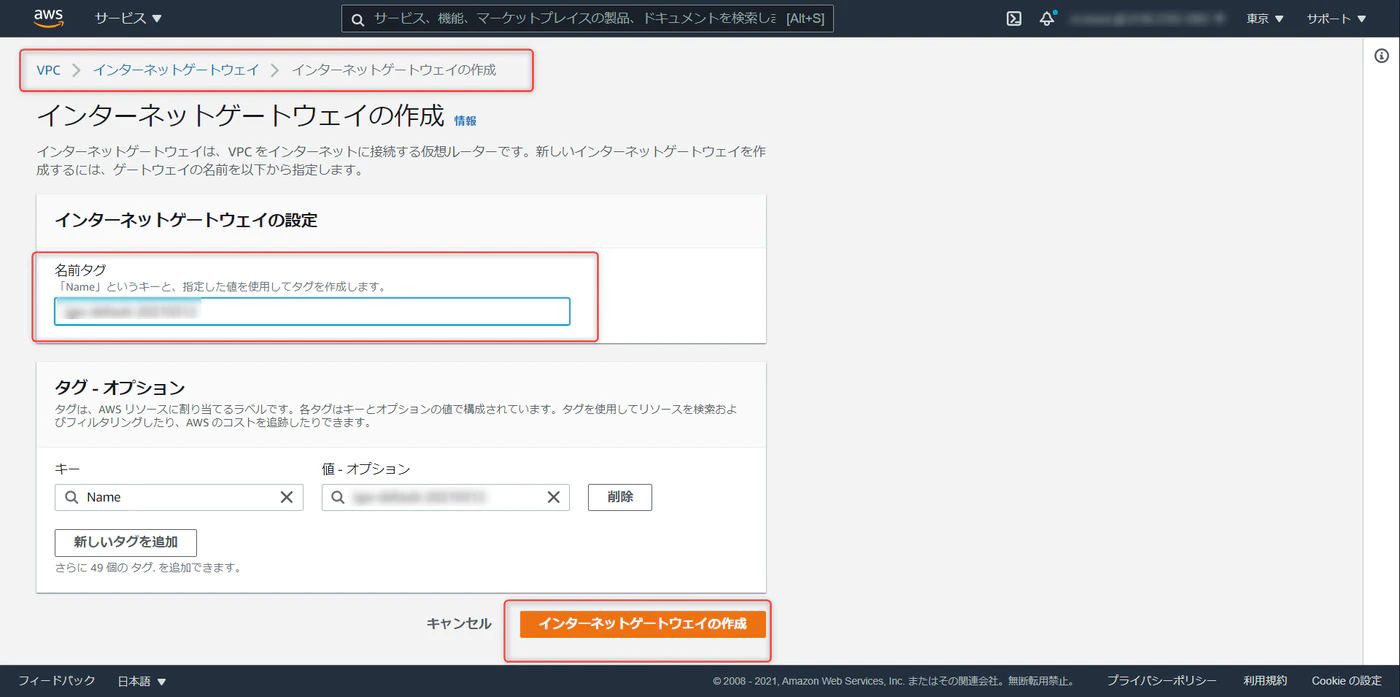
任意でゲートウェイの名称を入力、作成をクリックします。
作成したインターネットゲートウェイを Redshift クラスタが稼働しているVPCにアタッチします。
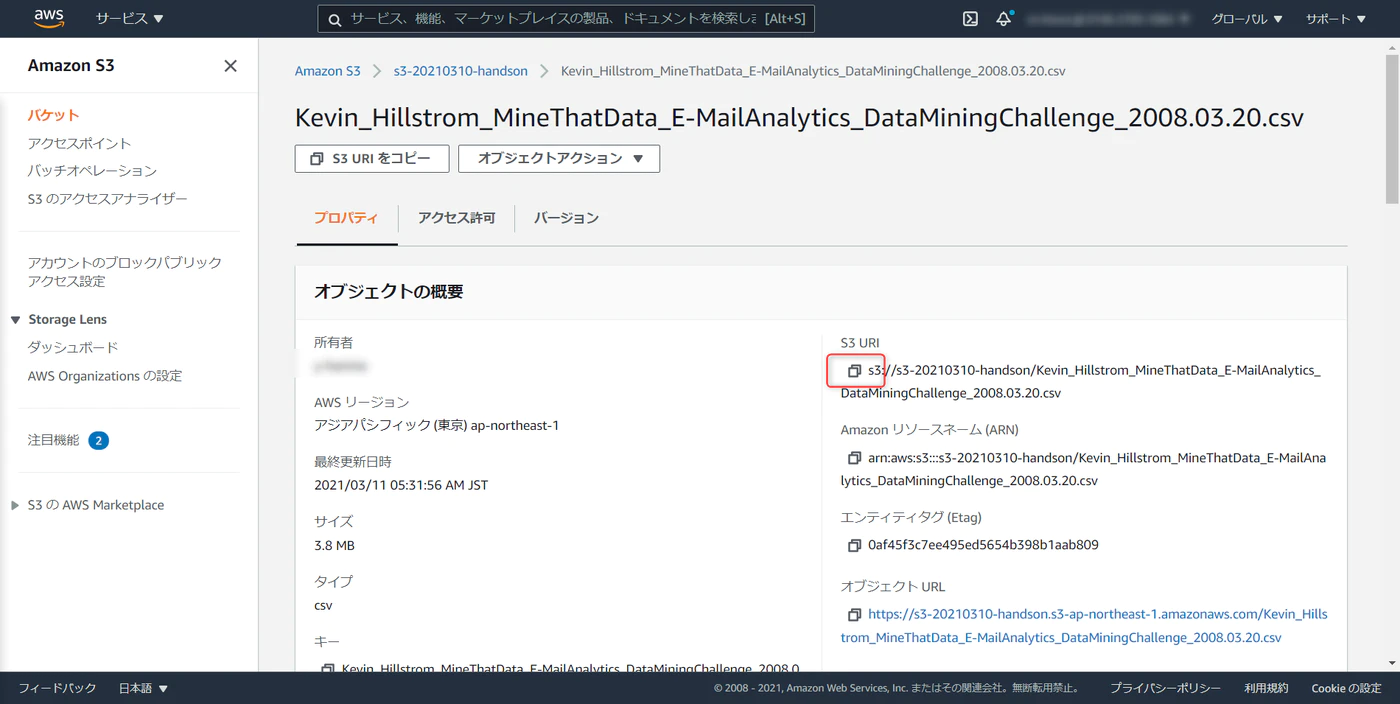
データセット アップロード
ダウンロードした CSV データを S3 にアップロード、S3 URI をコピーしておきます。
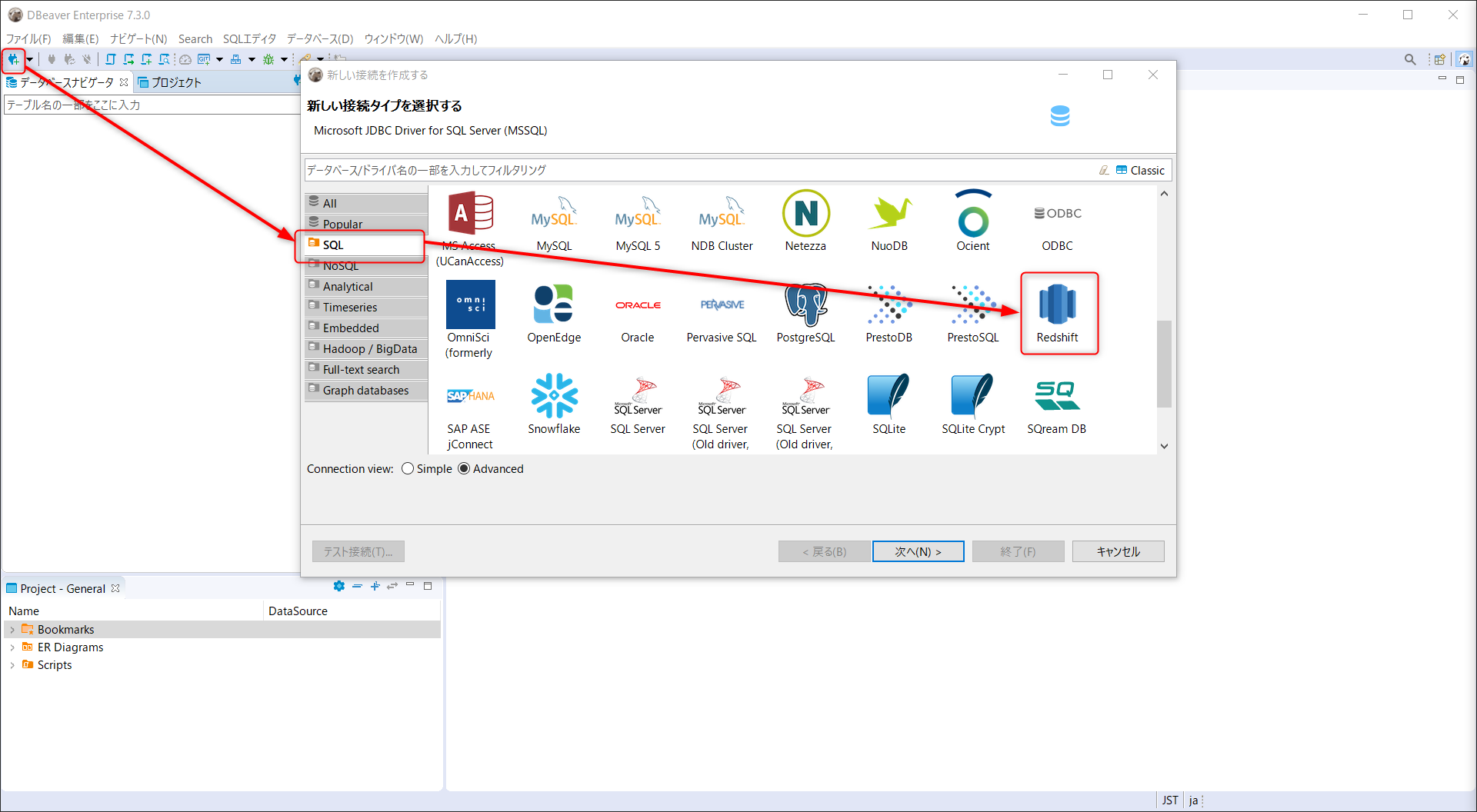
今回は SQL クライアントに DBeaver を用いる。
DBeaber をインストールしたら、新しい接続を選択、Redshift へと進む
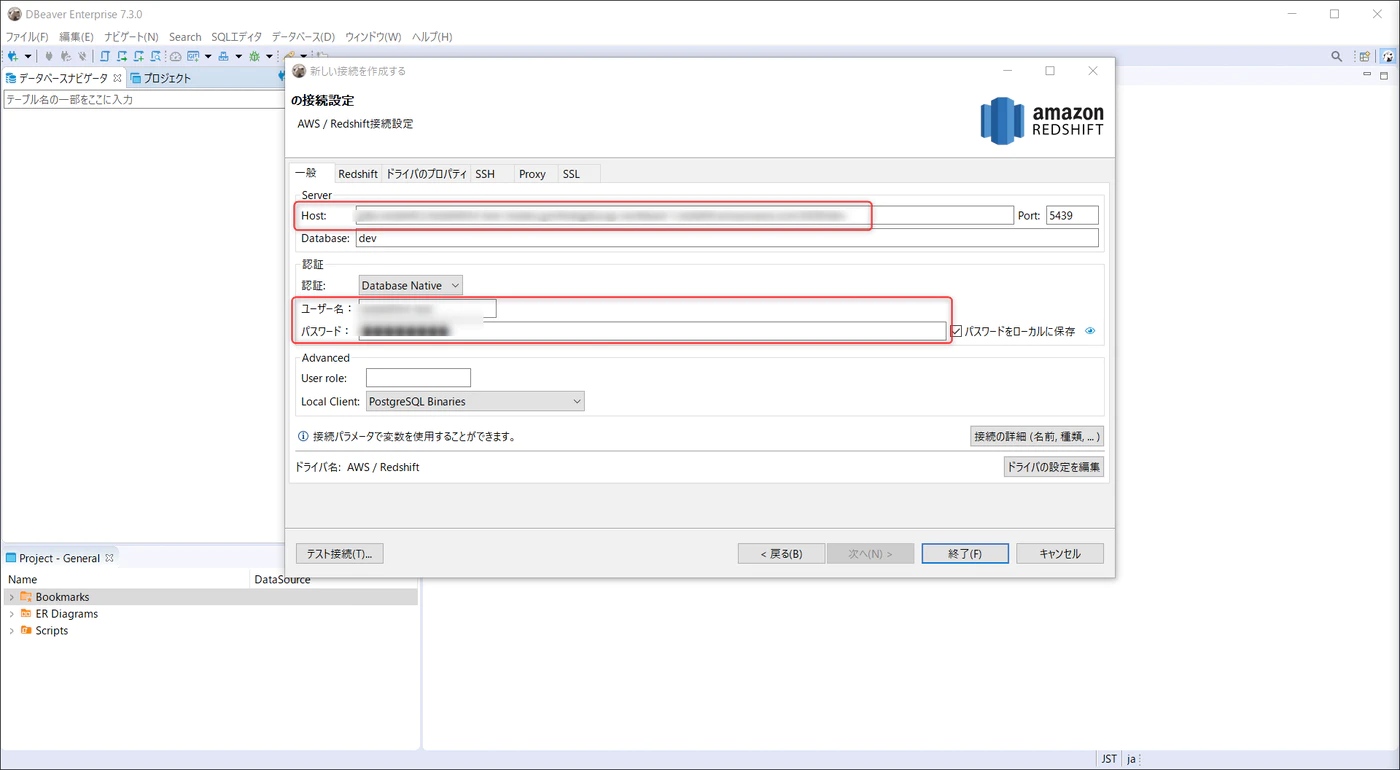
JDBC ホスト、Master USer Name 、 Password を入力し、終了をクリックします。
JDBC ホスト名は、JDBC URL から dbc:redshift:// と :5439/devを除いた文字列となるので注意!
まとめ
次の記事はこちらになります。
次の記事でRedshiftMLモデルの構築をやっていきたいと思います。
参考リンク
Amazon RedshiftMLの紹介記事です。
公式ドキュメント
