はじめに
前回の記事でご紹介した、ドキュメント翻訳の自動化の実践の続きです。
コンテンツを外国の言語に翻訳するには、バッチ翻訳ジョブを実行することで、容易かつコスト効率よく解決することができます。
しかし、一連のドキュメントを集めたり、そのドキュメントに対して定期的に非同期のバッチ API を呼び出したりすると時間がかかります。
ドキュメントが用意された時点で、すぐに翻訳処理を開始できたほうがいいですよね。
AWS Lambda と リアルタイム翻訳を使用する進んだアプローチ
イベント駆動型アーキテクチャを利用することで、簡単に、自然な翻訳を行えるようになります。
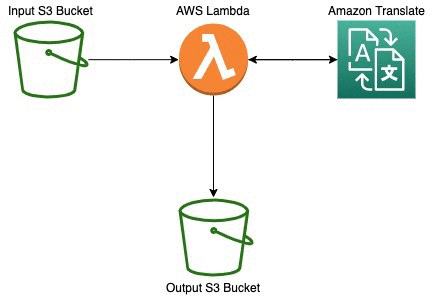
特定の S3 バケットにドキュメントがアップロードされたときに、そのバケットから AWS Lambda に通知が送信されるように設定を構成します。
実践の流れ
S3 バケットの通知により、AWS Lambda では、次のようなイベントのシーケンスのためのコードが実行されます。
1. ドキュメントを読み出し S3 バケットにアップロードします。
2. リアルタイム翻訳 API に渡せるように、要素をドキュメントから抽出します。
3. リアルタイム翻訳 API にこの要素を渡します。
さらに、リアルタイム翻訳 API からの出力を使って翻訳済みドキュメントを再構成します。
4. 指定したバケットに翻訳したドキュメントを保存します。
ステップ1. CloudFormation を使ったアプリケーションの起動
コンソールを使い、 AWS CloudFormation スタックを起動します。
AWS CloudFormation コンソールで、新しくリソース (標準) を設定し、[Create stack]をクリックします。
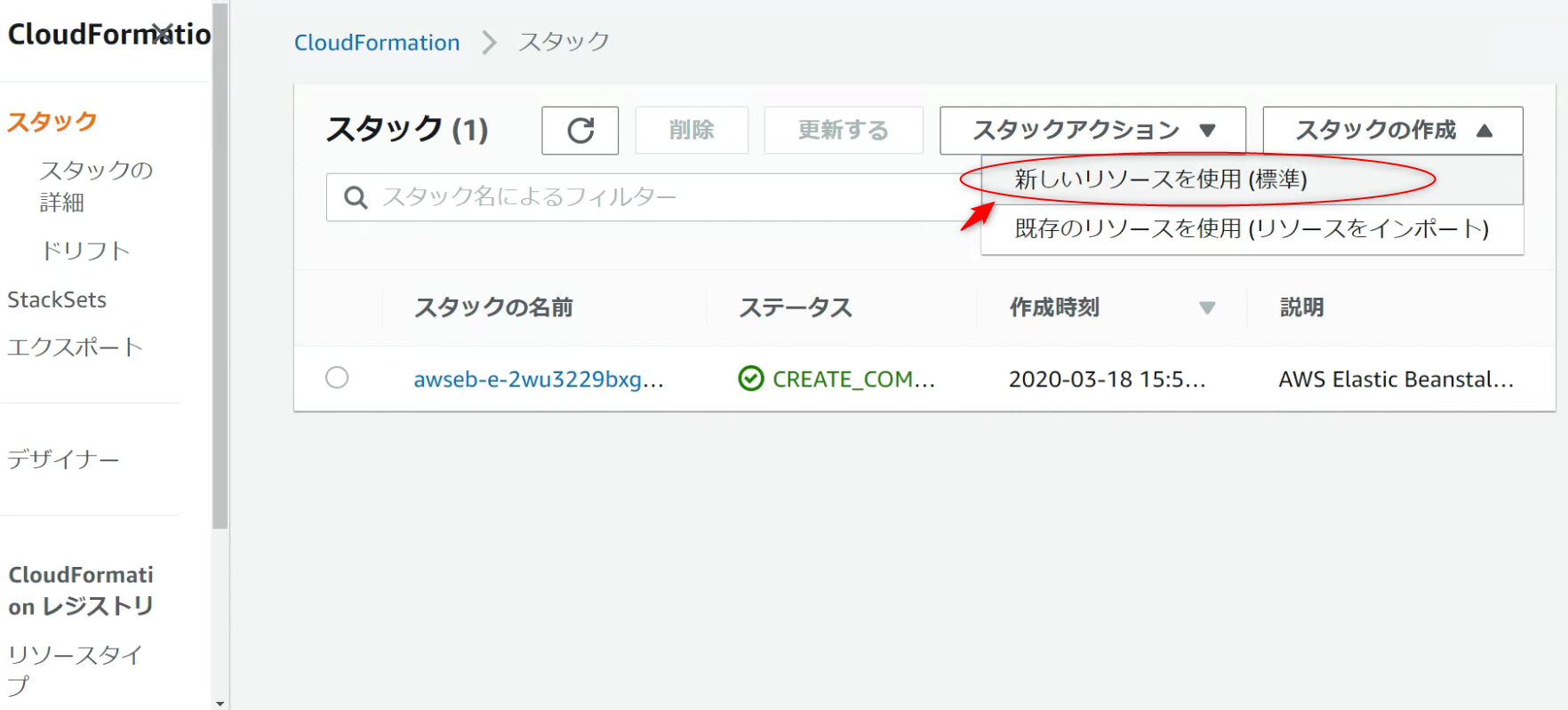
[Amazon S3 URL] を選択し、Amazon S3 URL の項目に
https://s3.amazonaws.com/aws-ml-blog/artifacts/serverless-document-translation/translate-lambda-cfn-stack.yml
をコピーします。次に [Next] をクリックします。
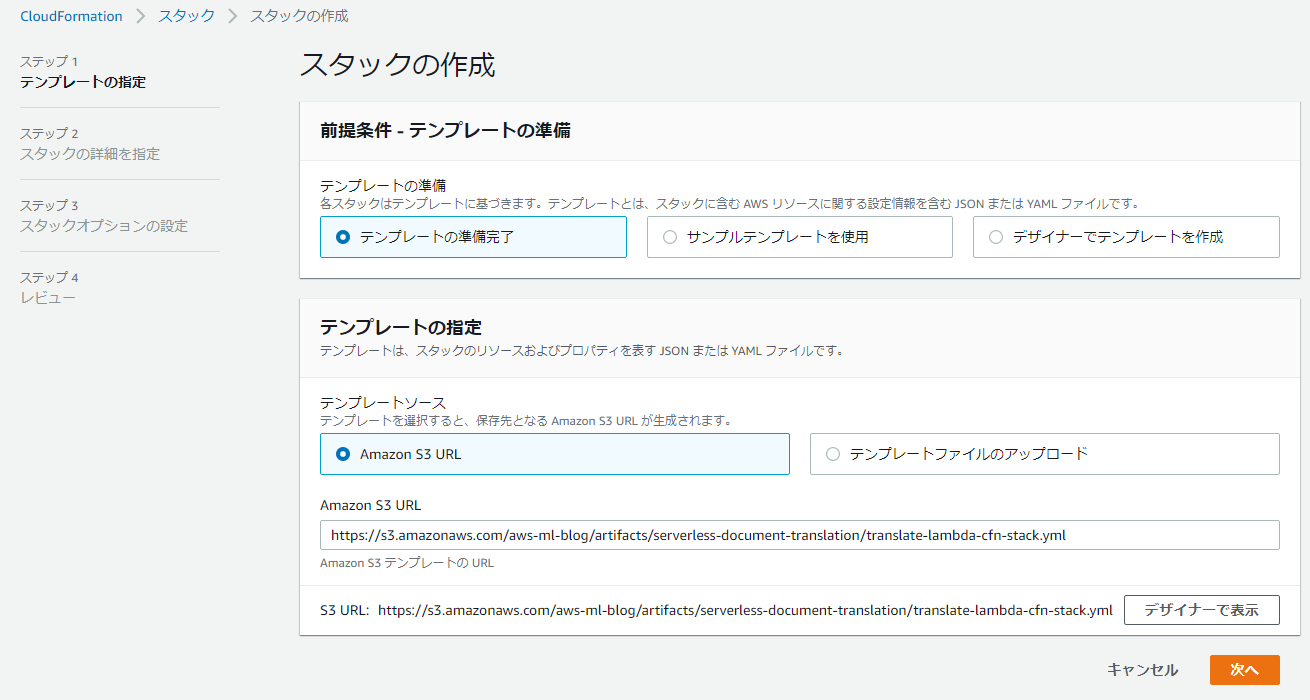
ステップ2. S3 バケットを作成して指定する
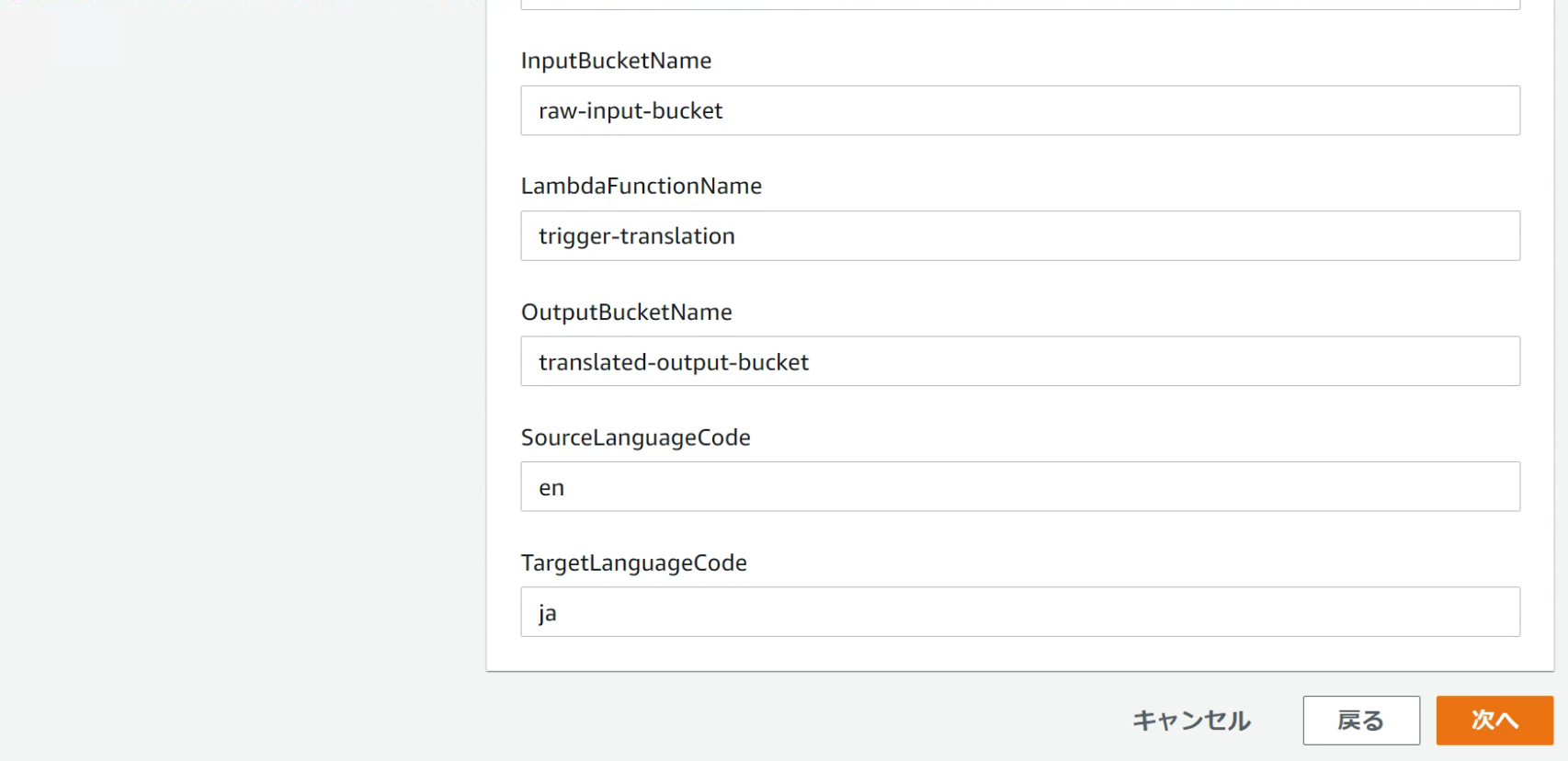
[Stack name] には、automated-document-translation のように、アカウント内で一意のスタック名を入力します。
[IAMRoleName] には、TranslationLambdaExecRole のように、アカウント内で一意の IAM ロール名を入力します。
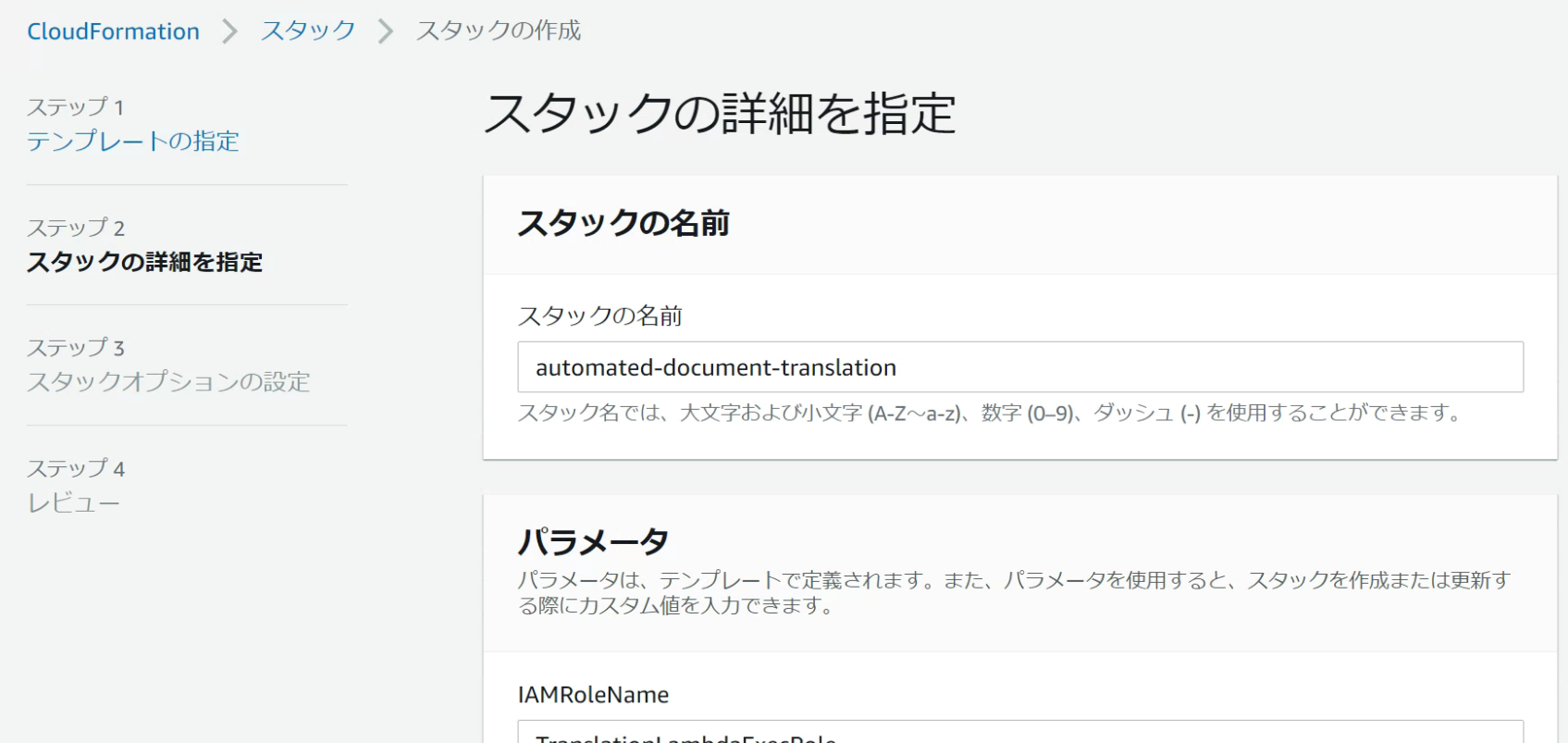
[LambdaFunctionName] には、trigger-translation のように、一意の AWS Lambda 関数名を入力します。
[InputBucketName] には、スタックが作成した Amazon S3 バケットのための、一意の名前を入力します。
入力のドキュメントは、翻訳処理前に、このバケットにアップロードされます。
新規の S3 バケットが作成されるため、既存バケットの名前は使わないようにします。
※ 名前が同じものがあると、スタックの構築が失敗します。
[OutputBucketName] には、出力バケットのための一意の名前を入力します。
翻訳済みの出力ドキュメントが、このバケットに保存されます。
入力バケットの場合と同様に一意の名前をつけてください。
[SourceLanguageCode] では、翻訳前のドキュメントの言語を、コードで入力します。
たとえば、英語を指定する場合は en とし、主として使われている言語を検出させる場合は auto とします。
[TargetLanguageCode] には、翻訳後のドキュメントで使う言語を、コードで入力します。
日本語を指定する場合には ja とします。
(使用可能な言語コードの詳細についてはこちら)
[Next] を選択します。
[Configure Stack Options] ページで、スタック用のタグなど、追加のオプションパラメータを選択します。
(特に必要なければいじらなくてOK)
[Next] を選択します。
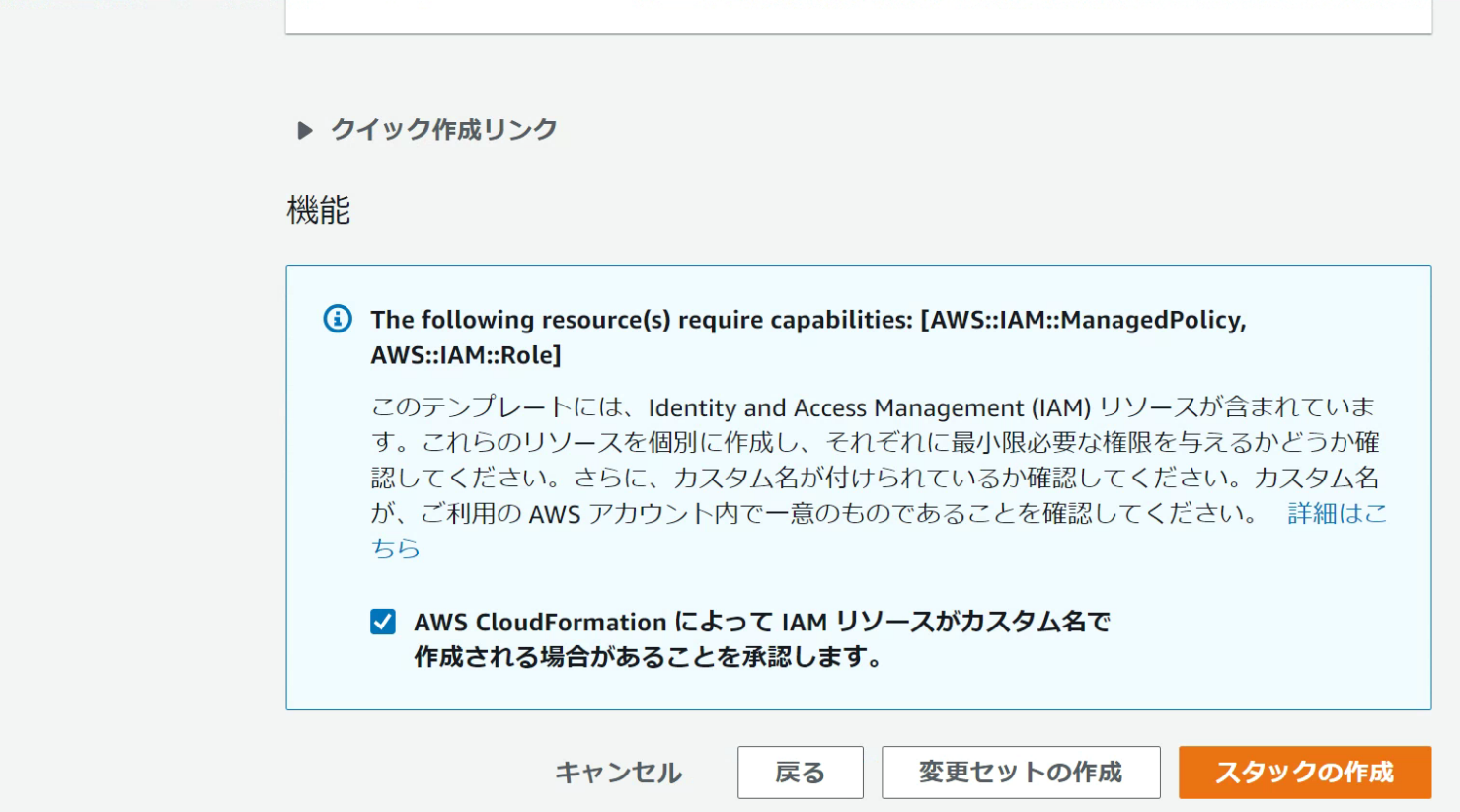
[I acknowledge that AWS CloudFormation might create IAM resources with custom names.] のチェックボックスをオンにします。
[Create Stack] をクリックします。
スタックの作成が完了するまで、最大 1 分間ほどかかります。
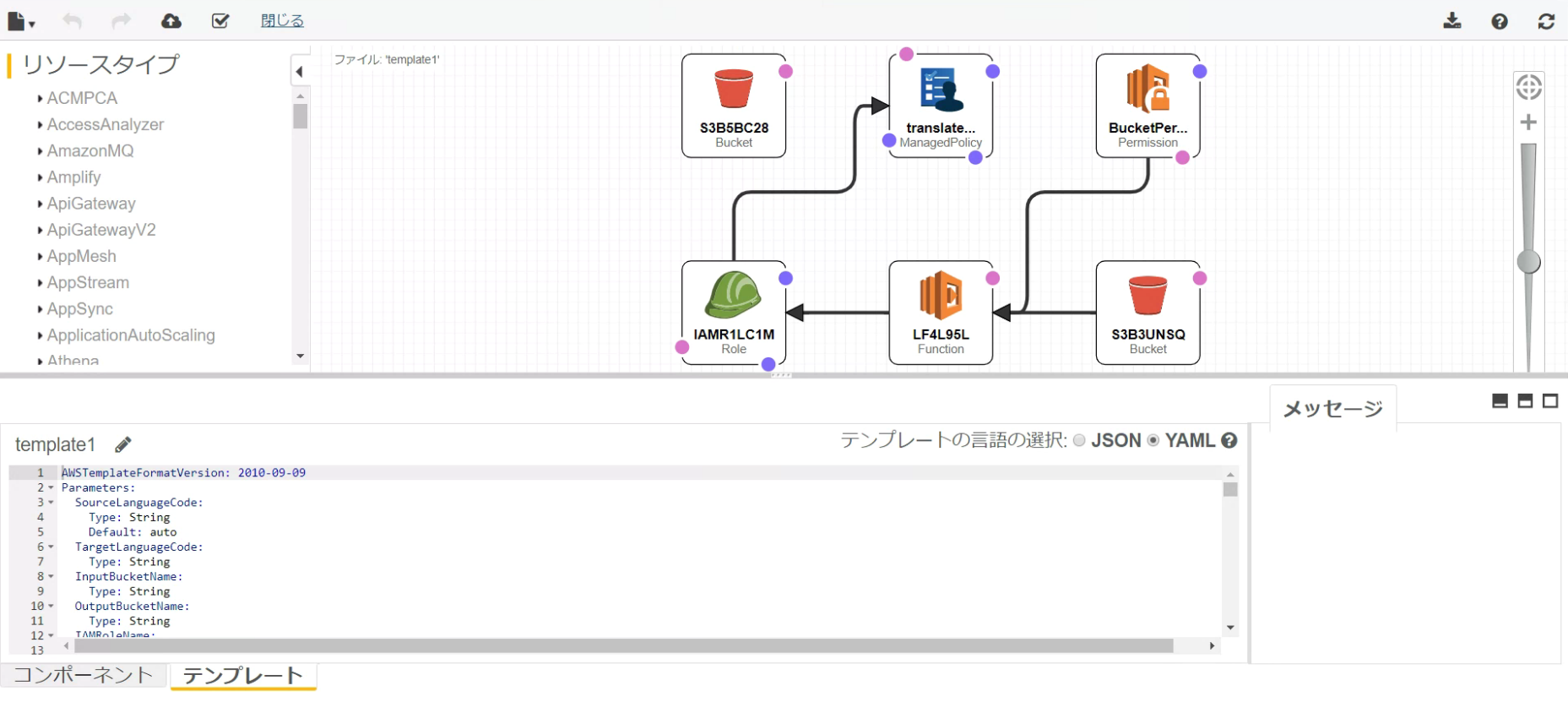
ロール(権限)の内訳
Lambda 関数では、このロールが必要な Amazon S3 と Amazon Translate API にアクセスできることを想定しています。
この IAM ロールには、 2 つのポリシーがアタッチされています。
1 、入力および出力の S3 バケットに対する、読み出し/書き込みのアクセス権限
(GetObject と PutObject) を与えるカスタムポリシー。
2 、AWS が管理しているポリシー TranslateReadOnly
Amazon Translate への API を呼び出すためのもの。
ステップ3. アプリケーションの実行
AWS CloudFormation スタックの作成が終わると、このソリューションを利用開始できます。
デザインを表示させるとこんな構成が出来上がります。視覚的にわかりやすいですね。
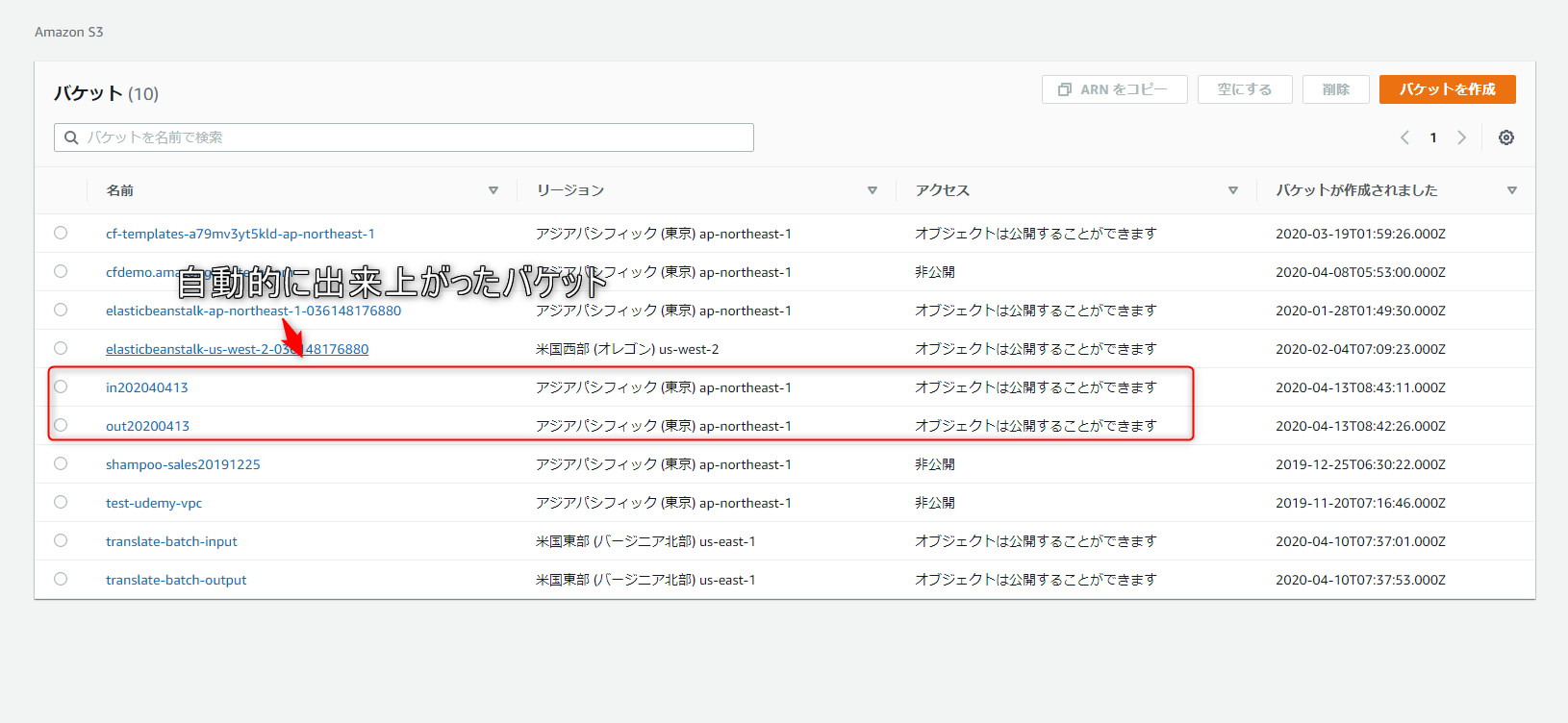
入力側の S3 バケットに、翻訳対象のテキストファイルをアップロードします。
これによりワークフローが起動され、処理が完了すると、翻訳済みドキュメントが出力側の S3 バケットに自動的に保存されます。
翻訳済みドキュメントは、出力 S3 バケット内の次のようなパスに保存されます。
<TargetLanguageCode>/<original path of the source file>.
たとえば、入力ドキュメントのタイトルが test.txt となっていて、入力 S3 バケット内の in202040413 という名前の S3 フォルダーに保存されているとします。
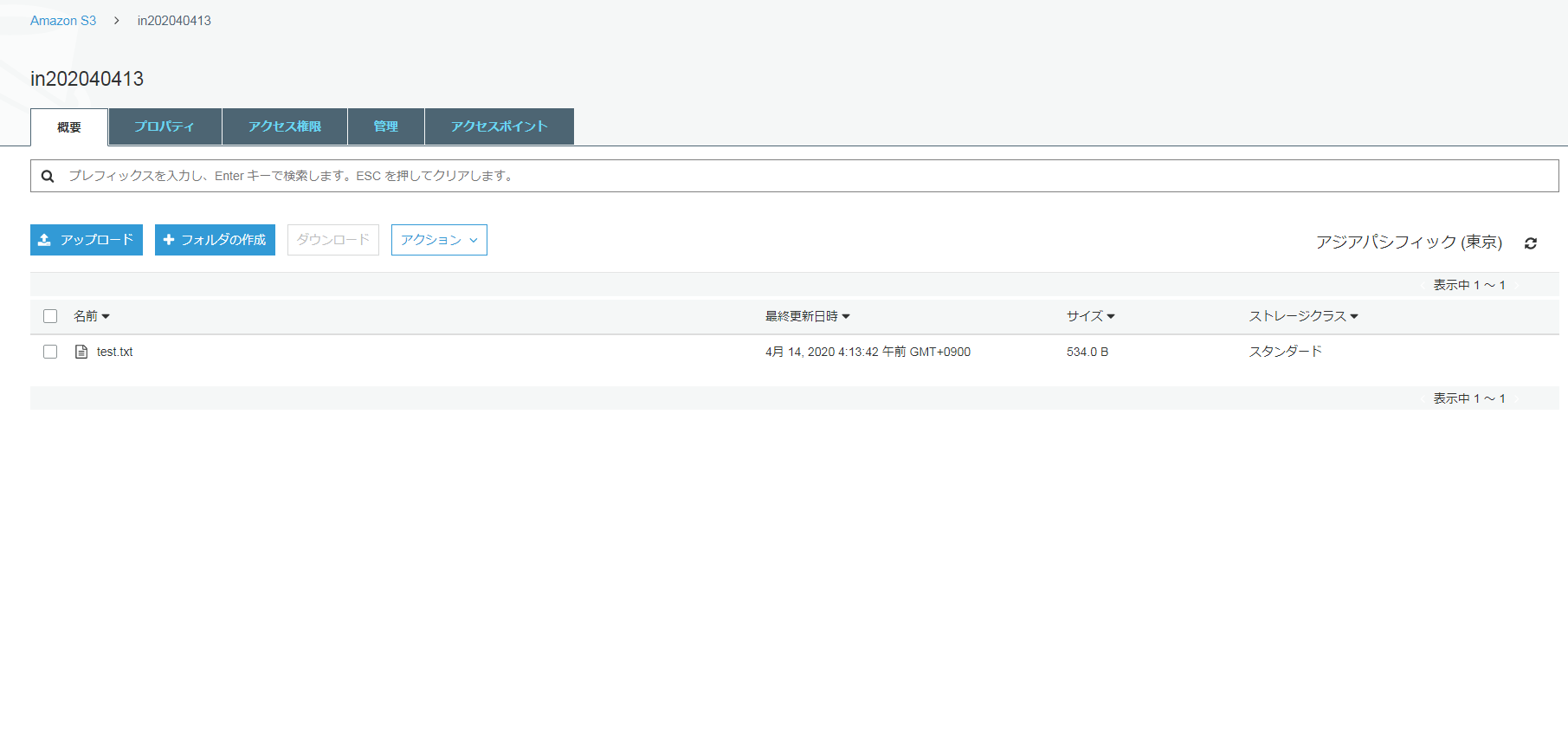
日本語に翻訳されたドキュメントの保存先は、出力バケット内の 「ja/out20200413/test.txt」 となります。
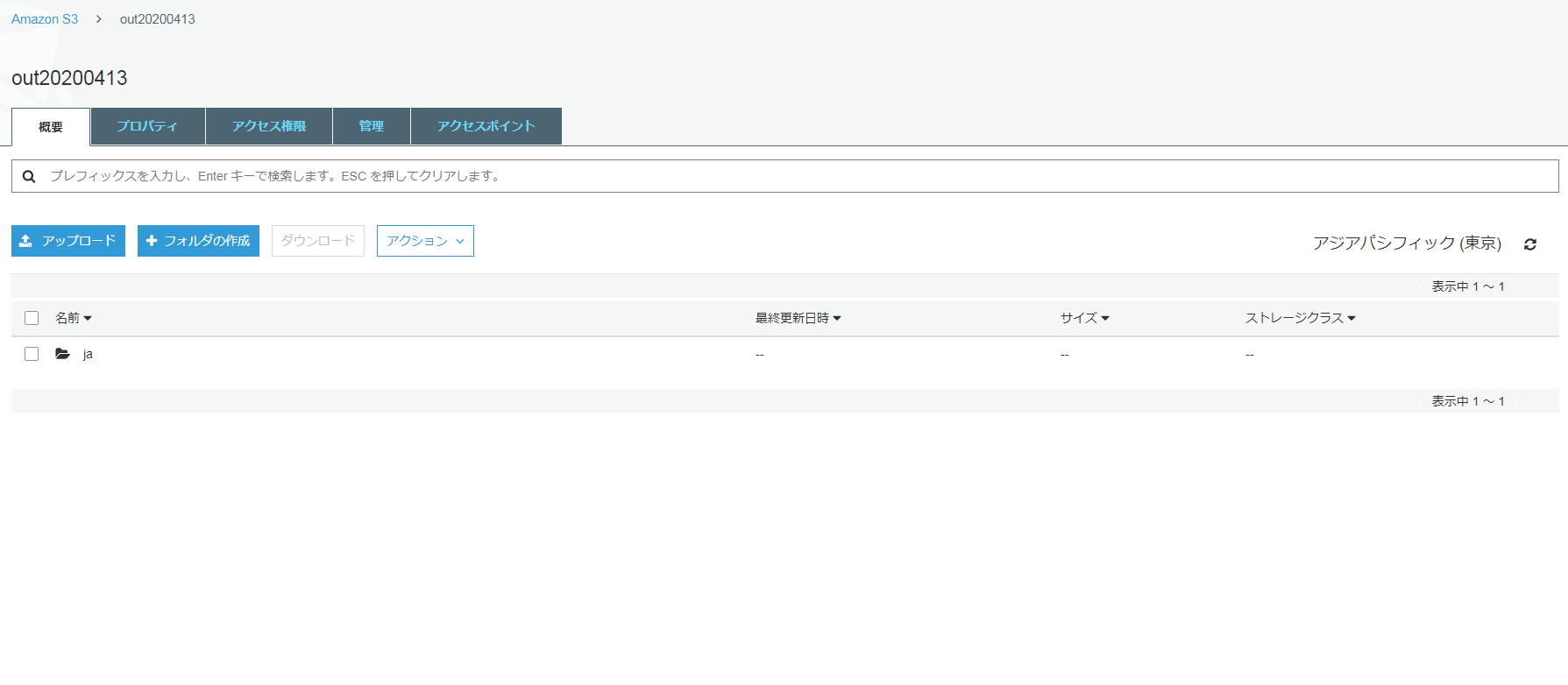
出力 S3 バケットでドキュメントが見つからない場合は、Amazon CloudWatch Logs で対応する Lambda 関数をチェックし、失敗の原因となっている可能性のあるエラーを探します。
ここでは、UTF-8 形式のテキストドキュメントのみを処理しています。
Lambda 関数での最大実行時間 (timeout) に関する制限があります。
結果
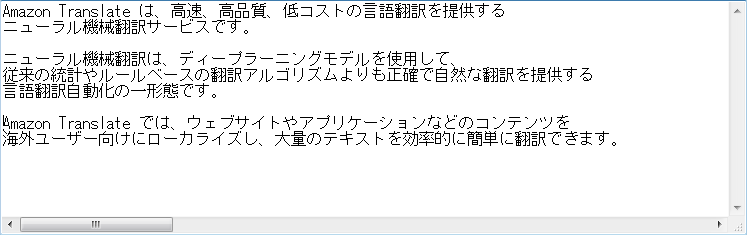
今回は一つのファイルに英語の文章をまとめてから、アップロードしました。
今回も違和感のないキレイな日本語になりました!
所感
1. 収集したドキュメントに、非同期のバッチ翻訳を行うシンプルな翻訳
2. AWS Lambda と Amazon のリアルタイム翻訳を使い、ドキュメントを入手する度に同期的に翻訳を行う、
より進んだ手法
今回この2つの手法を使ったドキュメント翻訳を行いましたが、1だとバケットを一度作ってしまえば Translate で操作して簡単に行なえますし
2を使えば S3 バケットを前もって作らなくても、自動的な翻訳が一度に一つのコンソール画面で処理できるので、面倒が少なくて済みます。
作業効率もあがりますし、文の長さを気にせず、質の高い翻訳が実現できるので積極的に使っていきたいです!
