こんにちは!中の人です。
前回までのレシピでは、Redshiftに対して様々な環境下でのパフォーマンス比較をおこなってきました。
■ Amazon Redshift編~複数クエリ同時実行時パフォーマンス比較(シングル)~
■ Amazon Redshift編~複数クエリ同時実行時パフォーマンス比較(マルチ)~
■ Amazon Redshift編~複数クエリ同時実行時パフォーマンス比較(XL vs 8XL)~
■ Amazon Redshift編~複数クエリ同時実行時パフォーマンス比較 (まとめ)~
■ Amazon Redshift編~パフォーマンス比較(MySQL vs Redshift)前編~
■ Amazon Redshift編~パフォーマンス比較(MySQL vs Redshift)後編~
今回は『Amazon Redshift編~パフォーマンスチューニング sortkey編~』と題して、Redshift自体のチューニングについて紹介します。
Redshiftのチューニング方法
Redshiftをチューニングする方法としてはRedshiftリファレンスにもあるように以下の様になっています。
・ 最適なsort keyの選択
・ 最適なdistribution keyの選択
・ 最適な圧縮方法の選択
・ 制約(constraints)の定義
ただし、最後のconstraintsについては、「unique」など登録(指定)できるものと利用できないものとがあります。
そのため、uniqueを設定しても重複データとしてエラーは出ずにそのまま登録ができてしまいます。
将来的なサポートを踏まえて登録を行なっていく方がいいと思われます。
Sort key設定によるチューニング
今回はsort keyの設定によるチューニングをおこないます。
|
1 |
select avg(column01) from SAMPLE_TABLE where column01>5000 and date like '13-06%' |
上記のクエリで、下記をsortkeyに設定して速度を比較してみます。
・ auto incrementされているid
・ 条件に使われているcolumn01
・ 条件に使われているdate
・ 条件に使われているcolumn01とdate
sortkeyの設定方法ですが、以下の様にcreateに続けて記載します。
|
1 2 3 4 5 6 |
create table SAMPLE_TABLE ( id int, ・・・ date timestamp ) sortkey(id); |
2013年7月現在、alter tableによる変更が出来ないため、新たにテーブルを作成するか、カラムを一旦削除 ⇒ 追加して設定、のいずれかの方法となります。
なお、テーブルのクリエイトおよびcopy(load)についてはどの方法でも差はありませんでした。
テスト結果
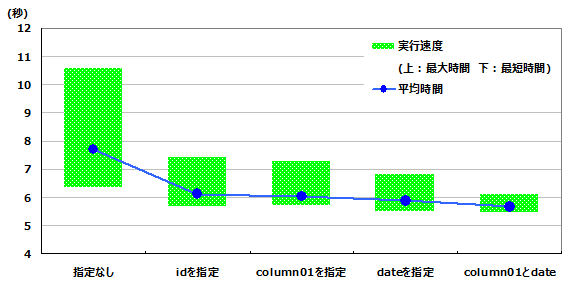
■ 約4000万行(10回平均)
≪ XLノード : sortkey指定なし≫
| 指定なし | idを指定 | column01を指定 | dateを指定 | column01とdate | |
|---|---|---|---|---|---|
| 平均実行速度(秒) | 7.71 | 6.12 | 6.04 | 5.89 | 5.66 |
| 最高実行速度(秒) | 6.37 | 5.69 | 5.72 | 5.51 | 5.47 |
| 最低実行速度(秒) | 10.57 | 7.43 | 7.26 | 6.82 | 6.08 |
いかがでしたでしょうか?
sortkeyの張り方でこのようにパフォーマンスが変わってきます。正しいsortkeyを設定することで、パフォーマンスの向上が確認できます。
今回のケースでは、sortkeyに向いているidよりも、検索対象となっているcolumn01, dateを指定することで、パフォーマンスが上がることが確認できました。 また、複数指定によって更にパフォーマンスが上がることも確認できました。
次回は『Amazon Redshift編~パフォーマンスチューニング distkey編~』と題して、distribution keyの設定によるパフォーマンスを比較していきます。お楽しみに!
——————————————————————————————————
ナレコムクラウドのFacebookに『いいね!』をクリックして頂くと
最新のお役立ちレシピが配信されます★
┏━━━━━━━━━━━━━┓
┃ナレコムクラウド Facebook┃
┗━━━━━━━━━━━━━┛
——————————————————————————————————
