こんにちは!中の人です。
前回のレシピに引き続き、今回もAmazon Redshift編です!
前回は『Amazon Redshift編~複数ファイルを一括インポートしてみよう!~』ということで記述しました。
今回のレシピでは『Amazon Redshift編~圧縮ファイルをインポートしてみよう!~』と題して、圧縮のファイルのインポート方法について説明いたします。
それでは、さっそく作業をおこなっていきましょう!
サンプルは前回と同様に郵便番号のデータを利用します。
ただし、郵便番号のデータはlzhで圧縮されているので、一度解凍してgzipで圧縮する必要があります。
Windowsの場合、gzip形式に圧縮できるツールはgzip home page(www.gzip.org)など限られています。
事前準備
上記URLより全国一括「ken_all.lzh」をダウンロードし、解凍します。
解凍したファイルをテキストエディタで開き、UTF-8Nのフォーマットで保存します。
※日本語を扱う場合は必ずUTF-8Nで保存する必要があります。
1. 以下のコマンドでCSVファイルをgzip形式で圧縮します。
|
1 2 3 |
$ gzip [CSVファイルがあるディレクトリ]/KEN_ALL.CSV $ ls –l [CSVファイルがあるディレクトリ] -rwxrwxrwx 1 naka naka 2146160 5月 28 16:50 KEN_ALL.CSV.gz |
2. 出力したデータ(KEN_ALL.CSV.gz)をRedshiftと同じリージョンのS3に対してアップロードします。
テーブルの作成
ここからはRedshiftに対する操作です。
前回のレシピ同様、SQL Workbenchを起動させ、Redshiftに対して接続します。
3. 郵便番号情報用にテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
create table postcode( dancode varchar(10), oldpost varchar(5), newpost varchar(7), state_kana varchar(200), city_kana varchar(200), area_kana varchar(300), state_kanji varchar(200), city_kanji varchar(200), area_kanji varchar(300), etc01 boolean , etc02 boolean , etc03 boolean , etc04 boolean , etc05 smallint, etc06 smallint ); |
※全国データではカラムがサイズが足りなかったため、一部変更しています。
データのインポート
|
1 |
copy postcode from 's3://[s3-backet名]/KEN_ALL.CSV.gz' CREDENTIALS 'aws_access_key_id=[your access key];aws_secret_access_key=[your secret access key]' delimiter ',' removequotes GZIP; |

○前回との変更点
copy [インポート先のtable] from ‘[圧縮ファイルのパス]’ delimiter ‘,’ removequotes GZIP; インポートするファイルが圧縮形式であることを指定します。
データの確認
4. データの確認として以下を実行してみます。
|
1 |
select * from postcode where state_kanji = '東京都' |
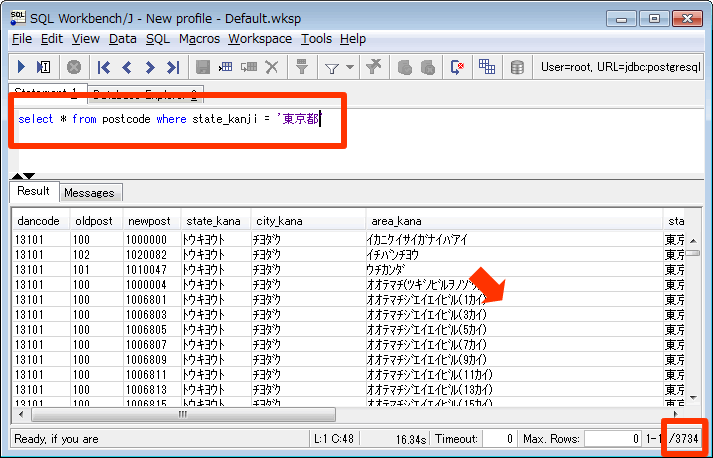
東京都の登録データ 3734件がヒットしたことが確認できます。
いかがでしたでしょうか?
圧縮ファイルのインポートもよくおこなう作業かと思いますので是非、確認してみてください!
次回は「Amazon Redshift~データをインポートしてみよう!(エラー編)~」と題して、いくつかのエラーとその対処方法について紹介します。
お楽しみに!
