こんにちは!中の人です。
前回までのレシピではAmazon OpsWorks編ということでお話していたかと思いますが、今回からはAmazon Redshift編ということでRedshiftの使い方を紹介していきます。
今回は、「Amazon Redshift編~CSVファイルのデータをインポートしてみよう!~」と題して、まずはS3からのデータのインポート方法について説明いたします。
Redshiftでは、以下の様なデータのインポート方式に対応しています。
・ S3からCSV/TSVファイルのインポート
・ DynamoDBからの挿入
サンプルとして郵便局サイトから北海道の住所情報をダウロードして利用してみましょう。
http://www.post.japanpost.jp/zipcode/dl/oogaki.html
それでは実際に、作業をおこなっていきます!
事前準備
1. 上記URLより「01hokkai.lzh」をダウンロードし、解凍します。
解凍したファイルをテキストエディタで開き、UTF-8Nのフォーマットで保存します。
※日本語を扱う場合は必ずUTF-8Nで保存する必要があります。
2. 1で作成した01HOKKAI.CSVをRedshiftと同じリージョンのS3に対してアップロードします。
テーブルの作成
3. ここからはRedshiftに対する操作です。
4. SQL Workbenchを起動させ、Redshiftに対して接続します。
※SQL Workbenchのインストールおよび接続については、以下の「Redshiftをはじめてみよう!」のレシピを参照してください。
■ Amazon Redshift編~Redshiftをはじめてみよう!パート①~
■ Amazon Redshift編~Redshiftをはじめてみよう!パート③~
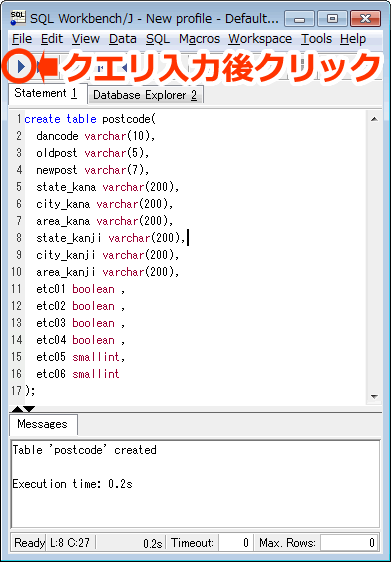
5. 郵便番号情報用にテーブルを作成します。
※エラーを出さないために、サイズは大きめにしております。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
create table postcode( dancode varchar(10), oldpost varchar(5), newpost varchar(7), state_kana varchar(200), city_kana varchar(200), area_kana varchar(200), state_kanji varchar(200), city_kanji varchar(200), area_kanji varchar(200), etc01 boolean , etc02 boolean , etc03 boolean , etc04 boolean , etc05 smallint, etc06 smallint ); |
データのインポート
|
1 |
copy postcode from 's3://[s3-backet名]/01HOKKAI.CSV' CREDENTIALS 'aws_access_key_id=[your access key];aws_secret_access_key=[your secret access key]' delimiter ',' REMOVEQUOTES; |
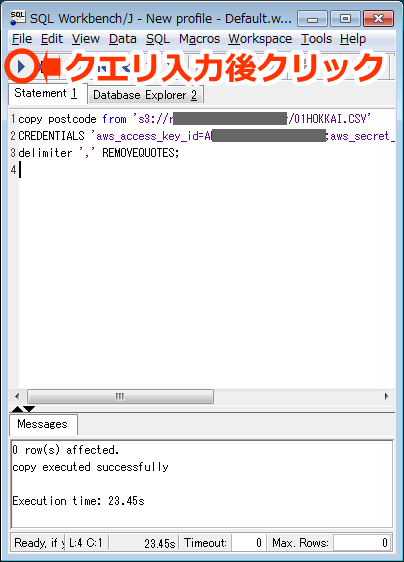
6. 上のコマンドをより詳しく説明すると、以下のようになります。
| copy [インポート先のtable] from ‘[インポートするCSV]’ | インポートするCSVとデータ保存先のテーブルを指定します。 |
| CREDENTIALS ‘aws_access_key_id=[your access key];aws_secret_access_key=[your secret access key]’ | AWSの証明書キーを入力します。 |
| delimiter ‘,’ | 区切り文字の指定です。TSVの場合は’\t’を指定します。 |
| REMOVEQUOTES | 今回のCSVデータは各カラムが”(ダブルクオーテーション)で囲まれているので、取り除く指定をします。 |
データの確認
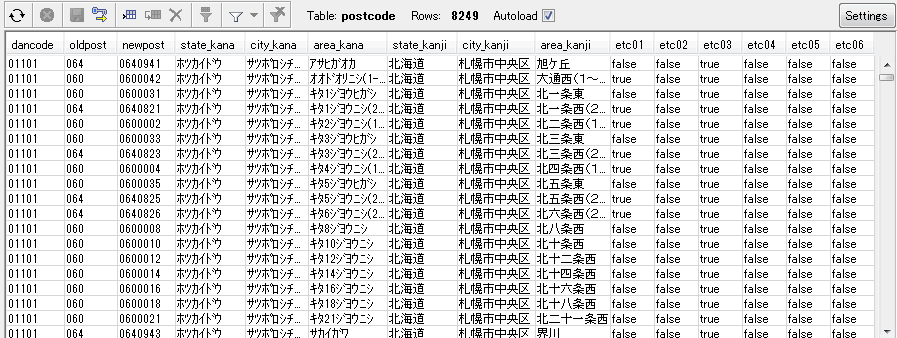
7. SQL workbenchのタブを「Database Explorer 2」に切り替えます。
左下のテーブル一覧から「postcode」を選択し、右側より「Data」を参照すると、キャプチャのようにデータがインポートされていることが確認できます。
いかがでしたでしょうか?
皆さんがアクセスできる大きなデータということで思いついたのが郵便番号情報でしたので、郵便番号を参考にさせて頂きました。
是非、お手元にあるデータでも試していただければと思います。
次回は「Amazon Redshift編~MySQLのデータをインポートしてみよう!~」と題して、MySQLからのデータのインポート方法について紹介させていただきます。
お楽しみに!
