こんにちは、Michaelです。
今回は、re:Invent 2016で発表されたAWSの画像認識サービス「Amazon Rekognition」をコンソールのデモで試して
みます。今回は特にオブジェクト・シーン認識の精度を検証していきます。
デモの内容
Amazon Rekognitionのデモでは
「Object and scene detection」、「Facial analysis」および「Face comparison」の
3つの画像認識を試すことができます。
デモの内容は以下のようなものになっています

いずれも、デモ用のサンプル画像が用意されており、すぐに画像認識を確かめることができます。
また、手持ちのデータやインターネット上の画像リンクを使って画像認識させることもできます。
オブジェクト・シーン認識のデモ
それでは、Amazon Rekognitionのデモを使ってみます。
現在、Amazon Rekognitionが利用できるのはバージニア、オレゴン、アイルランドの3リージョンのみのため、
いずれかのリージョンに移動して「人工知能(Artificial Intelligence)」カテゴリの「Rekognition」を
クリックします。
Rekognitionのデモは画面左の「Demos」から利用することができます。

今回は「Object and scene detection」でオブジェクト・シーン認識を試してみます。
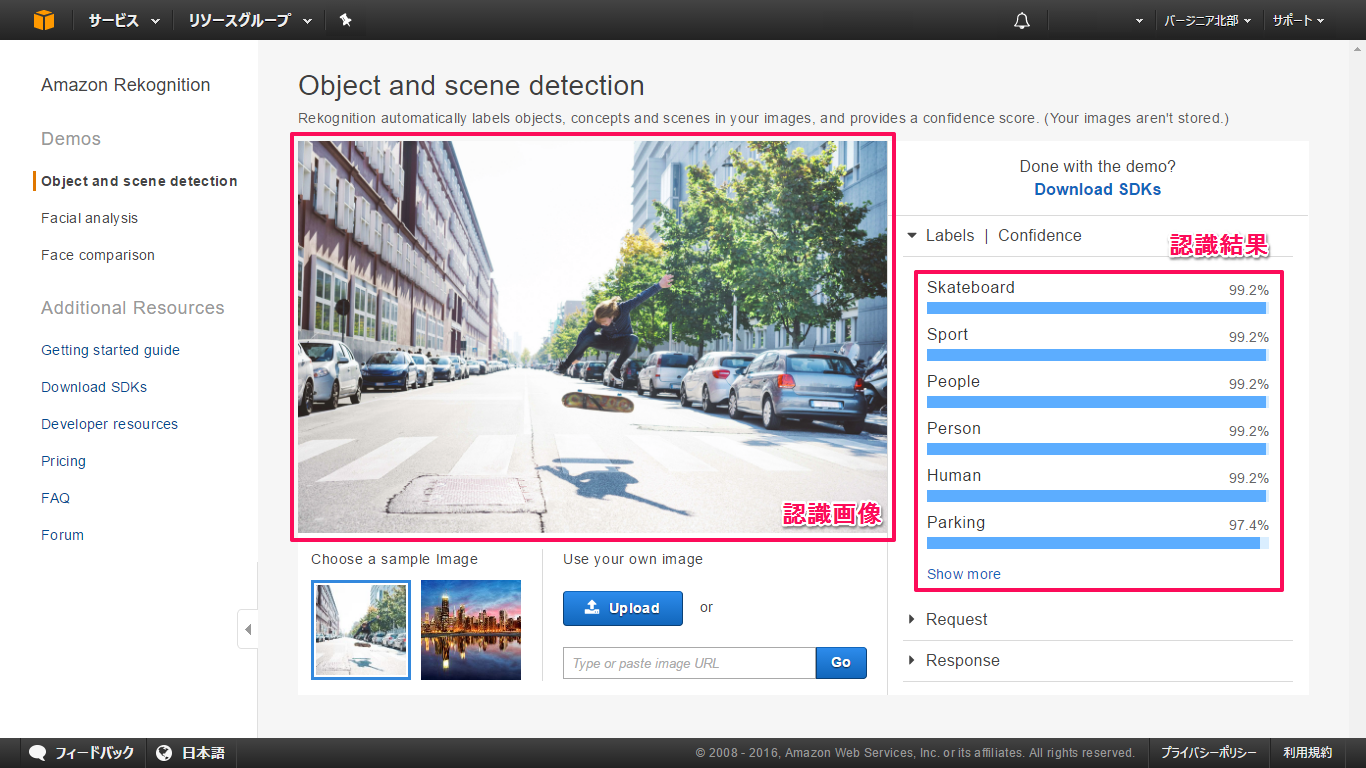
デモ画面に移ると、AWSが用意しているサンプル画像とその認識結果が初めに表示され、認識させている画像と認識結果がその右に表示されます。
サンプルでは、通りでスケートボードをしている男性の画像が使われており、「Labels | Confidence」(認識結果)には、確かに「Skateboard (スケートボード) / 99.2%」や「Human (ヒト) / 99.2%」、「Parking (駐車) / 97.4%」など
画像内の事象をとらえられていることが分かります。
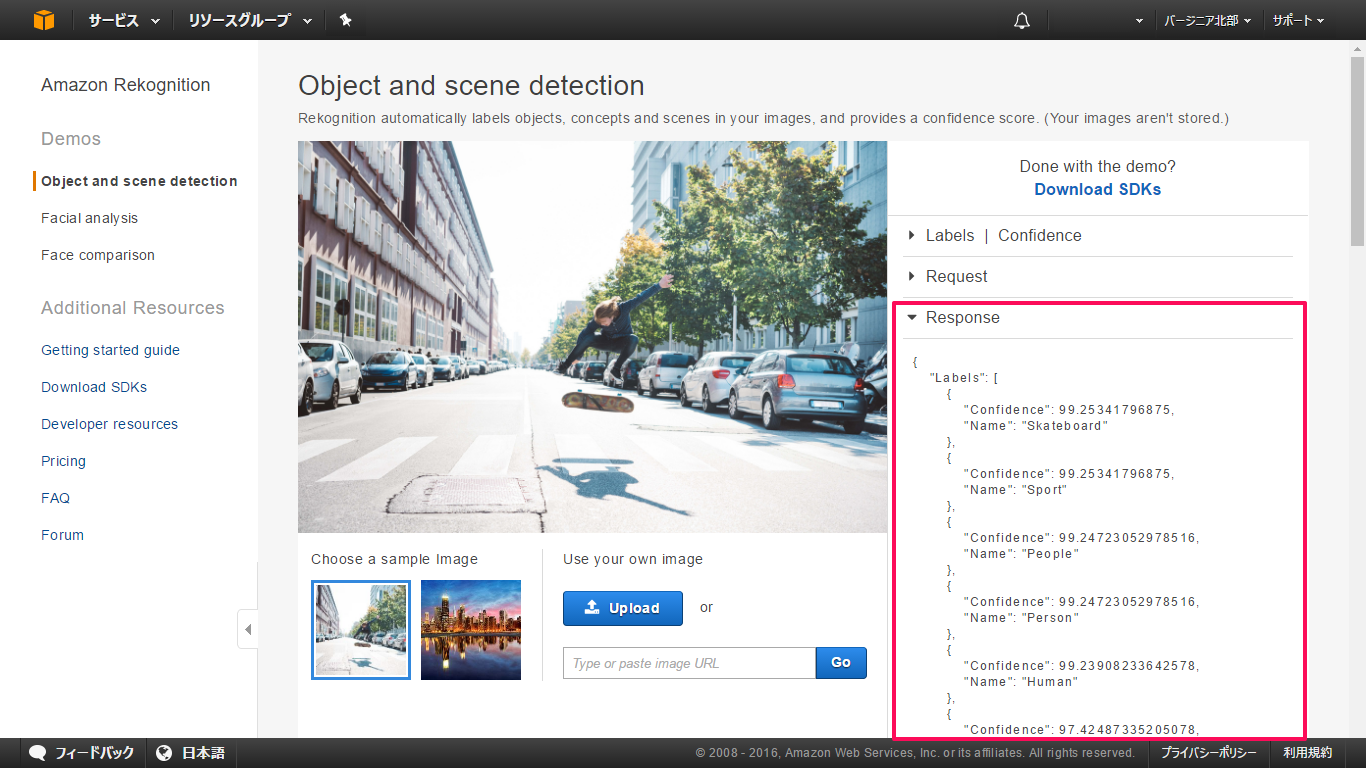
また「Labels | Confidence」の下にある「Response」では、APIを使用した場合に得られるレスポンスが表示され、
認識したオブジェクトの内容とその確度がJSON形式で出力されていることが分かります。
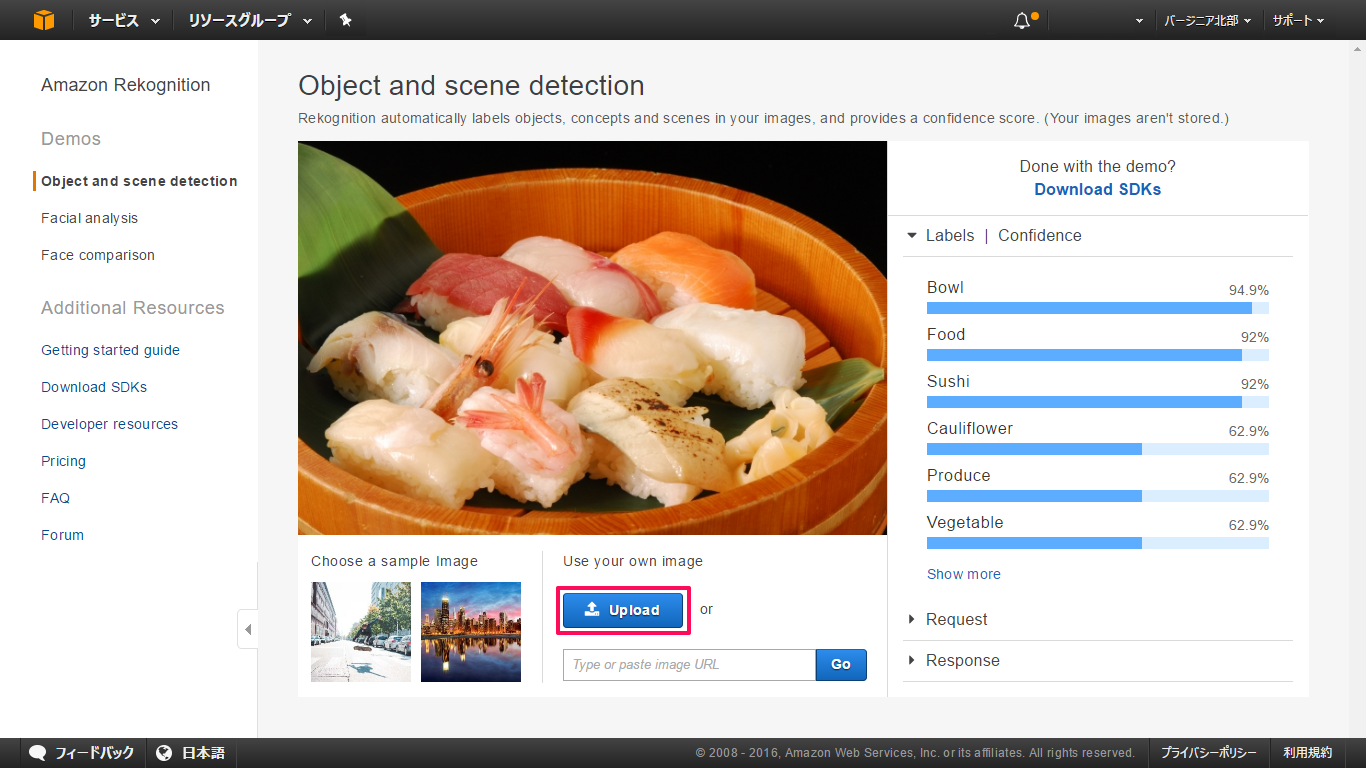
手持ちの画像を認識させる場合は、画像右下の「Upload」をクリックして、画像をアップロードします。
試しに、日本の形「Sushi」をアップロードしてみると、「Food (食べ物) / 92%」や「Sushi (寿司) / 92%」と見事に
寿司を的中させました。
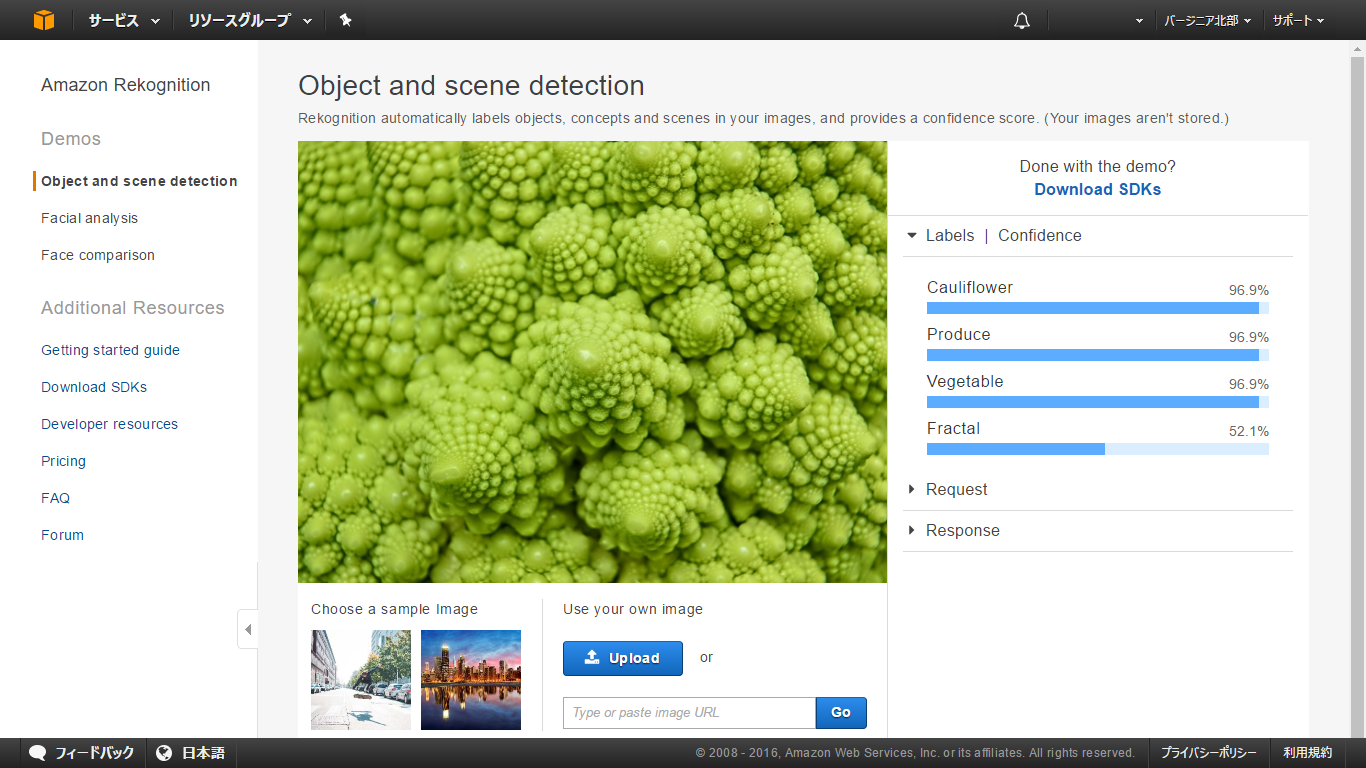
同じく、食べ物から「ロマネスコ」(カリフラワー)をアップロードしてみました。
これは全体像が見えているわけではないものの
「Cauliflower (カリフラワー) / 96.9 %」、「Vegetable (野菜) / 96.9 %」などロマネスコを示すような言葉が
表示されました。
また「ロマネスコ」の特徴でもある「Fractal (フラクタル図形)」も表示されており、画像の特徴をよく捉えられている
ことが分かります。
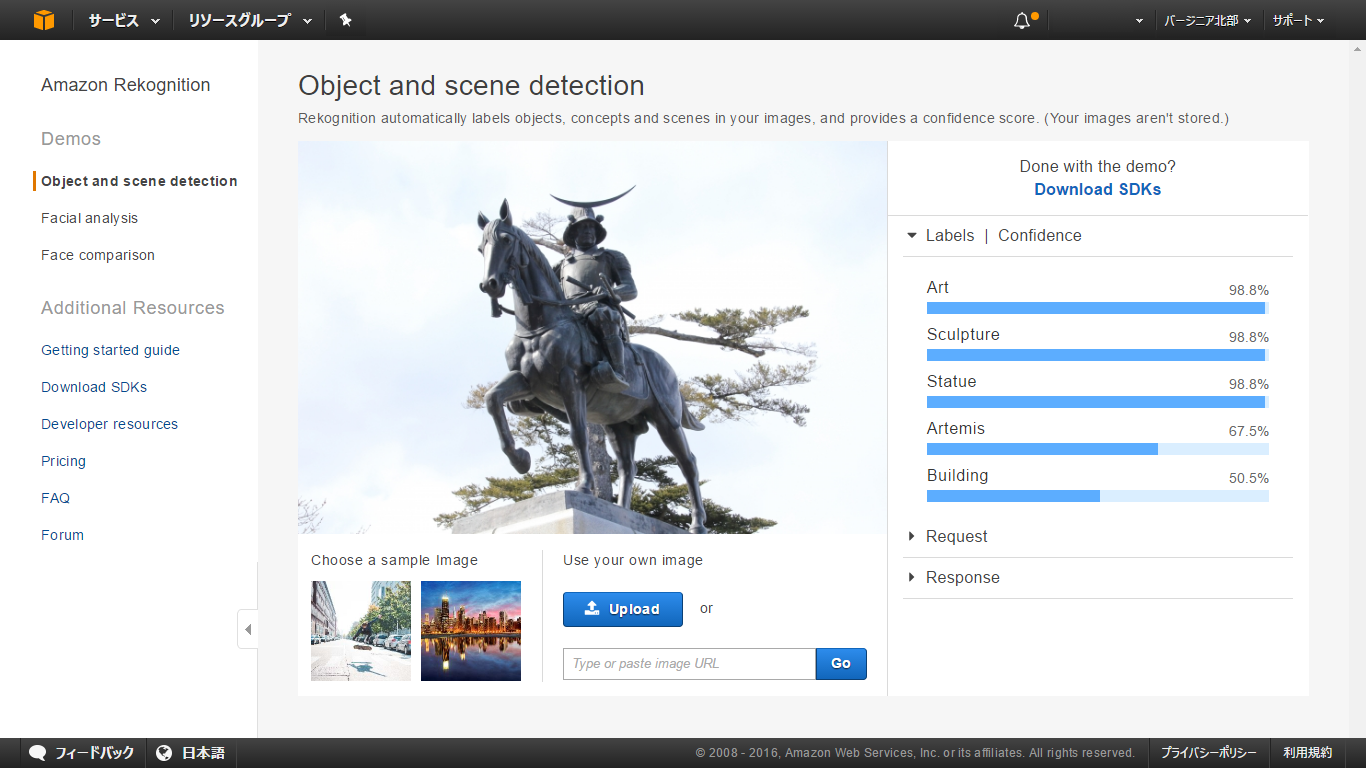
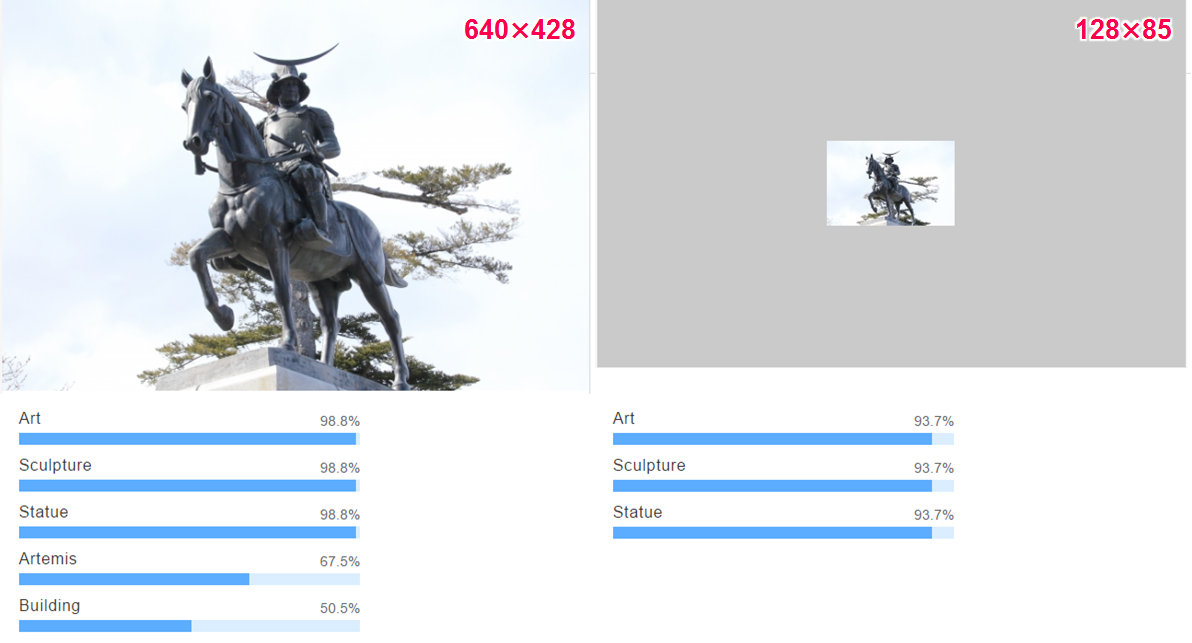
また、「伊達政宗像」をアップロードしてみても、固有名詞までは出ないものの
「Art (芸術) / 98.8 %)」、「Sculpture (彫刻) / 98.8%)」、「Statue (像) / 98.8%」
と画像内のオブジェクトをとらえられていました。
ただし、寿司にしろ、伊達政宗像にしろ、確度は下がるものの
「カリフラワー」や「アルテミス」(ギリシャ神話の女神)という判定も出ており、
実際に使う場合には、ある程度検証を重ね、閾値を決めた上でサービスに取り入れる必要がありそうです。
画像加工による認識精度
先ほど認識させた画像について、画像加工をした場合に認識精度がどう変わるか試してみました。
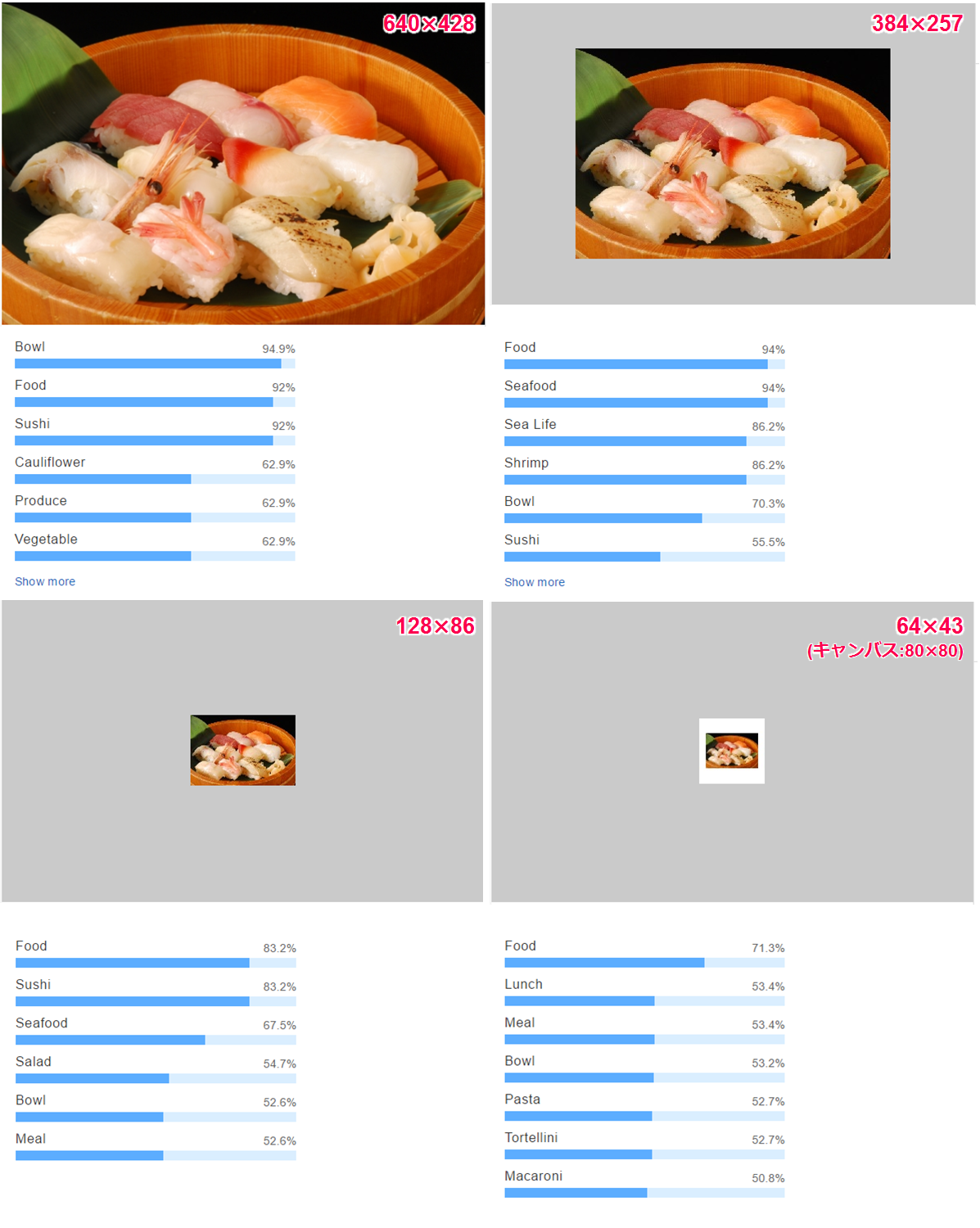
まずは、画像サイズを縮小した場合を試してみました。さすがに小さすぎると認識精度は落ちますが、APIの入力下限(80×80 pixel)ぎりぎりのサイズの寿司画像(128×86 pixel)でも「Sushi」と認識されました。
画像内のオブジェクトのサイズにもよりますが、サムネイル程度の小さな画像でも認識されることが分かりました。
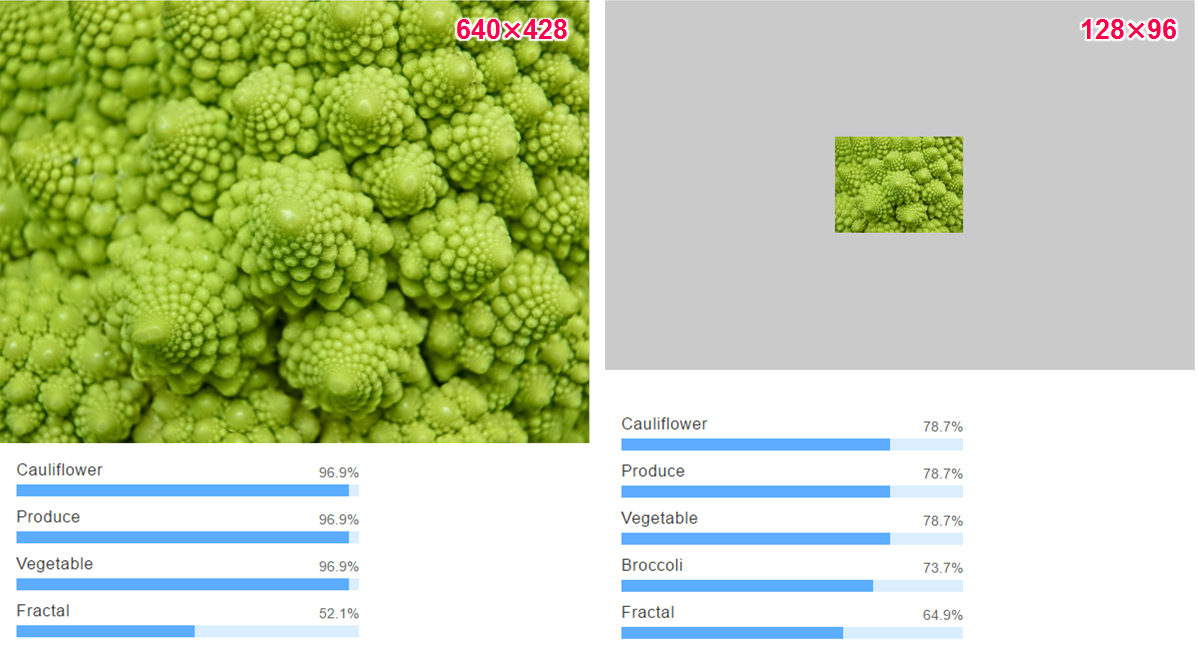
他の画像も同様に試しましたが、確度は下がるものの原寸サイズと同様の認識がされていました。
・ロマネスコ
・伊達政宗像
続いて、縮尺5分の1に縮小した画像を2種類の方法で拡大し、元のサイズに戻した画像を試してみました。
元画像に近づくように拡大した場合(バイキュービック法)では元画像と同じような認識がされていますが、
モザイク状に拡大した場合(二アレストネイバー法)では寿司を認識することができませんでした。

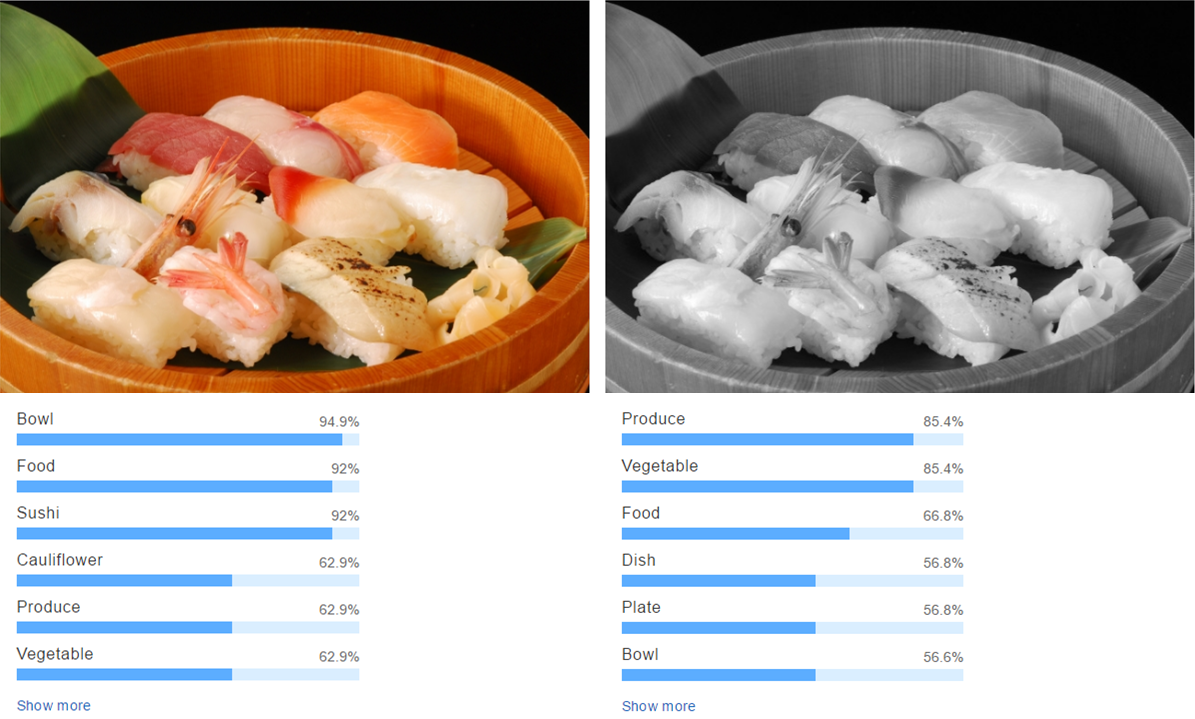
また、モノクロ画像にして試してみましたが、さすがに色情報がなくなると認識は難しくなるようです。
色相を変えた場合も試しましたが、同様に全体の色が変化すると認識できませんでした。
今回は、Amazon Recognitionのオブジェクト・シーン認識を試してみましたが、AWSが満を持して提供開始した
サービスだけあって認識精度はとても興味深いものがありました。
さすがに、大幅な色調補正やモザイク処理など相当な画像加工には対応しきれない部分もありましたが、普通の写真を認識する分には、納得できるだけの認識精度があるように思います。
また、サムネイル程度の画像でもそこそこ正確に認識ができていることから、端末型で画像圧縮し、データ転送を減らす
など応用も利かせられるのではないでしょうか。
次回は、Amazon Recognitionの顔認識を検証していきます。
次回もお楽しみに!
