はじめに
本記事は、AWSの公式ドキュメントAthena と AWS Glue を併用する際のベストプラクティスを参考に、Athena、Glue間のデータ連携について検証する記事になります。
わかりにくいワードを記事最後尾にまとめております。記事の目次から各ワードの解説へ飛べます。
読んでいる途中でわからないワードがあったら、目次から探してみてください。
本記事は数部にわたり、投稿してまいります。
投稿した記事を順次、以下に追記してまいります。
今回はまず、ベストプラクティスを学ぶ前にGlueとAthenaを触ってみる回になります。ベストプラクティスについては#2で学んでまいります。
Amazon Athenaとは
AWSの提供するインタラクティブなクエリサービスです。Amazon S3 内のデータを標準 SQL を使用して簡単に分析できます。
AWS Glueとは
AWSの提供するフルマネージド型のETLサービスで、分析用データの準備とロードを簡単にします。
AWS に保存されたデータを指定するだけで AWS Glue によるデータ検索が行われ、テーブル定義やスキーマなどの関連するメタデータが AWS Glue データカタログに保存されます。
カタログに保存されると、データはすぐに検索かつクエリ可能になり、ETL に使用できるようになります。
なぜAthena、Glueを併用するのか
Athena と AWS Glue データカタログを併用すると、AWS Glue で作成したデータベースとテーブル (スキーマ) を Athena でクエリしたり、Athena で作成したスキーマを AWS Glue や関連サービスで使用したりできます。
AWS Glue データカタログにメタデータを登録
SIGNATEに掲載されているお弁当需要予測のtrain.csvを利用して、AWS Glueデータカタログにメタデータを登録します。
まず、任意のS3バケットにcsvファイルをアップロードします。
私は以下のパスにアップロードしました。
|
1 |
s3://バケット名/test/train.csv |
次にクローラを追加します。
AWSコンソール上でAWS Glueを開き、左の項目からクローラをクリックします。
クローラの追加をクリックします。
クローラに名前を付けます。
任意の名前を入力して、次へをクリックします。
私は、test-obento と入力しました。

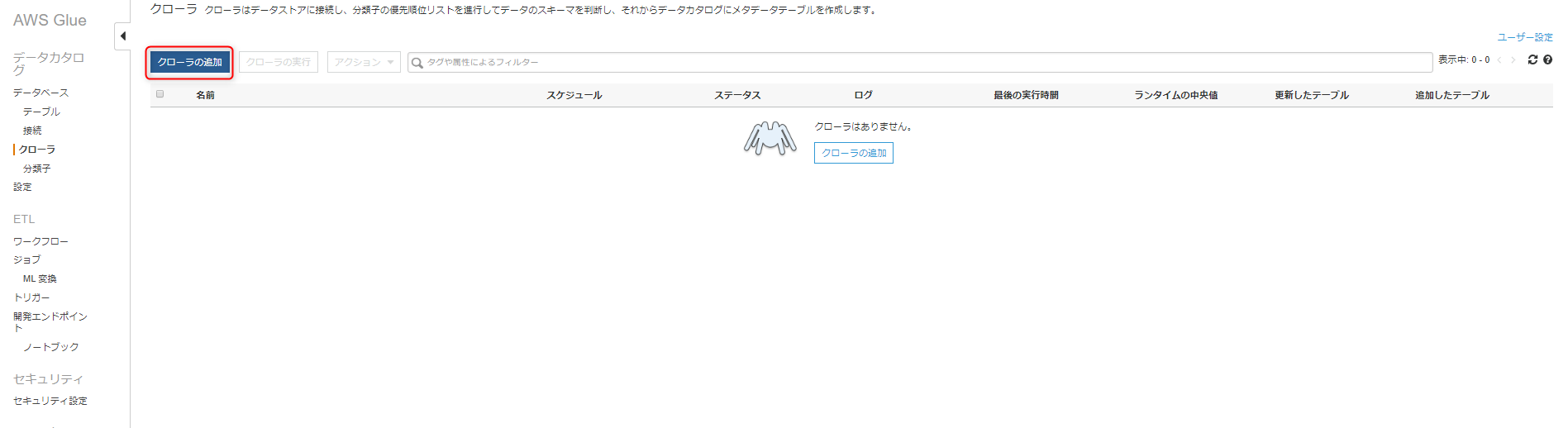
クローラのデータソースを指定します。
今回はデータストア(S3)を利用するので、Data storesを選択して、次へをクリックします。
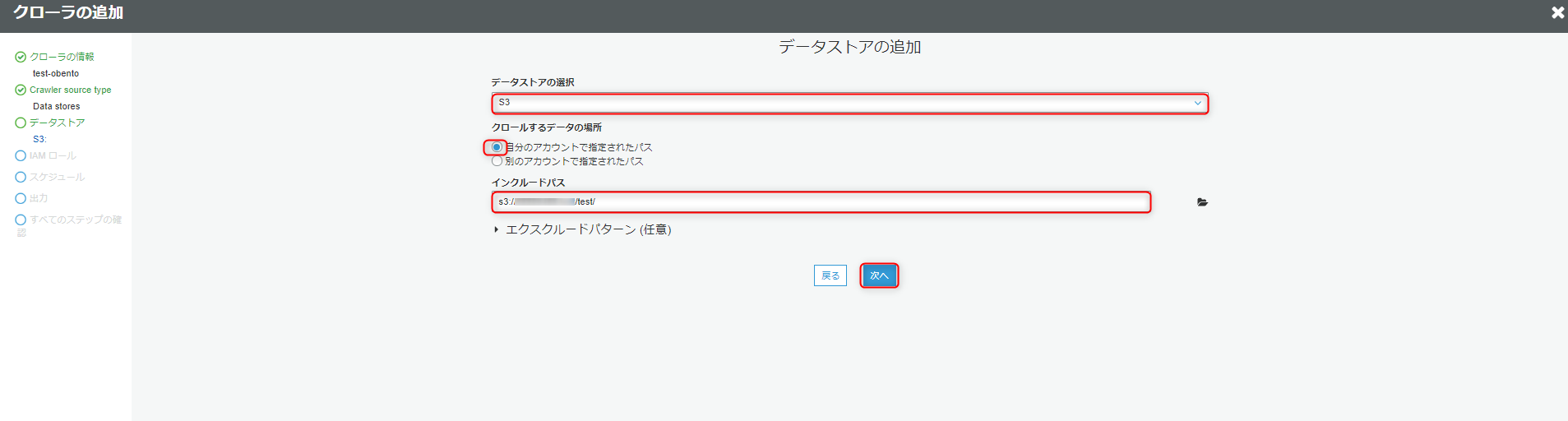
データソースの詳細設定をします。
データストアはS3で自分のアカウントで指定されたパスを選択します。
インクルードパスには、アップロードしたcsvファイルのあるフォルダを選択します。
私の場合はs3://バケット名/test/となります。
他に追加したいデータストアがある場合は追加できます。
今回はいいえを選択し、次へをクリックします。
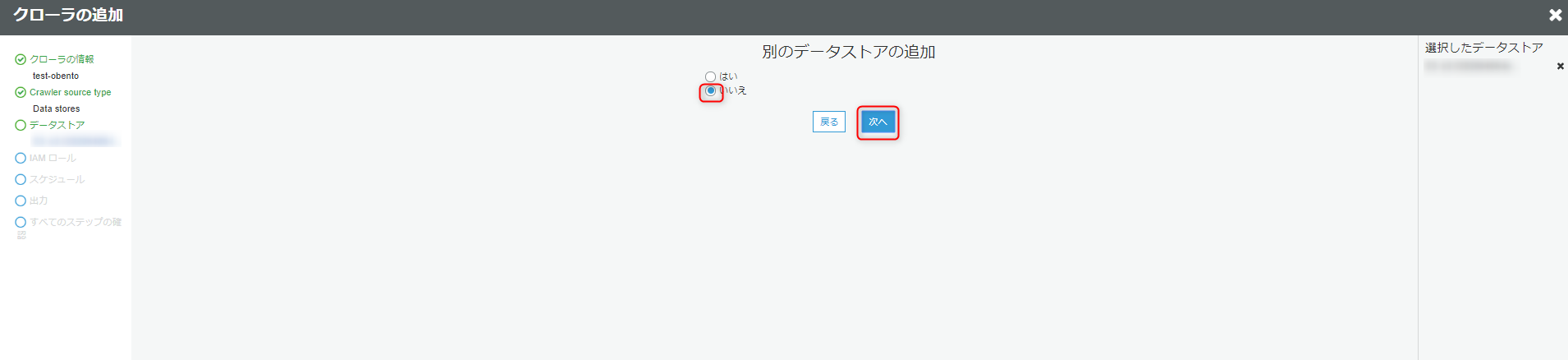
IAMロールの選択、作成を行います。
今回、私はIAMロールを作成しました。
IAMロールに任意の名前を入力して次へをクリックします。
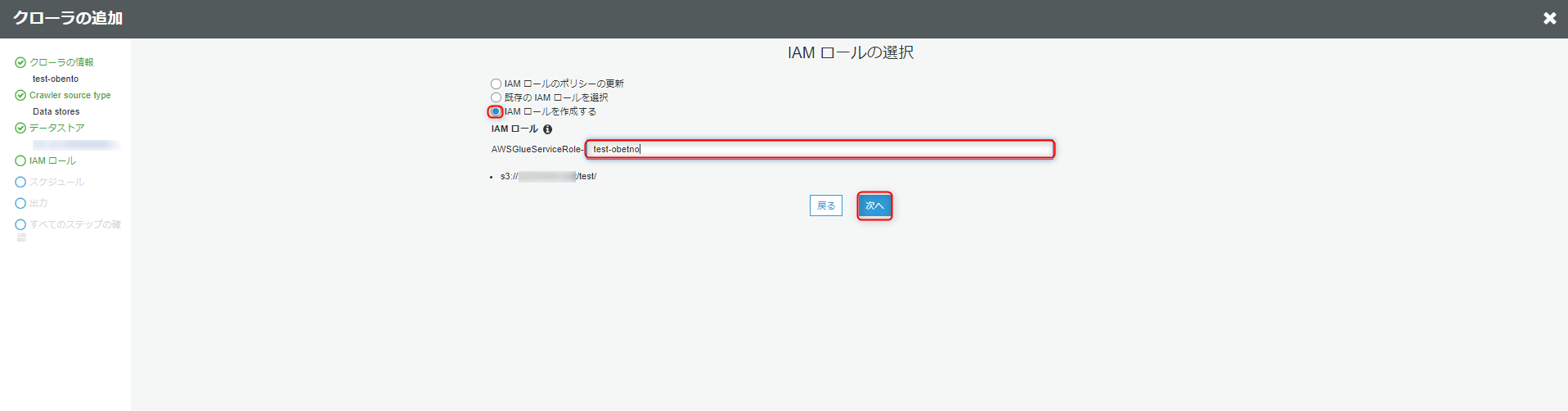
次にクローラのスケジュールを設定します。
実際に業務で使う場合は、メタデータの更新、追加があるので定期的にクローラを実行しメタデータの更新を反映します。
今回は一度読み込むだけなので、オンデマンドで実行を選択し、次へをクリックします。
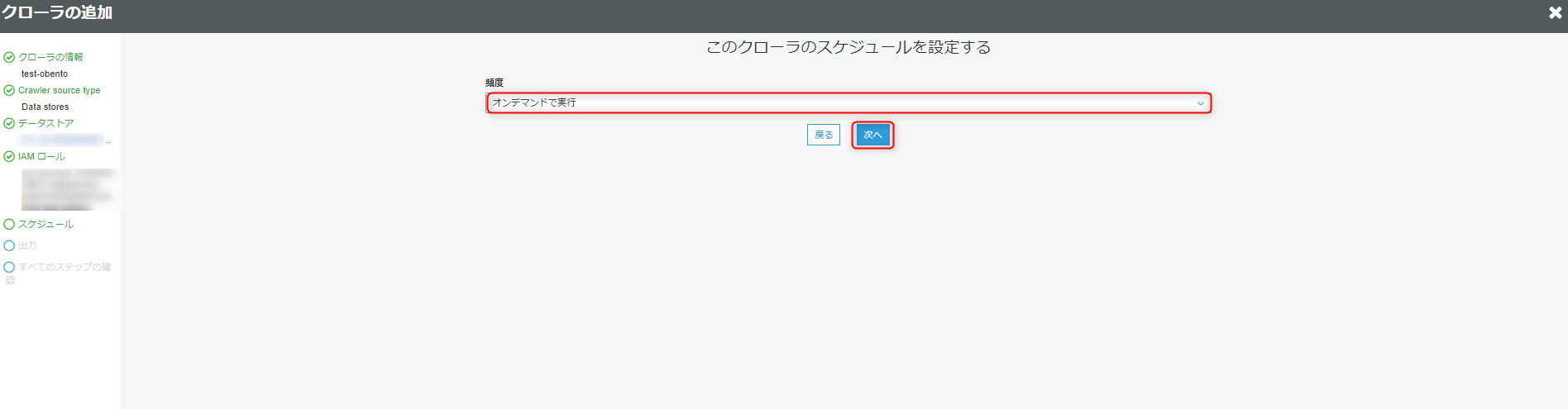
次にクローラの出力設定をします。
データベースは作成していないので、データベースの追加から新たにデータベースを作成します。
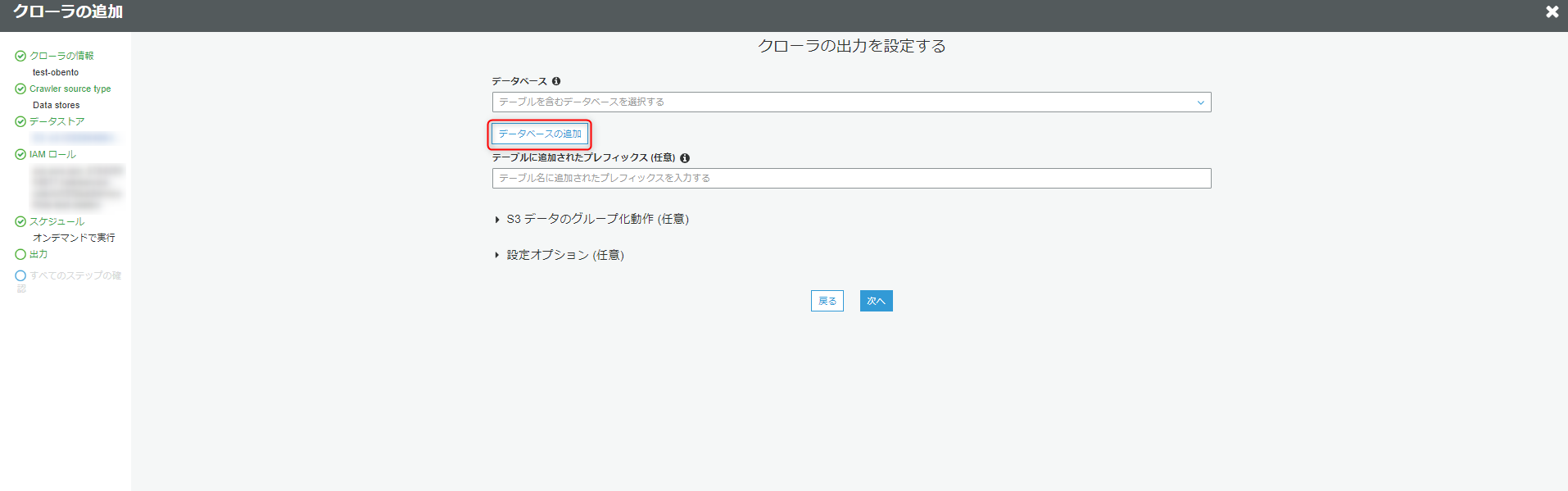
任意のデータベース名を入力してください。
私は、testとしました。
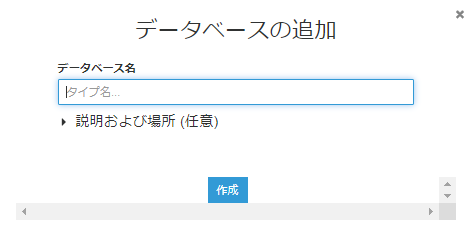
作成したデータベースが選択されていることを確認し、次へをクリックします。
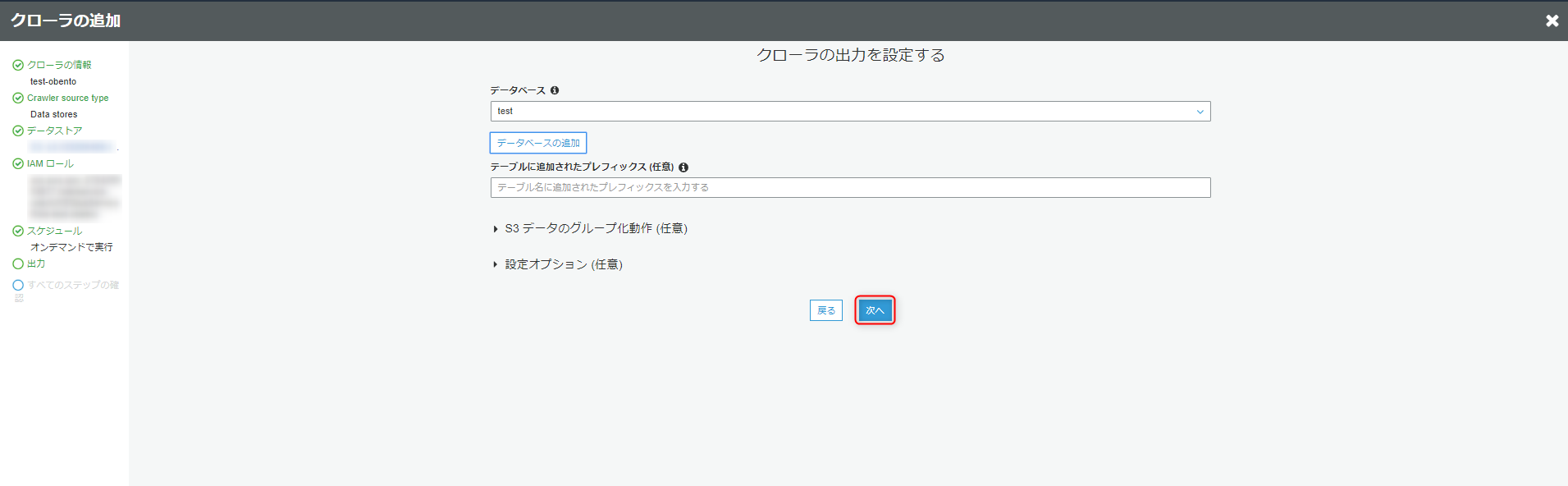
内容を確認し、完了をクリックします。
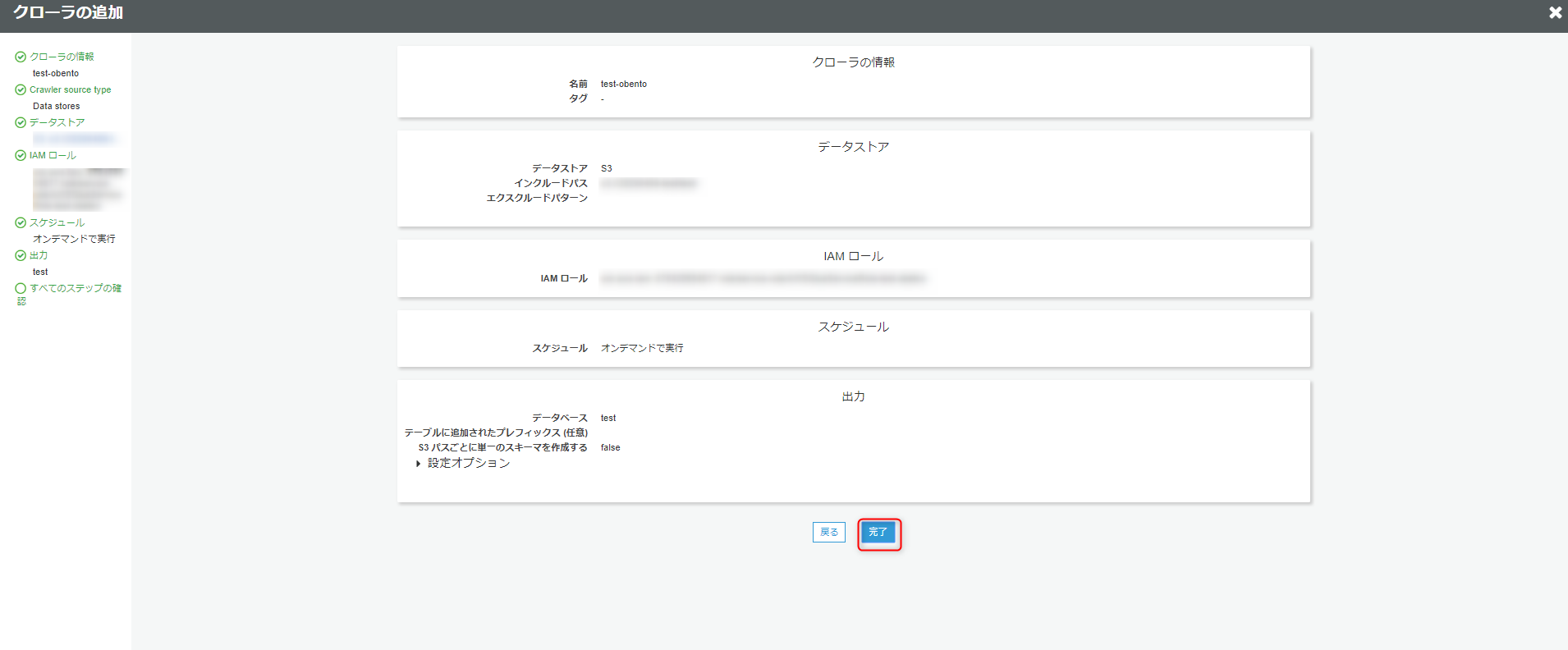
クローラが作成されると画面上部に今すぐ実行しますかと出てくるので、クリックします。
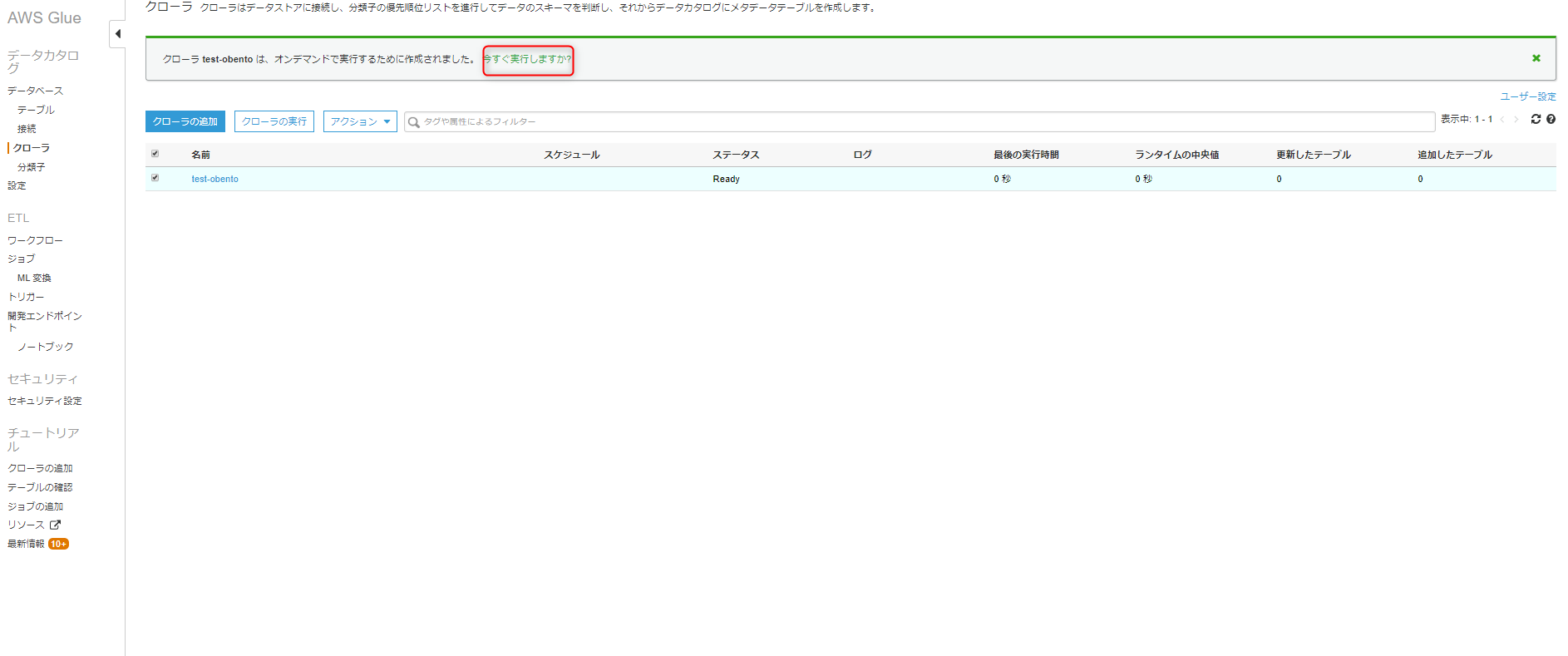
クローラが実行され、完了すると以下のようにステータスがStoppingとなります。
左の項目から、テーブルを選択し、作成されたテーブルをクリックします。
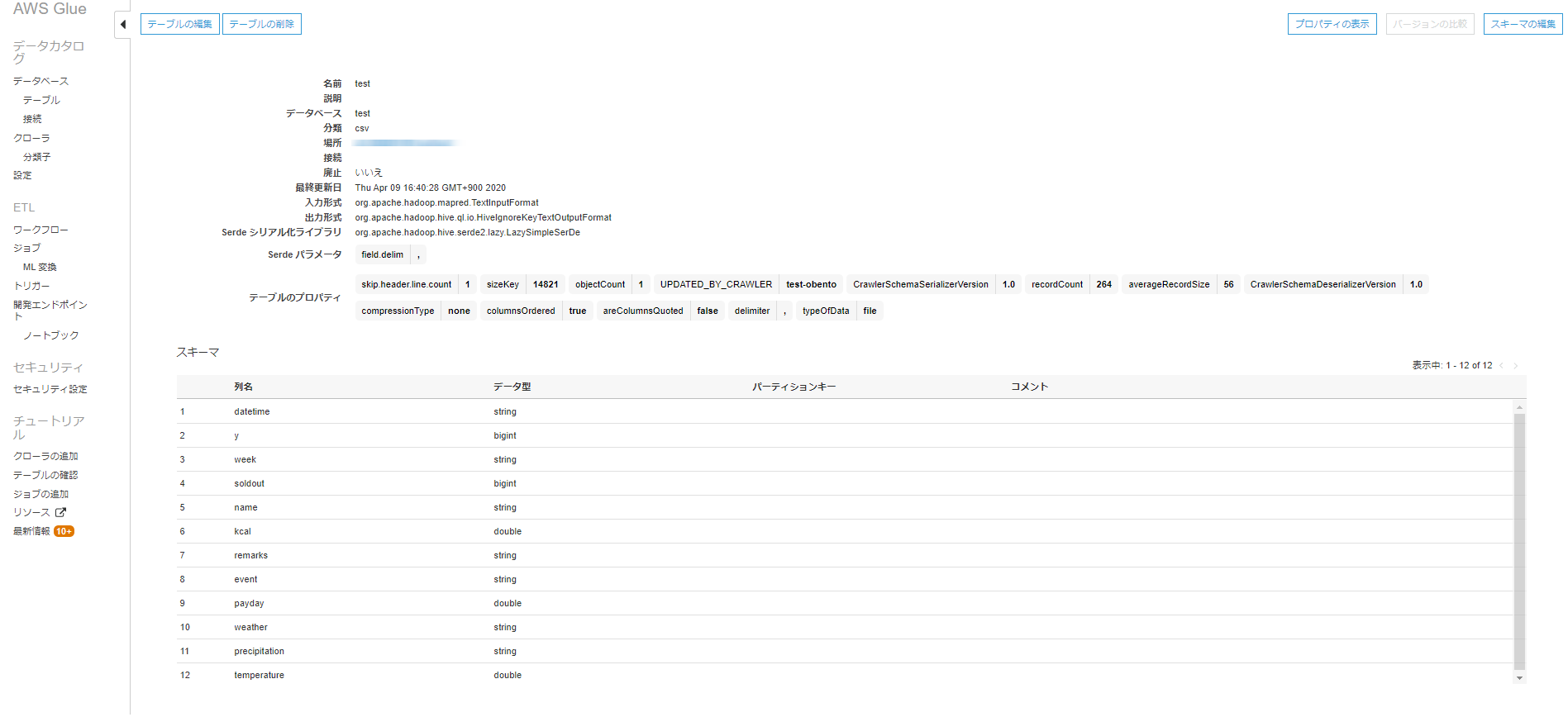
すると以下のようにAWS Glueデータカタログに登録されたテーブルのメタデータが確認できます。
AWS Glueデータカタログに登録されたデータを元に Amazon Athena でクエリを実行
早速、データカタログに登録されたデータを利用して、Athenaでクエリを実行します。
まず、AWSコンソール上でAmazon Athenaを開きます。
最初に、クエリの実行結果の保存先を指定する必要があります。
画面右上の設定をクリックします。

出力先となるS3パスを入力します。

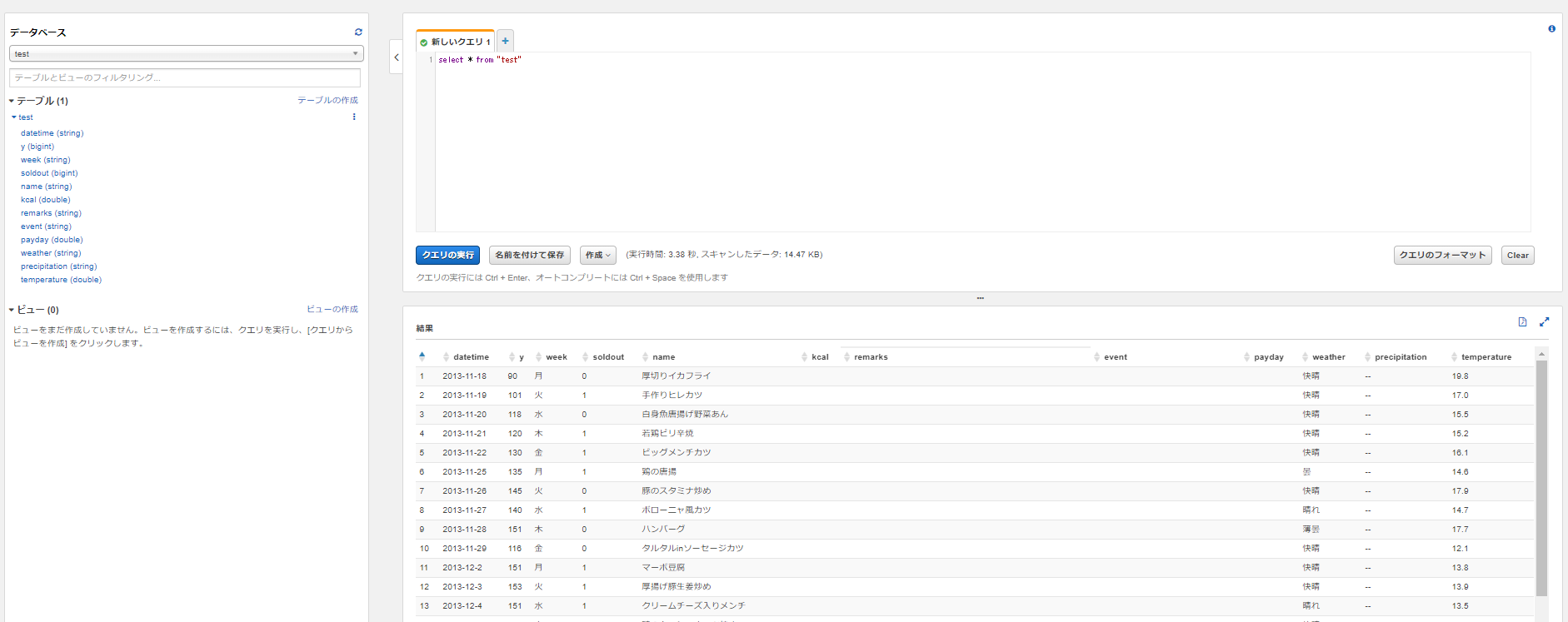
では試しに、登録したデータをクエリで抽出してみます。
以下のコードを実行します。
これでテーブルを全て抽出します。
|
1 |
select * from "テーブル名" |
すると以下のように実行結果が返ってきます。
先ほど設定した出力先にも、クエリ結果が保存されているので確認してみてください。
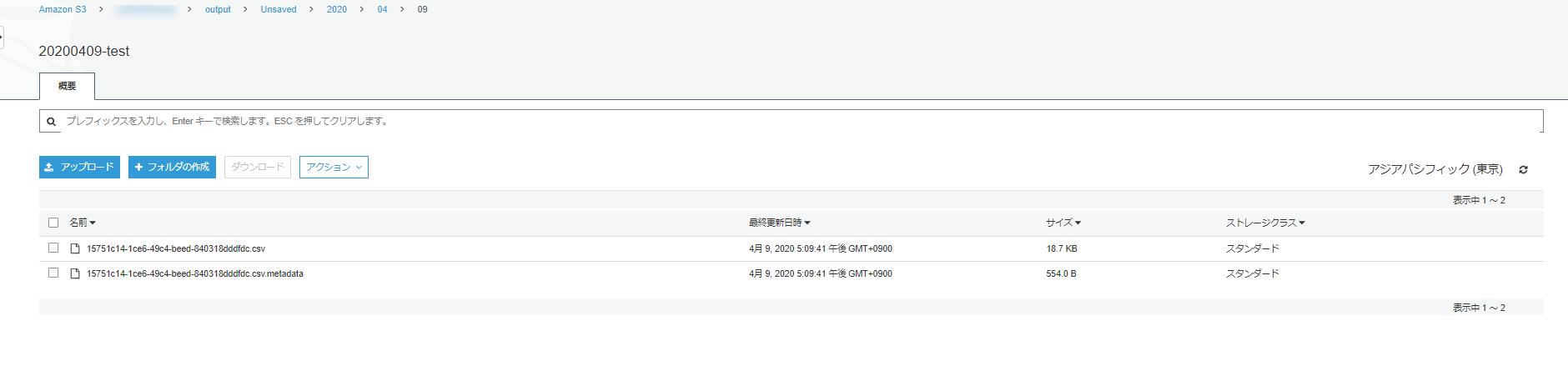
正しく出力されていました。
終わりに
今回はベストプラクティスを学ぶ前段として、Athena、Glueを利用してみました。
次回からは、ベストプラクティスに沿ってAthena+Glueを学んでいきます。
どうぞよろしくお願いいたします。
用語解説
インタラクティブ
- 双方向、対話型という意味
例えば、スマホで何かを検索するとします。
検索バーにワードを打ち込んで検索をかけると検索結果が返ってきます。
これは、送信側である私たちのこれが調べたいというリクエストに対して、それを受信したブラウザが検索結果はこれですよと応答してくれています。 これが対話型、インタラクティブな通信といえます。
クエリ
- データベースのデータを操作、抽出する際に送る処理要求(命令)
SQL
- リレーショナルデータベースのデータを操作したり、定義するためのプログラミング言語
SQLで書いた、SQL文がクエリにあたります。
リレーショナルデータベース(RDB)
- 事前に定義された表形式のデータベース
1個以上の列と0個以上の行によって構成される表形式のデータベースで、RDB上で行う様々な操作の結果も表形式で表現されます。
RDBでは、個々の表は必要最小限の情報のみを保持するように設計し、SQLによって各表の選択結合等を行いデータを取り出します。
例えば、以下のように商品と売り上げのテーブルをRDB上に定義するとします。
商品マスターテーブル
| 商品番号 | 商品名 | 単価 |
|---|---|---|
| 0001 | 商品A | ¥ 100 |
| 0002 | 商品B | ¥ 200 |
売り上げテーブル
| 注文日 | 商品番号 | 個数 |
|---|---|---|
| 1/1 | 0001 | 2 |
| 1/2 | 0002 | 3 |
ここで、売り上げと商品情報を同時に得たいという場合には、SQLで結合、計算等を行うことで、以下のような出力が得られます。
| 商品番号 | 商品名 | 注文日 | 単価 | 個数 | 小計 |
|---|---|---|---|---|---|
| 0001 | 商品A | 1/1 | ¥ 100 | 2 | ¥ 200 |
| 0002 | 商品B | 1/2 | ¥ 200 | 3 | ¥ 600 |
フルマネージド型サービス
- 事業者によって内容は異なりますが、その多くは対象のサービスの24時間365日監視や障害発生時の復旧作業を事業者が提供することを指す
ETL(Extract/Transform/Load)
- データベースなどから、データを抽出(Extract)、必要に応じて変換(Transform)、変換済みのデータを格納先にロード(Load)することを指す
テーブル定義
- テーブルの詳細情報のことで、どのようなカラムが存在して、各カラムの属性は何かを定義している情報
スキーマ
- データベースの構造
データベースによってスキーマの定義が違い、スキーマのないデータベースもあります。
メタデータ
- データに関するデータ
こちらも場合によって、定義が違います。
よくある例としては、作成者、ユーザー名、編集者、作成日、更新日、保存場所、サイズのようなデータが該当します。
AWS Glue データカタログ
- データの場所、スキーマ、およびランタイムメトリクスへのインデックス ETL ジョブを作成するために、Glueが参照するカタログでメタデータとして保存されています。
クローラ
- 指定したデータ群のメタデータを調査してAWS Glueデータカタログに追加するもの
