大柳です。
最近、お客様のシステムや社内システム向けにAWS Lambdaでコードをよく書いています。
S3への読み書きなどの操作、ファイルの圧縮など、基本的なコードをまとめておくと調べる手間も省け、コード品質も一定に保てると考えて、社内へのナレッジとして整理したので、「AWS Lambdaの基本コード」シリーズとして公開します。
使い勝手と個人的な趣味からPython3系のコードでの紹介となりますが、AWS Lambda構築の手助けとなれば幸いです。
第1回目はAWS LambdaでS3上のファイルを取得しローカルに保存するコードを紹介します。
今回の構成
S3へのファイル格納をトリガーにLambdaが起動、S3に格納されたファイルを取得し、ローカルに保存します。
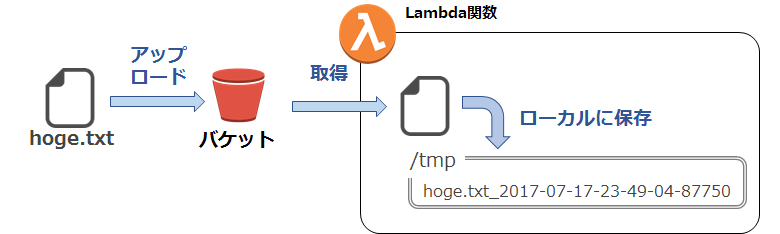
Lambdaではローカル保存先として/tmpディレクトリに対してファイルを読み書きできます。
LambdaでS3から取得したファイルに、何かの処理、例えばファイルの圧縮、画像ファイルに対するリサイズなどを行う場合に、ローカルへの保存が一時的に必要になります。そういったケースで/tmpへの保存はよく使うパターンです。
コード
コードは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# ①ライブラリのimport import urllib.parse import boto3 from datetime import datetime import random import subprocess print('Loading function') # ②Functionのロードをログに出力 s3 = boto3.resource('s3') # ③S3オブジェクトを取得 # ④Lambdaのメイン関数 def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] # ⑤バケット名を取得 key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') # ⑥オブジェクトのキー情報を取得 # ⑦ローカルのファイル保存先を設定 file_path = '/tmp/' + key + '_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S-') + str(random.randint(0,999999)) try: bucket = s3.Bucket(bucket) # ⑧バケットにアクセス bucket.download_file(key, file_path) # ⑨バケットからファイルをダウンロード # ⑩ファイルがダウンロードされているかlsコマンドで確認 print(subprocess.run(["ls", "-l", "/tmp"], stdout=subprocess.PIPE)) return except Exception as e: print(e) |
コードの説明
コードの内容は以下の通りです。
① ライブラリのimport…今回の処理に必要なライブラリを指定してインポートする。
②Functionのロードをログに出力…Lambdaのコードがロードされたことが分かるようにログにメッセージを出力する。
③S3オブジェクトを取得…boto3ライブラリからS3にアクセスできるようにするおまじない。
④Lambdaのメイン関数…S3にファイルが格納されると、この関数が実行される。
⑤バケット名を取得…eventオブジェクトにトリガーとなったS3の情報が格納されるので取得する。
⑥オブジェクトのキー情報を取得…バケット以下のディレクトリとファイル名を取得する。unquote_plusでエスケープされた文字(%xx)を単一文字に、「+」を空白に置き換えている。
⑦ローカルのファイル保存先を設定…/tmp/オブジェクトキー_日時(YYYY-mm-dd-HH-MM-SS)-ランダムな数字(0~999999)を保存先に指定している。日付とランダムな数字をつけているのは、Lambdaの/tmpディレクトリは複数のLamnda実行で共有される場合があり、ファイル名の重複を避けるため。
⑧バケットにアクセス…バケットを取得する。
⑨バケットからファイルをダウンロード…バケット上のkeyで指定したオブジェクトをfile_pathで指定した場所にダウンロードする。
⑩ファイルがダウンロードされているかlsコマンドで確認…subprocess.runでOSコマンドを実行できる。ls -l /tmpを実行して/tmp以下のファイルリストを取得して、ファイルがダウンロードされていることを確認している。
実行結果
トリガーとなるS3にファイルをアップロードしてみます。
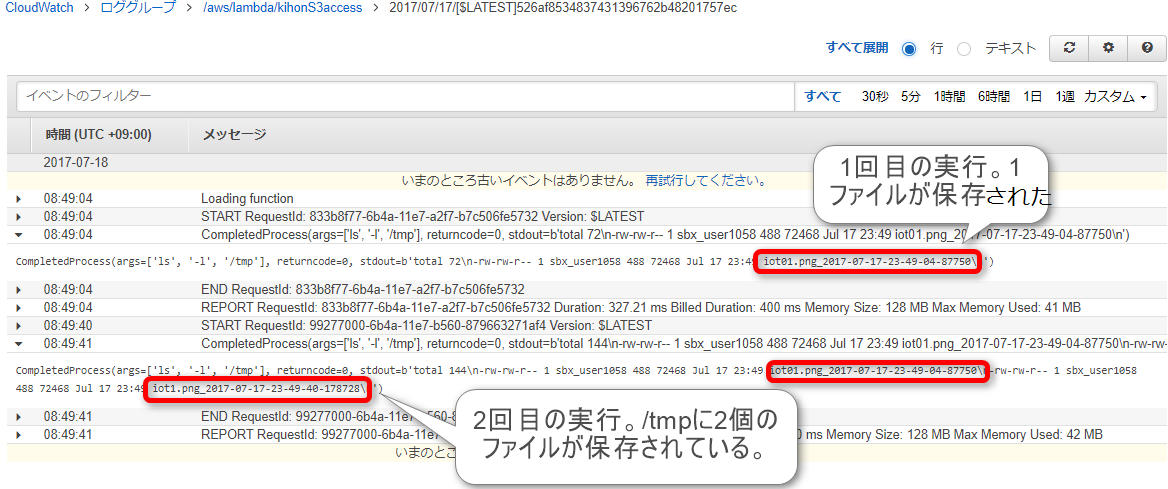
CloudWatch Logsからログを確認すると、lsコマンドの結果から、ファイルがローカルに保存されていることが確認できました。
また、2回目の実行時には/tmpに2個目のファイルが作成されていることが確認でき、/tmpディレクトリが複数のLamnda実行で共有されていることが分かります。
まとめ
S3へのファイル格納をトリガーとしてLambdaを起動、ファイルを一時保存するパターンはよく使うので、今回のコードがすべての基本になるかと思います。
次回はローカルに保存したファイルを圧縮して、S3にアップロードするコードを紹介します。
次回記事
【AWS Lambdaの基本コードその2】 S3へのファイル保存
【12月4日(金)15:00~】【AWS AI/MLオンラインセミナー】ABEJA様/ブレインズテクノロジー様/dotData Japan様との共同登壇!視聴無料!まだ申し込み可能です。
申し込みはこちら
