はじめに
前回に引き続き、Amazon Pollyを使用した、精密な発音をする音声の読み上げの機能について
AWS はどのようにして最適化を行っているのか、についてご紹介いたします。
しばし長くなっておりますがご了承願いますm(_ _)m
日本語の発音をコントロールする方法
単語の区切りを指定するだけで、目的の発音を示すことができる場合があります。
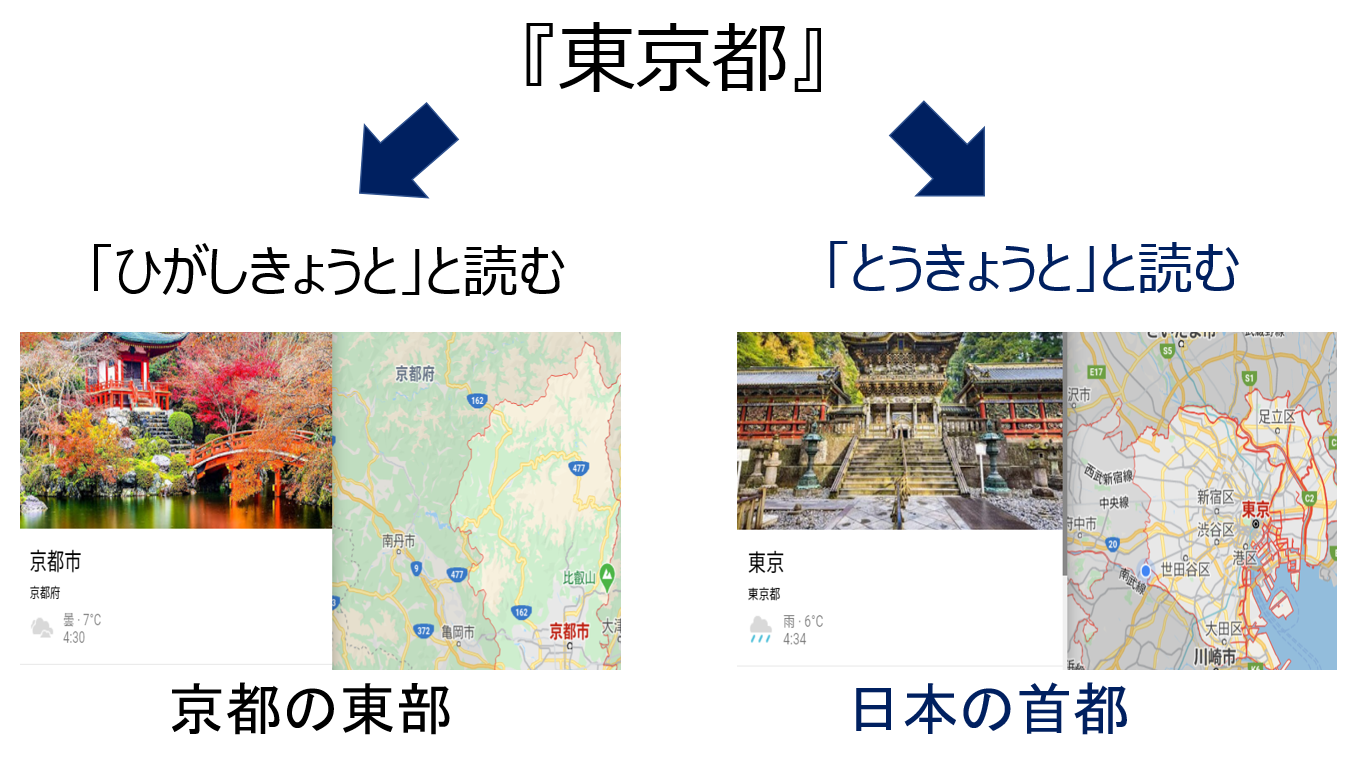
『東京都』を「とうきょうと」と読むと「東京」と「都」の、 2 つの単語で構成されていると解釈できます。
しかし、「ひがしきょうと」と読み、「京都の東部」を指すことで、
この語は「東」と「京都」の、 2 つの単語で構成されていると解釈できます。
その1.単語境界タグ<w>...</w>を適用する
単語境界タグを適用することにより、『東京都』のデフォルトの発音が上書きされ、「とうきょうと」ではなく「ひがしきょうと」と発音されます。
このタグは、個々の単語を囲むことによって TTS の発音をコントロールするために、使用できる SSML (音声合成マークアップ言語)の形式です。
|
1 2 3 |
<w>東</w><w>京都</w> 東<w>京都</w> <w>東</w>京都 |
その2.振り仮名で発音をコントロールする
単語の区切りを指定する方法は便利ですが、合成したい語が複数の単語で構成されている場合にのみ有効です。
しかし単一の単語(または単一の文字)が、複数の発音を有することも多々あります。
例1:東京の地名である『日本橋』は「にほんばし」
例2:大阪の同じ地名を指す場合は「にっぽんばし」
と発音されます。文脈がなければ、正しい発音がわかりません。
発音を指定する最も簡単な方法は、括弧内に振り仮名表記をすることです。
日本橋(にほんばし)
★pollyの読み上げ音声
日本橋(にっぽんばし)
★pollyの読み上げ音声
振り仮名表記だけではうまく機能しない
その2の手法だと、振り仮名が表示されてしまうため、用途によっては望ましくない場合もあります。
振り仮名が Amazon Polly が認識する、発音の1 つと一致しない場合は、うまく機能しません。
例:「海(やま)」
『海』という漢字に対して「やま」という振り仮名を当てても振り仮名としては認識されません。
例:「七音(どれみ)」
標準的ではない文字の読み方をする人名の場合に当てはまります。
Amazon Polly の特別な音声形式
この問題を克服するために、Amazon Polly には日本語用の特別な SSML タイプ属性があり、振り仮名を用いて発音を指定できます。
次の例に示すようにルビ(ruby)という、音素(phoneme)タイプのタグを使用します。
デフォルトの発音が「にほんばし」である『日本橋』という表記に、「にっぽんばし」という振り仮名を適用できます。
|
1 |
<phoneme type="ruby" ph="にっぽんばし">日本橋</phoneme> |
この構文を使用すると、任意の振り仮名(発音)を任意の文字列に適用できます。
このルビタグは、単語の区切りに関係なく使えます。
次の例のように、送り仮名を除いた漢字部分のみにタグを付けることもできます。
|
1 |
<phoneme type="ruby" ph="い">行</phoneme>った |
|
1 |
<phoneme type="ruby" ph="おこな">行</phoneme>った |
振り仮名が Amazon Polly が認識する発音の 1 つと一致しない場合、モデルを使ってアクセントを予測しますが、この予測されたアクセントは正しくない場合があります。
たとえば、ルビタグを使って『山』という文字に、「うみ」という読みを強制します。
「うみ」は『山』という文字の、認識されていない発音のため、想定外のアクセントとなる場合があります。
ph 属性について
ph 属性は、平仮名または片仮名を使うことができます。
ただし、振り仮名が有効な形式でない場合、指定された発音は効果がなく、タグで囲まれた文字列に対して予測されたデフォルトの発音になります。
たとえば、数字や記号など、仮名以外の文字を振り仮名に含めることはできません。
また、二重の長音符(長音記号)などの、一般的ではない振り仮名の使用も無効とみなされます。
ルビタグが無効になる例
次の例では、振り仮名の形式が正しくないため、ルビタグは有効になりません。
|
1 2 3 4 5 |
<phoneme type="ruby" ph="にっぽんばし2">日本橋</phoneme> <phoneme type="ruby" ph="にっぽんばし(おおさか)">日本橋(大阪)</phoneme> <phoneme type="ruby" ph="にっぽーーばし">日本橋</phoneme> |
次の例のようにタグの内部に文字列のない状態でルビタグを使用すると、何も合成されません。
|
1 |
<phoneme type="ruby" ph="にっぽんばし"></phoneme> → 無音 |
その3.発音仮名でコントロールする
ルビタグはアクセントを細かくコントロールできないため、目的通りにならない場合があります。
「雨」⇒「あ↗め」、「飴」⇒「あめ↘」のように、アクセントが変わることで単語の意味が変わることがあります。
また、同じ単語であっても、文脈に応じてアクセントが変わる場合があります。
「音声」という単語の発音は、「オ↗ンセー」のように、最初の拍 (音節) にアクセントが付きます(頭高型)。
「合成」という単語はアクセントのない「ゴーセー」と発音されます(平板型)。
ただし、2 つの単語が組み合わさって、「音声合成」という複合語が形成されると、アクセントの位置が移動し、「オ↗ンセーゴーセー」ではなく、「オンセーゴ↘ーセー」と発音されます。
したがって、語や文章のアクセントを予測することは、TTS にとって容易ではありません。
ML モデルを使ってある程度は解決できますが、時々間違うこともあります。
x-amazon-pron-kanaを使う
x-amazon-pron-kana は、発音仮名と呼ばれる発音表記を使用しており、アクセントを直接かつ明示的に指定することができます。
「毎日新聞を読む」という文章の、 2 つの読み方を区別できます。
例1:「毎日、新聞を読む」という意味
例2:「毎日新聞という新聞を読む」という意味
最初のパターンは、現在 Amazon Polly が予測するデフォルトのアクセントです。
例2のアクセントを適用する方法
|
1 |
<phoneme alphabet="x-amazon-pron-kana" ph="マイニチシ'ンブン">毎日新聞</phoneme>を読む |
x-amazon-pron-kana(発音仮名)は片仮名で表記され、振り仮名に似ていますが、いくつかの点で異なります。
振り仮名は必ずしも、発音を正確に反映するわけではありませんが、発音仮名は忠実に反映します。
例:1. 助詞「は」は、発音仮名では「ハ」ではなく「ワ」と表記
例:2. 助詞「へ」は、「ヘ」ではなく「エ」と表記
例:3. 助詞「を」は「ヲ」ではなく「オ」と表記
「格子」と「子牛」は、振り仮名では両方とも『こうし』ですが、発音仮名ではそれぞれ「コーシ」と「コウシ」と、表記が異なります。
アクセントの違い
発音仮名では、アポストロフィはピッチが下がる位置を示します。
アポストロフィがない場合、アクセントがないものとみなされます(平板アクセント)。
次の例は、アクセントの違いを示しています。
|
1 |
<phoneme alphabet="x-amazon-pron-kana" ph="カ'レシ">彼氏</phoneme> |
|
1 |
<phoneme alphabet="x-amazon-pron-kana" ph="カレシ">彼氏</phoneme> |
各単語には、最大 1 つのアクセントを含めることができます。
この単語とは韻律語を意味し、各単語につき最大 1 箇所、ピッチが下がる拍を指定できるというわけです。
タグ付けする語句に複数のアクセント(ピッチの複数のピーク)がある場合は、各単語の発音仮名をスペースで区切るか、別々のタグで囲む必要があります。
イントネーションの違い
次の例は、韻律語の分け方の違いによる、イントネーションの違いを示しています。
同じ句をさまざまな方法で韻律語に分割できるため、すべて同じ発音仮名で表されますが、スペースの位置によってイントネーションが異なります。
|
1 2 |
例1 <phoneme alphabet="x-amazon-pron-kana" ph="バ'ス ガスバ'クハツ">バスガス爆発</phoneme> |
|
1 2 |
例2 <phoneme alphabet="x-amazon-pron-kana" ph="バ'ス ガ'ス バクハツ">バスガス爆発</phoneme> |
|
1 2 |
例3 <phoneme alphabet="x-amazon-pron-kana" ph="バスガスバ'クハツ">バスガス爆発</phoneme> |
phoneme alphabet=”x-amazon-pron-kana” は phoneme type=”ruby” とは異なり、
その周囲に単語境界を強制挿入するので、送り仮名のある単語に x-amazon-pron-kana を用いる場合、送り仮名を含む単語全体にタグ付けする必要があります。
振り仮名(片仮名表記)と発音仮名の違い

まとめ
日本語の TTS システムの開発において、その書記体系の複雑さにより、生じるいくつかの課題について説明しました。
このサービスでは、いくつかの ML モデルを使用して、発音およびアクセントを予測しますが、
日本語固有の SSML タグを使用することで、Amazon Polly の自然な日本語音声のコンテンツを、より簡単に作成できます。
是非ご活用ください。
