はじめに
このチュートリアルでは、Amazon SageMaker を使用して機械学習(ML)モデルを構築、トレーニング、デプロイする方法を学びます。
Amazon SageMaker は、モジュール式のフルマネージド機械学習サービスであり、開発者やデータサイエンティストがMLモデルを大規模に構築、トレーニング、デプロイできるようにします。
Jupyter-notebook を触ることにもなりますので、はじめて使う方は一連の流れを知ることが出来ます。
Amazon SageMaker の利用
機会学習モデルをトレーニングするには
- 大量のデータを管理
- トレーニングに最適なアルゴリズムを選択
- トレーニング中に計算能力を管理
- モデルを本番環境にデプロイする必要があります。
Amazon SageMaker は、MLモデルの構築とデプロイをはるかに簡単にすることで、この複雑さを軽減します。
利用可能な幅広い選択肢から適切なアルゴリズムとフレームワークを選択すると、
- 基盤となるすべてのインフラストラクチャを管理
- ペタバイト規模でモデルをトレーニングし、本番環境にデプロイします。
チュートリアルの内容
このチュートリアルでは、銀行で顧客が預金証明書(CD)に、登録するかどうかを予測する機械学習モデルを開発します。
モデルは、顧客の人口統計、マーケティングイベントへの応答、および外部要因に関する情報を含むマーケティングデータセットでトレーニングされます。
データには便宜上ラベルが付けられており、データセットの列には、銀行が提供する商品に顧客が登録されているかどうかが示されています。
このチュートリアルでは、データにラベルが付けられているため、教師あり機械学習モデルを実装しています。
(教師なし学習は、データセットがラベル付けされていない場合に発生します。)
- ノートブックインスタンスを作成する
- データを準備する
- モデルをトレーニングしてデータから学習する
- モデルをデプロイする
- MLモデルのパフォーマンスを評価する
ステップ1. ノートブックインスタンスを作成
Amazon SageMaker コンソールに移動します。
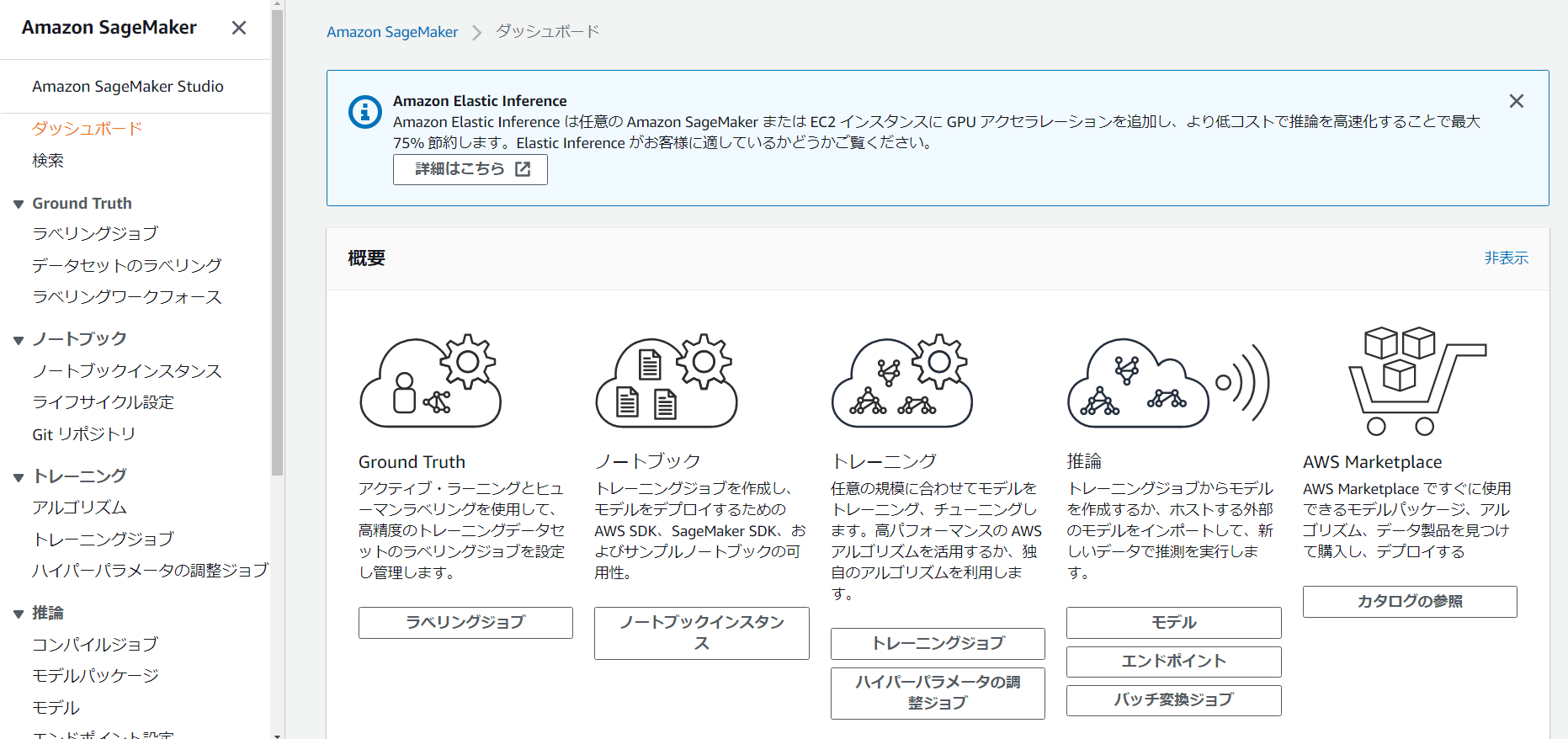
Amazon SageMaker ノートブックインスタンスを作成します。
ダッシュボードから[ ノートブックインスタンス]を選択します。
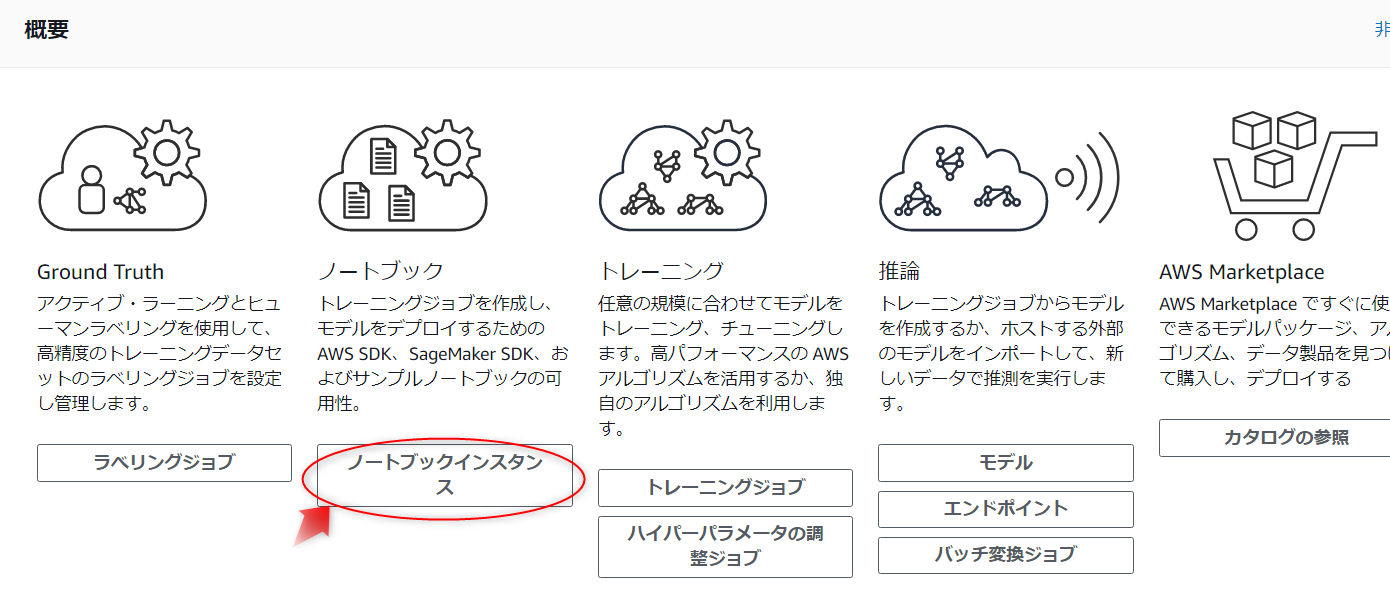
[ ノートブックインスタンスの作成]ページで、[ ノートブックインスタンス名]フィールドに名前を入力します。
このチュートリアルでは、デフォルトの Notebook インスタンスタイプを 「ml.t2.medium」 のままにしておきます。
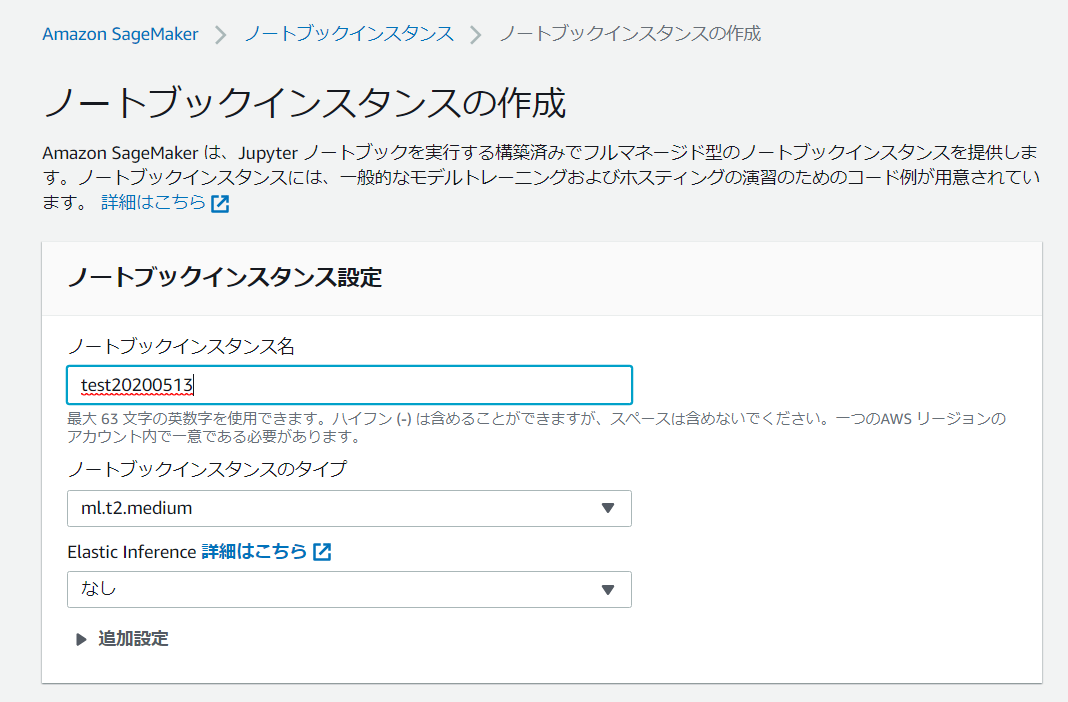
ノートブックインスタンスがデータにアクセスして、 Amazon S3 に安全にアップロードできるようにするには、IAMロールを指定する必要があります。
[ IAMロール]フィールドで、[新しいロールの作成]を選択して、Amazon SageMakerが必要なアクセス許可を持つロールを作成し、それをインスタンスに割り当てます。
または、既存のIAMロールを選択できます。
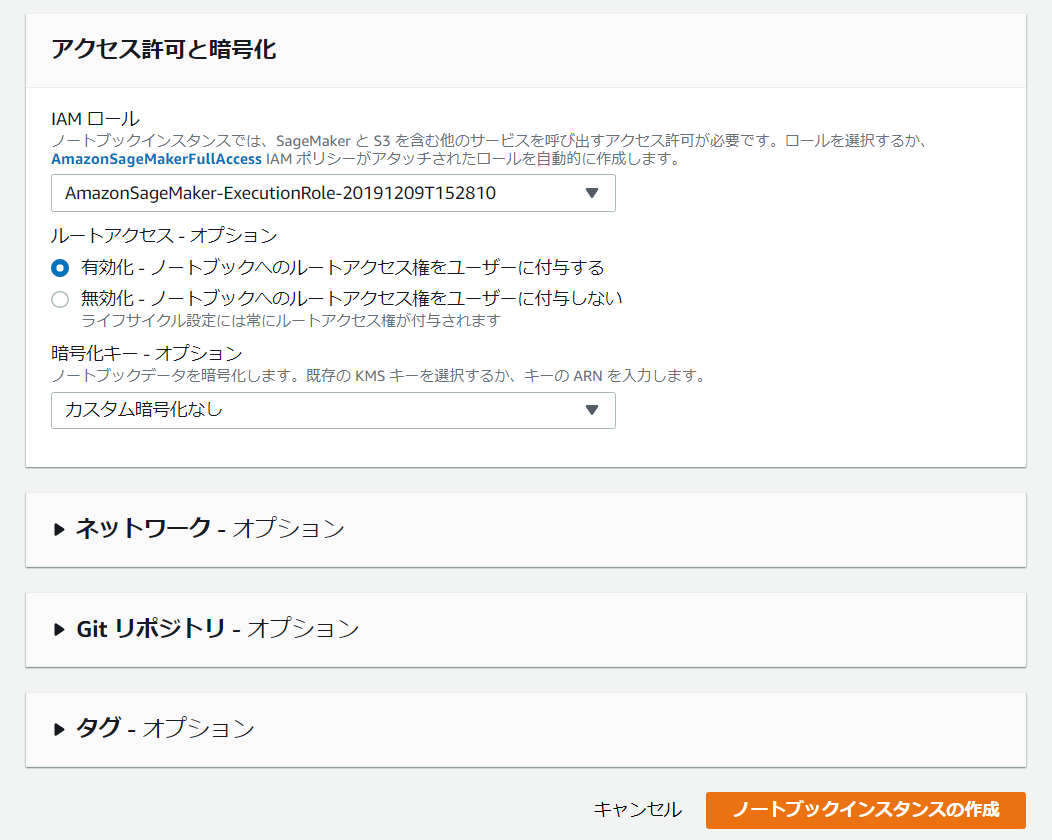
[ IAMロールの作成]ボックスで、[ 任意のS3バケット]を選択します。
これにより、Amazon SageMakerインスタンスがアカウント内のすべてのS3バケットにアクセスできるようになります。
ただし、代わりに使用するバケットがある場合は、[ 特定のS3バケット]を選択し、バケットの名前を指定します。
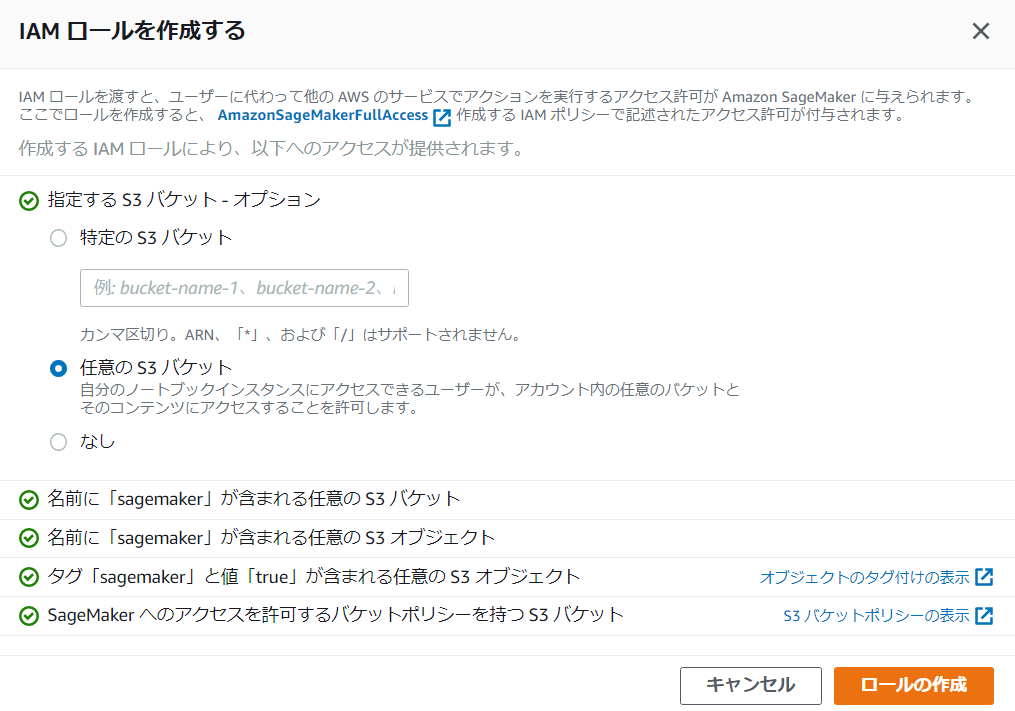
AmazonSageMaker-ExecutionRole-日付というロールを作成されたことを留意してください。
他のフィールドにはデフォルト値を使用します。[ ノートブックインスタンスの作成]を選択します。
[ ノートブックインスタンス]ページに、先程作ったノートブックインスタンスが[保留中]状態で表示されます。
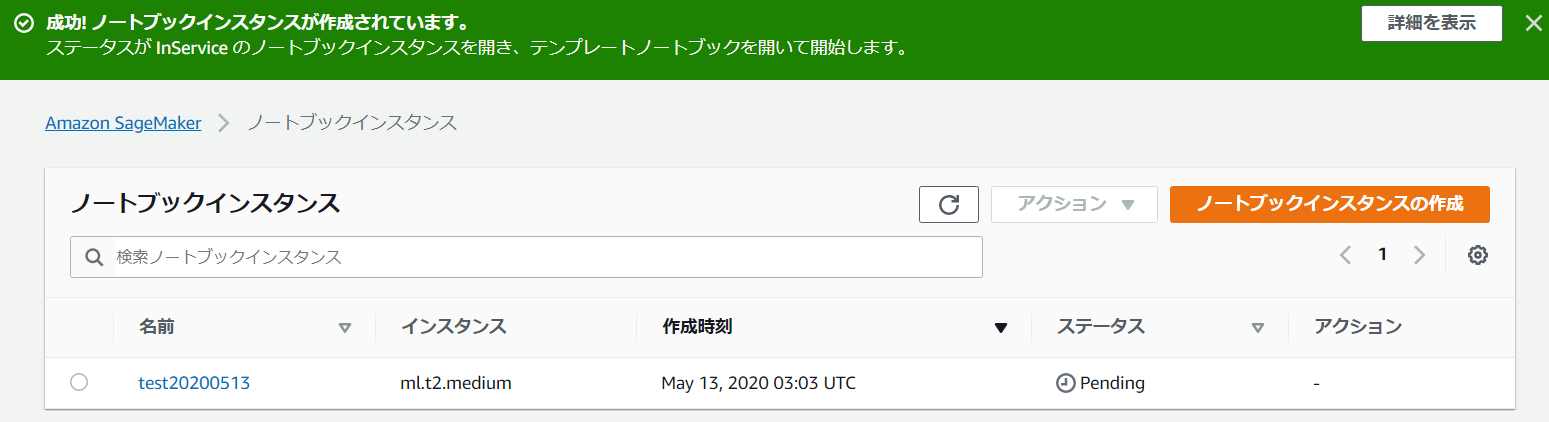
ノートブックインスタンスは、2分未満で Pending 状態から InService 状態に移行するはずです。
ステップ2.データを準備する
このステップでは、Amazon SageMakerノートブックを使用して、機械学習モデルのトレーニングに必要なデータを前処理します。
[Jupyterを開く]を選択します。
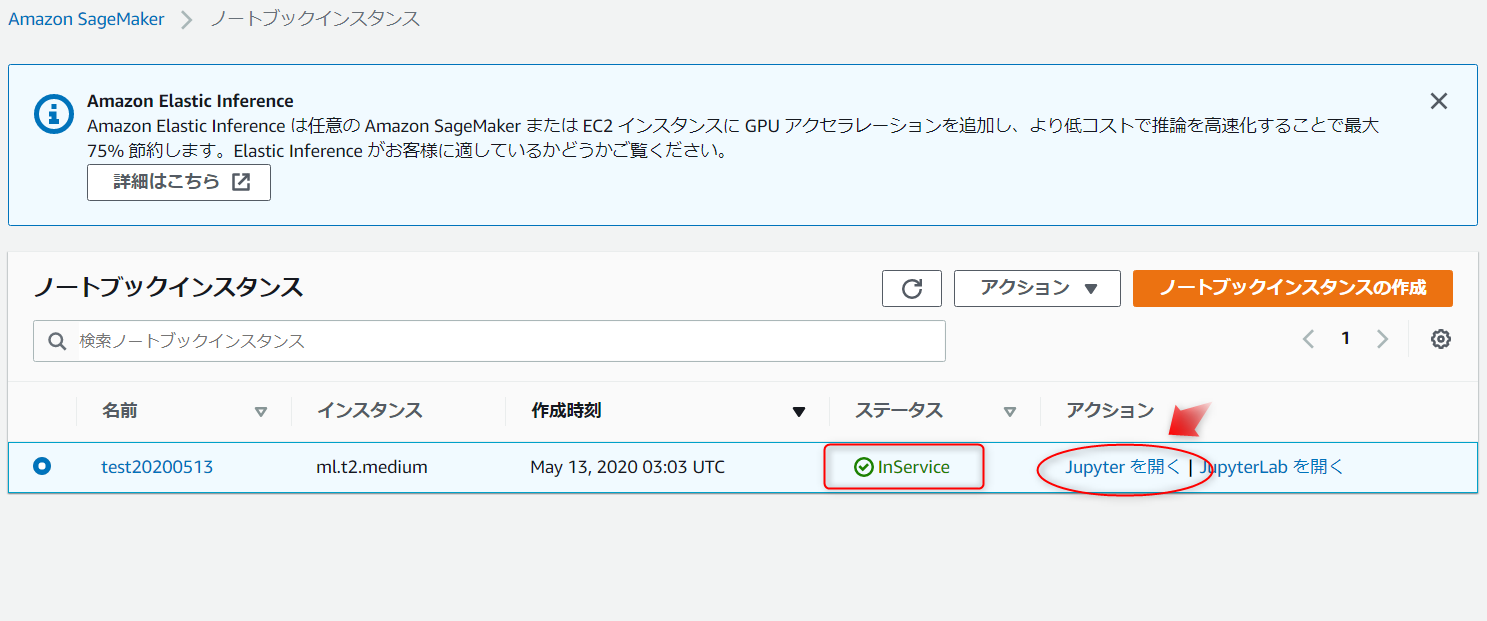
Jupyterが開いたら、 [ Files ]タブから[ new ]を選択し、次に[conda_python3]を選択します。
こんなページが立ち上がります。
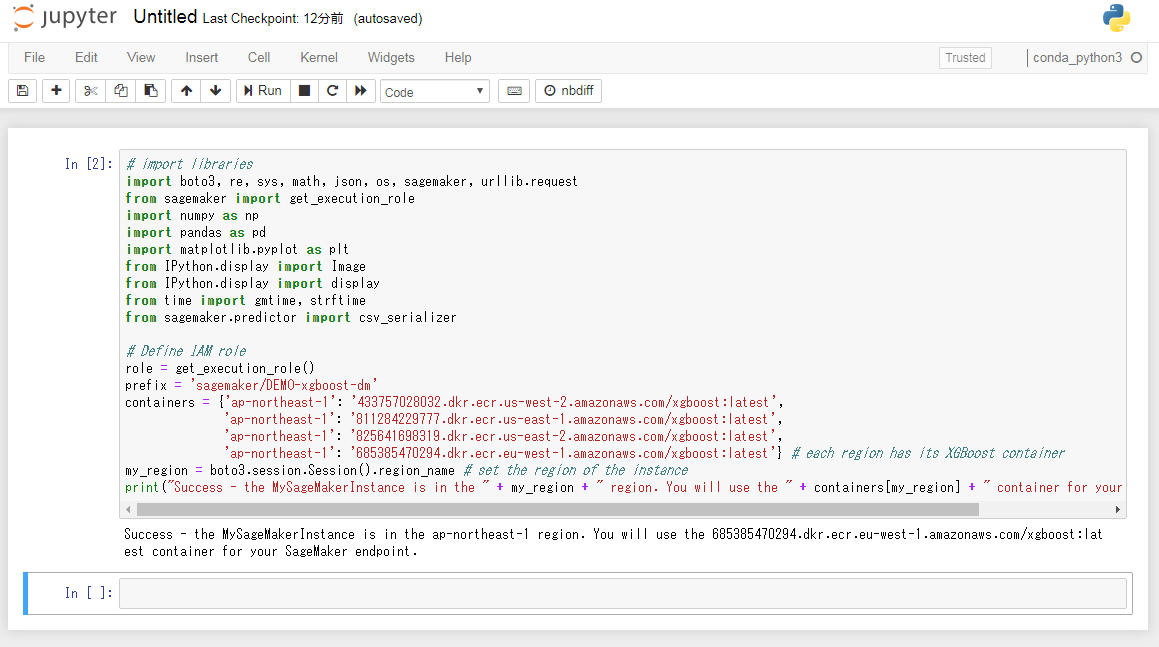
データを準備し、MLモデルをトレーニングしてデプロイするには、Jupyterノートブック環境でいくつかのライブラリをインポートし、いくつかの環境変数を定義する必要があります。
次のコードを緑の枠内にコピーし、[Run]をクリック、またはShift+Enterを押します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# import libraries importboto3, re, sys, math, json, os, sagemaker, urllib.request from sagemaker import get_execution_role import numpy as np import pandas as pd import matplotlib.pyplot as plt from IPython.display import Image from IPython.display import display from time import gmtime, strftime from sagemaker.predictor import csv_serializer # Define IAM role role = get_execution_role() prefix = 'sagemaker/DEMO-xgboost-dm' containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest', 'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest', 'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest', 'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost container my_region = boto3.session.Session().region_name # set the region of the instance print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + containers[my_region] + " container for your SageMaker endpoint.") |
コードの実行中、角括弧の間にアスタリスクが表示されます。
数秒後、コードの実行が完了し、アスタリスクが数字の1に置き換えられます。
右側の2番目のスクリーンショットに示すように、成功のメッセージが表示されます。
次はチュートリアルのデータを格納するS3バケットを作成します。
下記のコードをノートブックの次の緑の枠にコピーし、S3バケットの名前を変更して一意にします。
S3バケット名はグローバルに一意である必要があり、制限があります。
[Run]を選択します。
成功メッセージが表示されない場合は、バケット名を変更して再試行してください。
|
1 2 3 4 5 6 7 8 9 10 |
bucket_name = 'testbucket' # <--- ここを一意のS3バケット名にする s3 = boto3.resource('s3') try: if my_region == 'us-east-1': s3.create_bucket(Bucket=bucket_name) else: s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region }) print('S3 bucket created successfully') except Exception as e: print('S3 error: ',e) |

このチュートリアルで作成および使用されるリソースは、AWS無料利用枠の対象です。
手順を完了したら、リソースを終了することを忘れないでください。
これらのリソースを使用してアカウントが2か月以上アクティブである場合、アカウントの請求額は0.50ドル未満です。
後編に続きます。
公式サイトリンク
SageMakerの導入ならナレコムにおまかせください。
日本のAPNコンサルティングパートナーとしては国内初である、Machine Learning コンピテンシー認定のナレコムが導入から活用方法までサポートします。お気軽にご相談ください。
