はじめに
今回は、Amazon SageMaker Studio の追加機能の一つの可視化サービス、SageMaker Data Wrangler を触ってみようと思います。
- データのインポート
- データフローの作成
- データの可視化、前処理、追加、結合などを行う
- 作成したデータフローのエクスポート
の流れで SageMaker Data Wrangler を使っていきます。
SageMaker Data Wrangler を使いこなして、Amazon Sagemaker Studio をもっと便利に使えるようにしてみましょう!
SageMaker Data Wrangler の概要
AWS の各種サービスからデータをインポートし、データの可視化(リアルタイムで!)や変換の処理を GUI 上で行えるサービスです。
実際に行った処理をノートブックとしてエクスポートすることもできるので手元で処理して可視化して、処理して可視化して、、、という縦長ノートブックとのにらめっこからオサラバできそうですね。
名前が似ている AWS Data Wrangler というオープンソースの Python ライブラリがありますが、こちらとは別物のようです。
今回紹介されている Amazon SageMaker Data Wrangler はあくまでも SageMaker Studio の追加機能、という位置づけのようです。
SageMaker Data Wrangler の機能
SageMaker Data Wrangler は SageMaker Studio の追加機能であり、
- ETL 処理をグラフィカルに記述する flow ファイルの作成
- インポートするデータの選択
- データの変換および分析の記述
- 記述した処理をエクスポート
という流れで ETL 処理をサポートする機能であるといえます。
実際に触ってみる
今回は kaggle にある COVID-19 Dataset を用いて実際に Data Wrangler を使ってみました。
まずは Amazon SageMaker Studio に入ります。
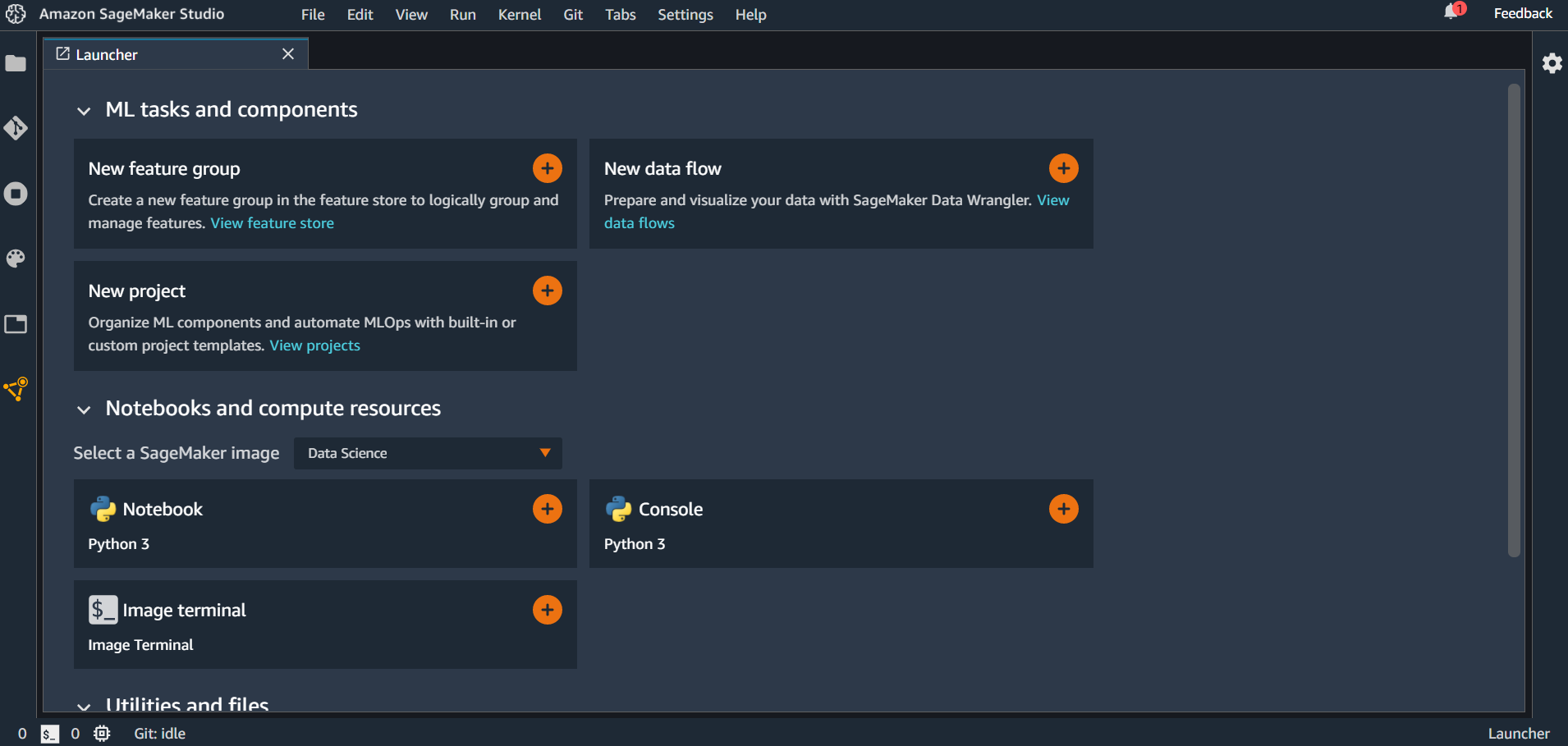
データのインポート
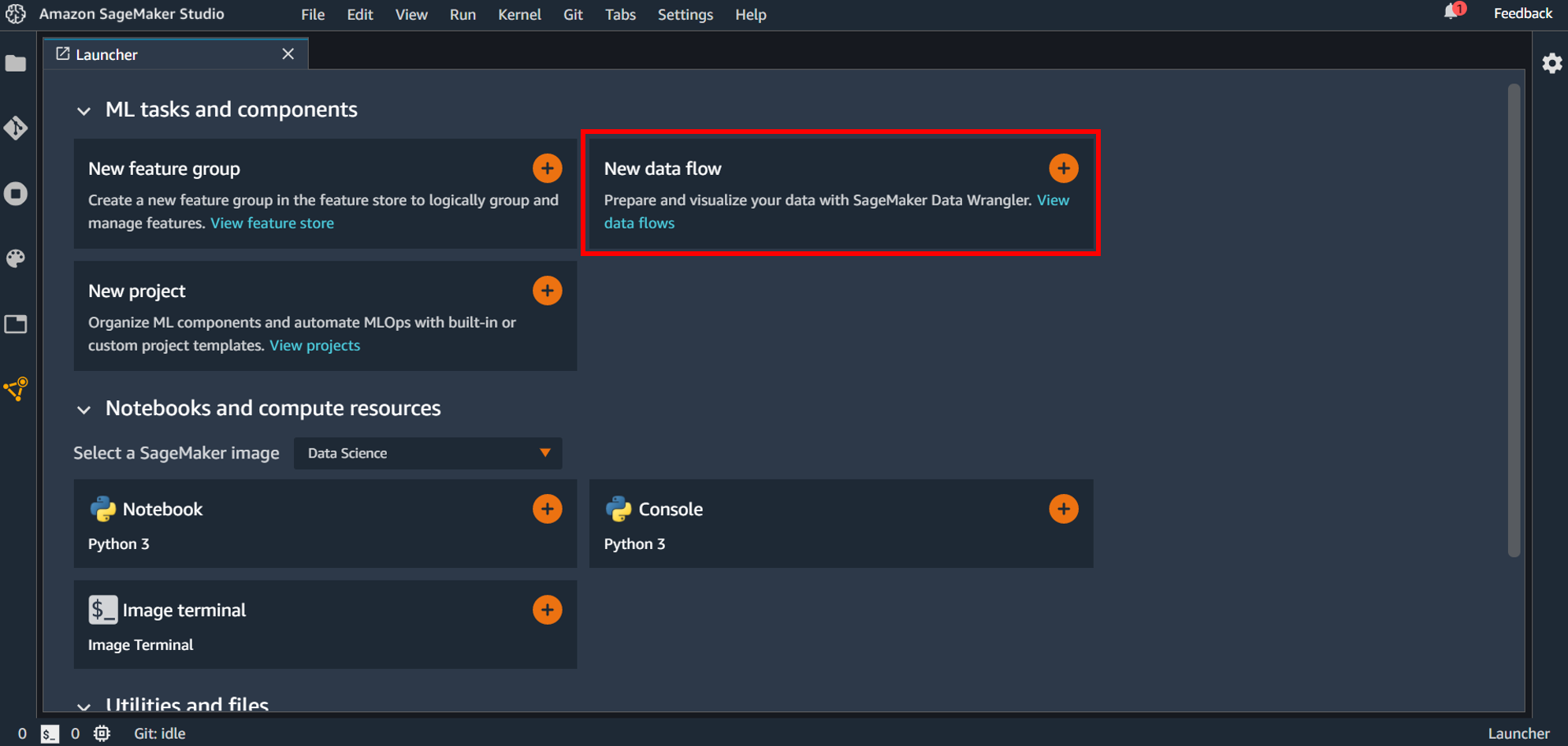
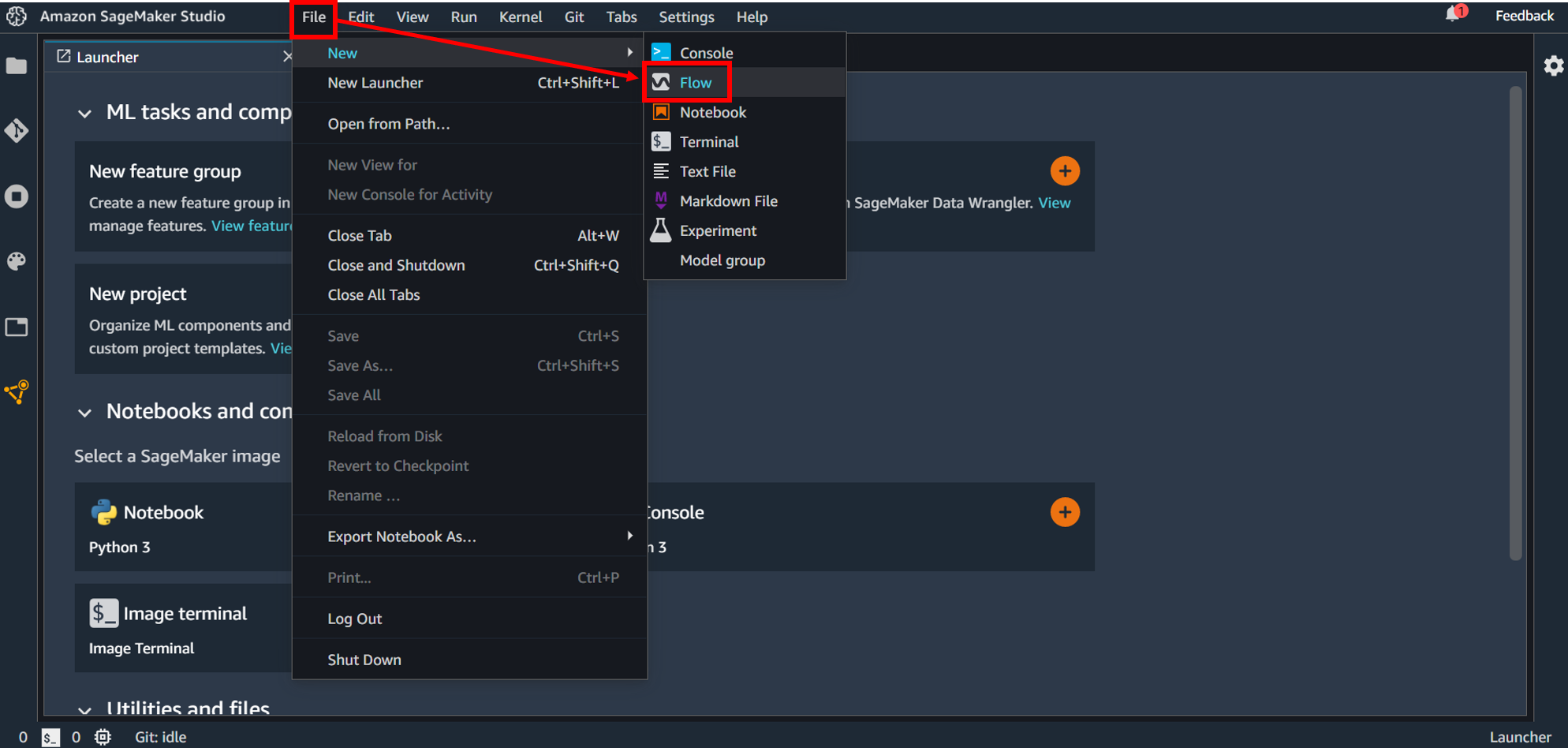
Data Wrangler を使うには最初に flow ファイルを作成します。最初のランチャー画面にある「New data flow」の+ボタンをクリックするか、画面上部の「File」→「New」→「Flow」としてファイルを作成します。
flow ファイルを作成すると「untitled.flow」というデータが生成されます。(名前の変更もできます。)インポートできるデータソースとしては Amazon S3 と Amazon Athena が選択できます。「Add data source」をクリックしてみると Redshift が選択できるようになっていました。
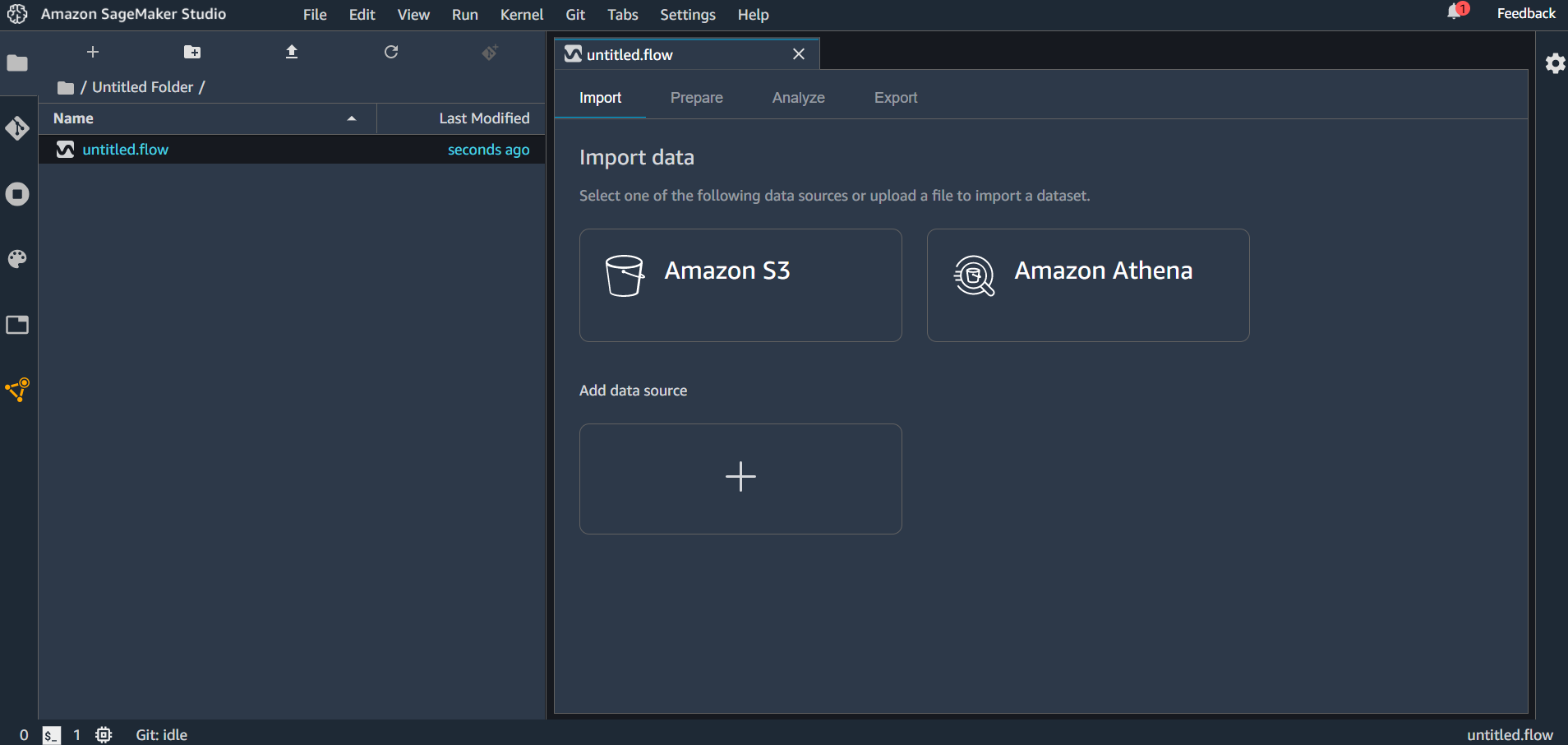
flow ファイルには4種類のタブがあり、それぞれ
- Import → データのインポート設定を行う
- Prepare → グラフィカルにデータ変換・分析のフローを記述する
- Analyze → 分析結果の表示
- Export → エクスポートするコンポーネントを選択し、エクスポートする
ということが行えます。
S3 に事前にアップロードしておいたファイルをインポートしていきます。「Amazon S3」を選択すると、バケット選択画面になります。
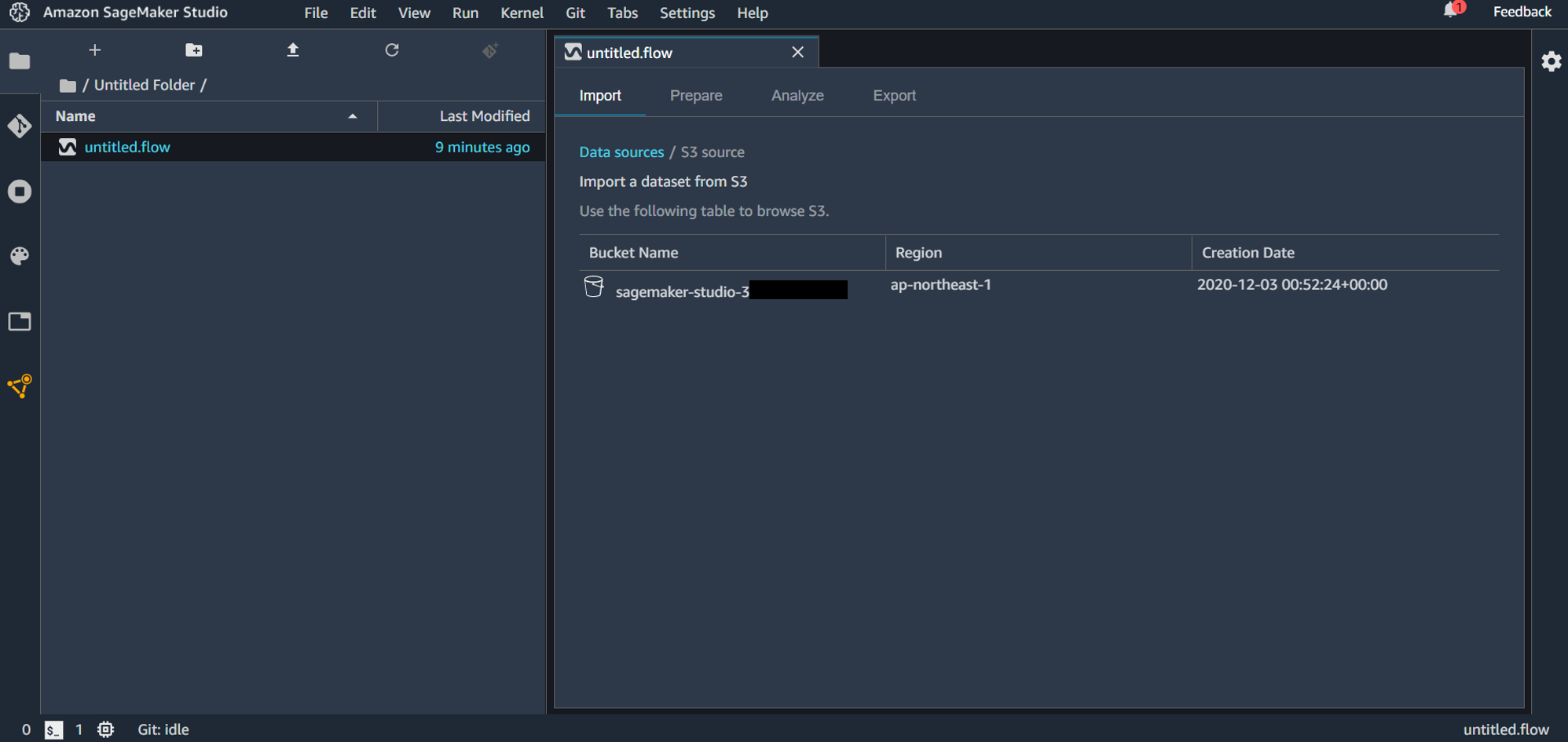
バケットを選択して、アップロードするファイルを選択します。S3 からのアップロードは CSV または Parquet が対応しています。

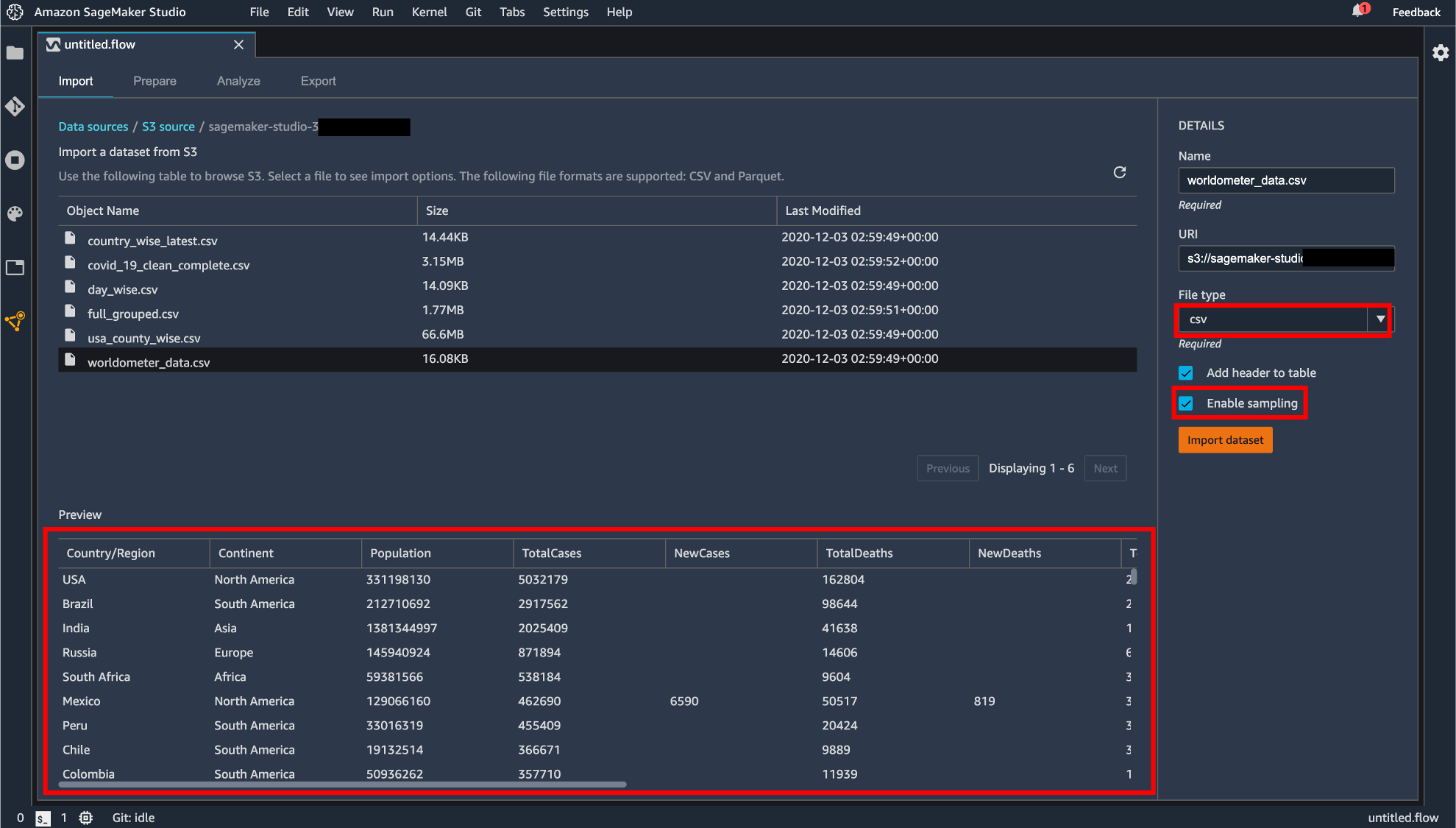
ファイルを選択すると画面下部にプレビュー画面が表示されます。拡張子がついていないファイルは画面右の「File Type」から CSV か Parquet を選択する必要があります。「Enable sampling」が有効になっている場合、インポートされるファイルが最大100MBに制限されます。設定が終わったら「Import dataset」をクリックします。
データフローの作成
インポートが完了すると、Prepare タブに遷移し、今回作成するデータフローがグラフィカルに表示されます。
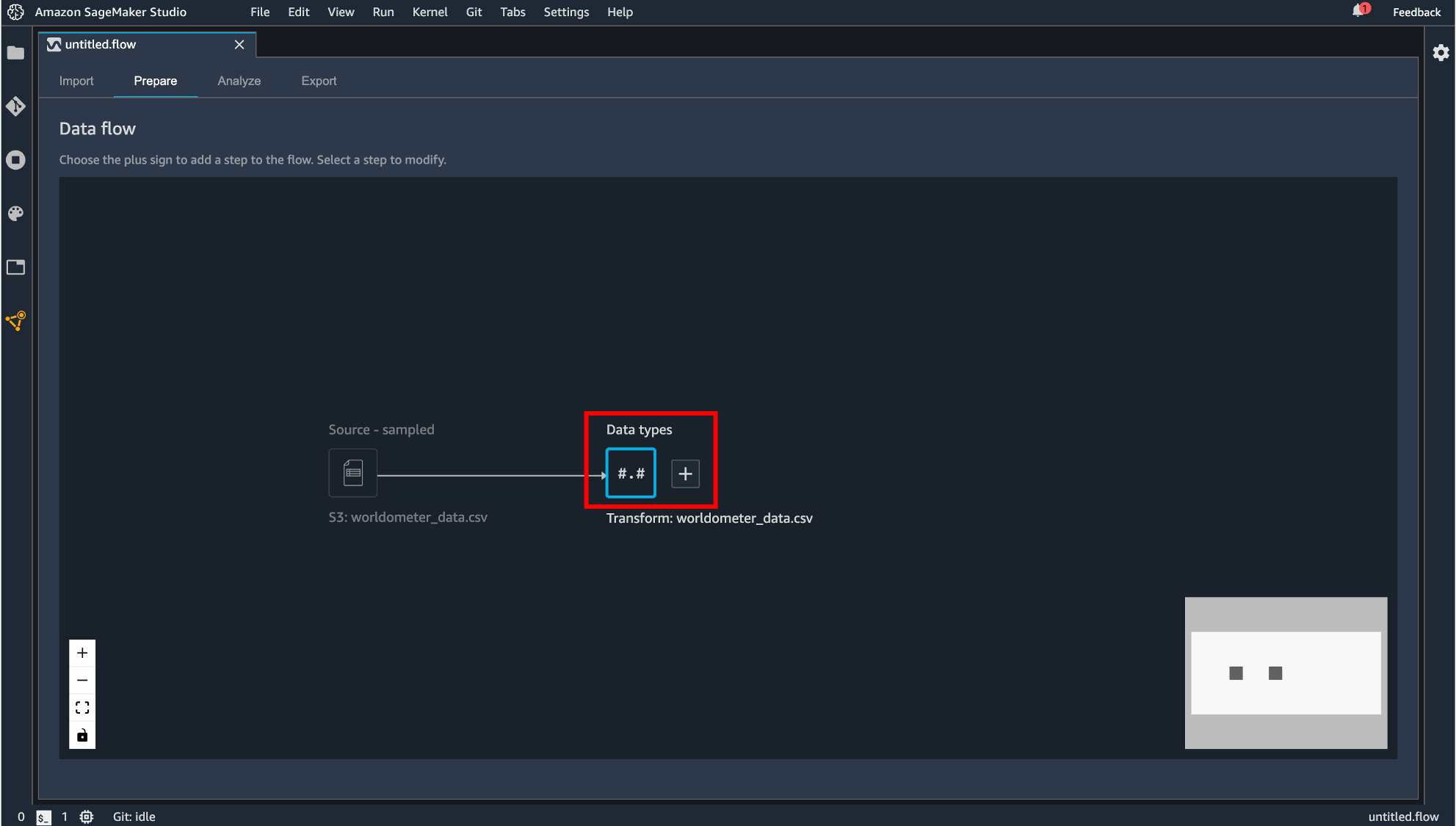
Data Wrangler はインポートされたデータのデータ型を自動で推測し、データフレームを作成します。表示されている「Data types」というコンポーネントが自動生成されるデータフレームになります。
生成されるコンポーネントはドラッグすることで動かすこともできます。
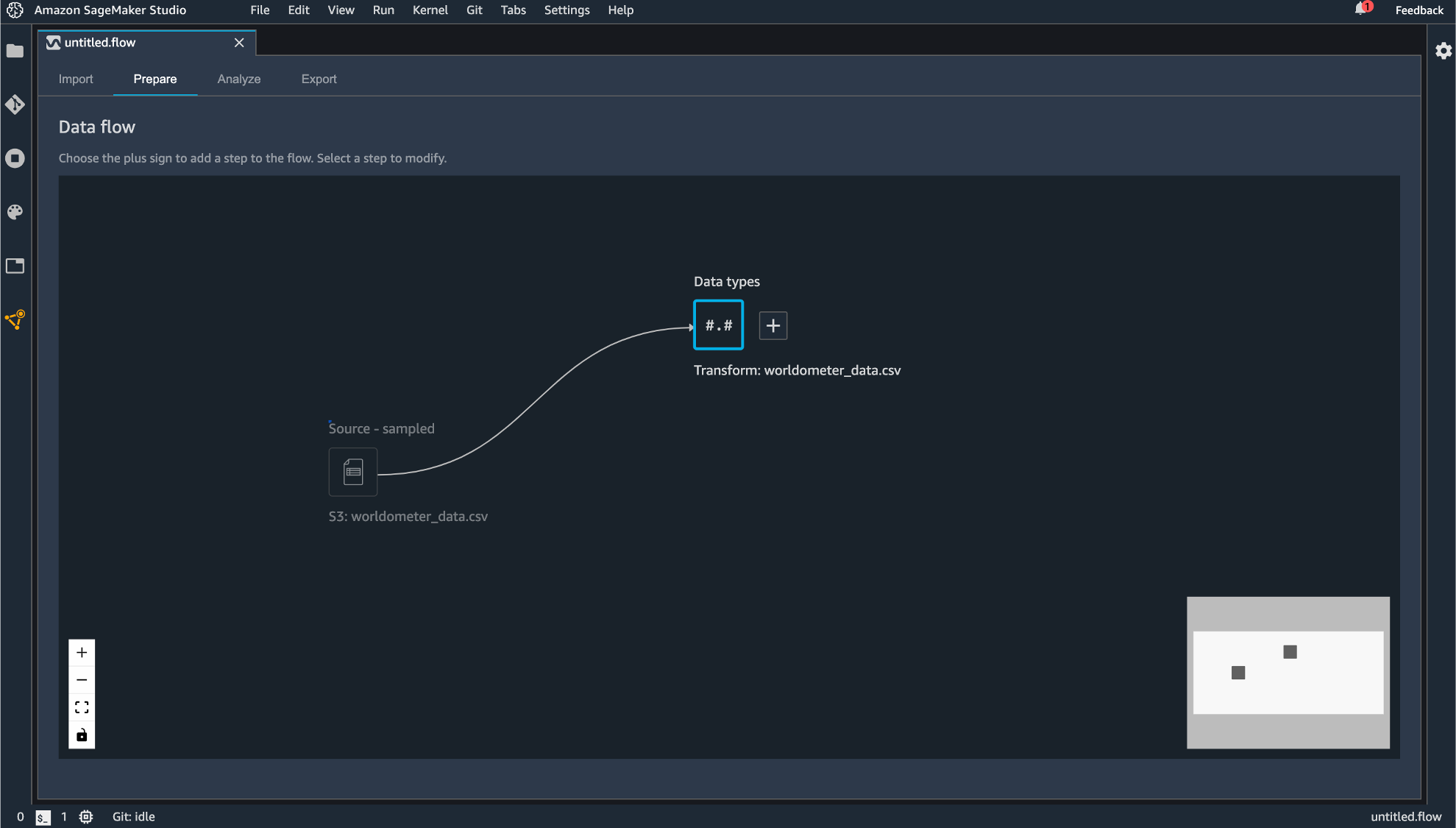
「Data types」の横にある+ボタンをクリックすると後続の処理を追加できます。
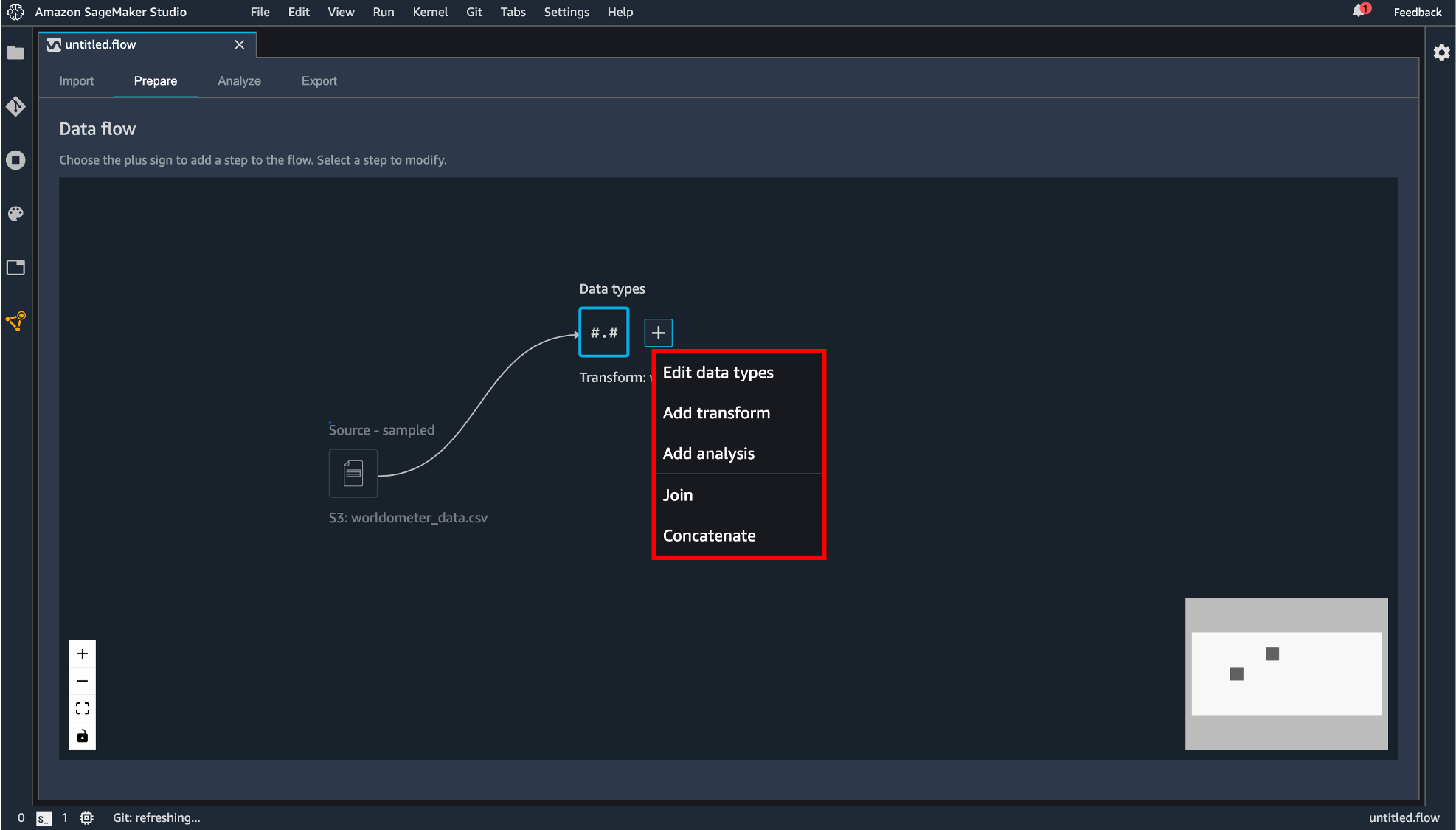
後続処理として追加できるコンポーネントには次のものがあります。
edit-data-types
データインポート時に自動生成されたデータフレームの各カラムのデータ型の変更が行えます。「Type」のプルダウンから選択できます。
変更する型を指定したら「Preview」で変更後のデータフレームが表示され、よければ「Apply」します。

add-transform
読み込み時にデータフレームの変換処理を記述します。
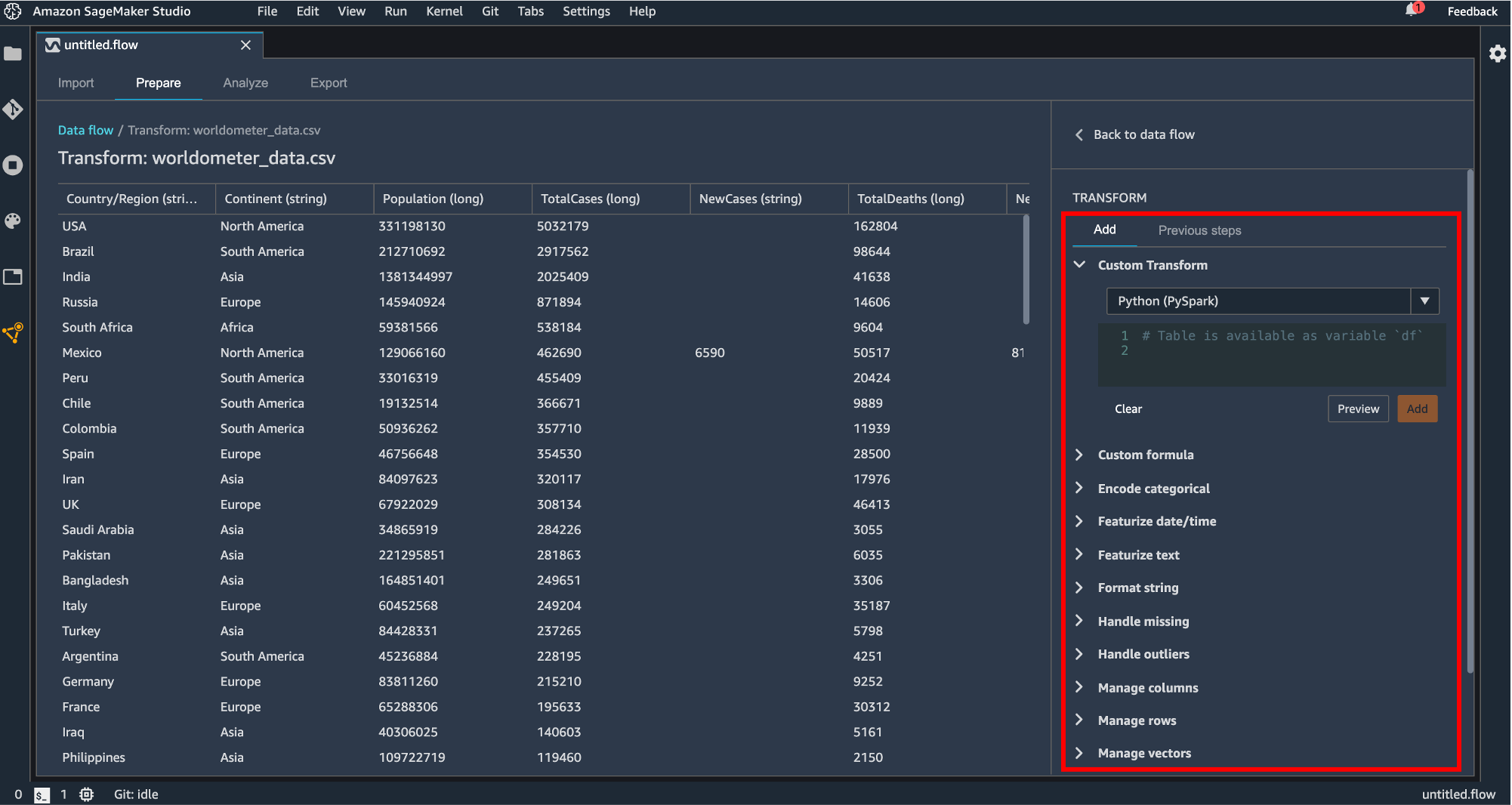
変換できる処理は次のようになっています。
- Custom Transform
Python(Pandas, Pyspark)または SQL(Spark SQL) で変換処理を記述します。
- Custom formula
新しいカラムを Spark SQL でクエリ書いて追加します。
- Encode categorical
カテゴリのカラムをプルダウンで指定して One-hot encode または Ordinal encode します。欠損値の処理も Skip, Error, Keep, Replace with NaN から選択することができます。
- Featurize date/time
date/time の型のデータを数値やベクトル表現に変換できます。
- Featurize text
自然言語のカラムを Character statistics, vector に変換できます。Character statistics には単語数や文字数などがあり、新しい出力カラムが生成されます。
- Format string
文字列のフォーマット(大文字、小文字、右寄せ、左寄せなど)を指定して変換してくれます。
- Handle missing
欠損値の処理を指定します。変換の方法を impute, drop missing などから指定してそれぞれの方法に対して詳細な設定ができます。(impute ならカラムの型がなんであり、中央値か平均を代入する、など)
- Handle outliers
外れ値の処理をかけます。標準偏差や quantile などを指定してどのように処理するか設定します。
- Manage columns
カラムの移動、削除、複製、リネームなどを行います。
- Manage rows
ソートやシャッフルをすることができます。
- Manage vectors
数値データ列とベクトル列を Assemble や Flatten で処理できます。
- Parse column as type
データ型を指定してキャストします。
- Process numeric
標準化を行ったりロバストスケーラーや最大値最小値の範囲でスケーリングします。処理には Spark が使われているようです。
- Search and edit
データの検索と、検索した値の編集ができます。置換や区切り文字で分割もできます。
- Validate string
カラムに対して条件を指定して True または False で表現されるカラムを生成します。
追加した変換処理を Apply するとコンポーネントが追加されます。
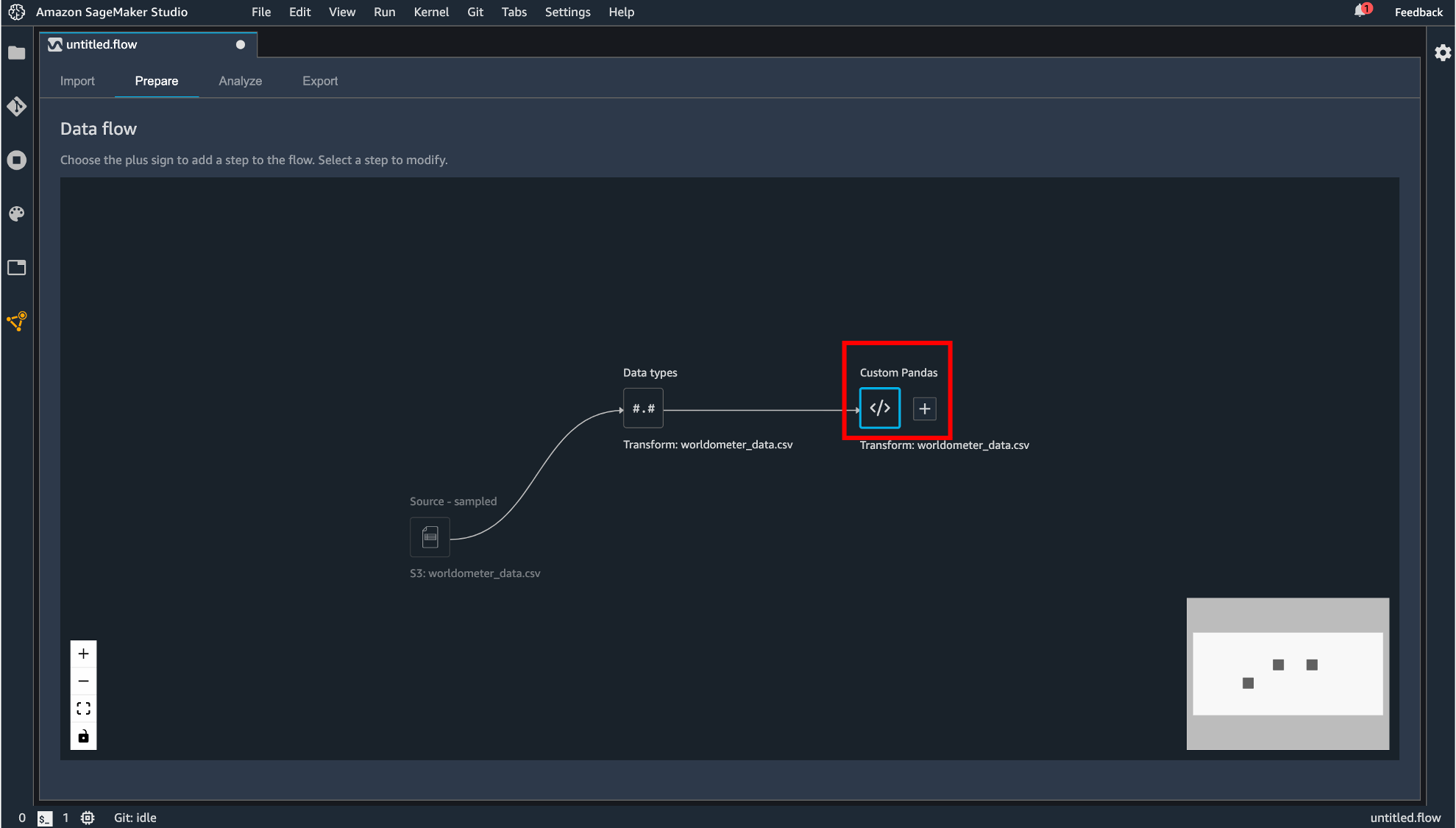
add-analysis
変換処理などを行ったデータを可視化できます。「Configure」タブではヒストグラムや散布図などを指定して表示させることができます。「Code」タブでは Pandas で記述できます。「Create」ボタンで描画した図を保存することができます。
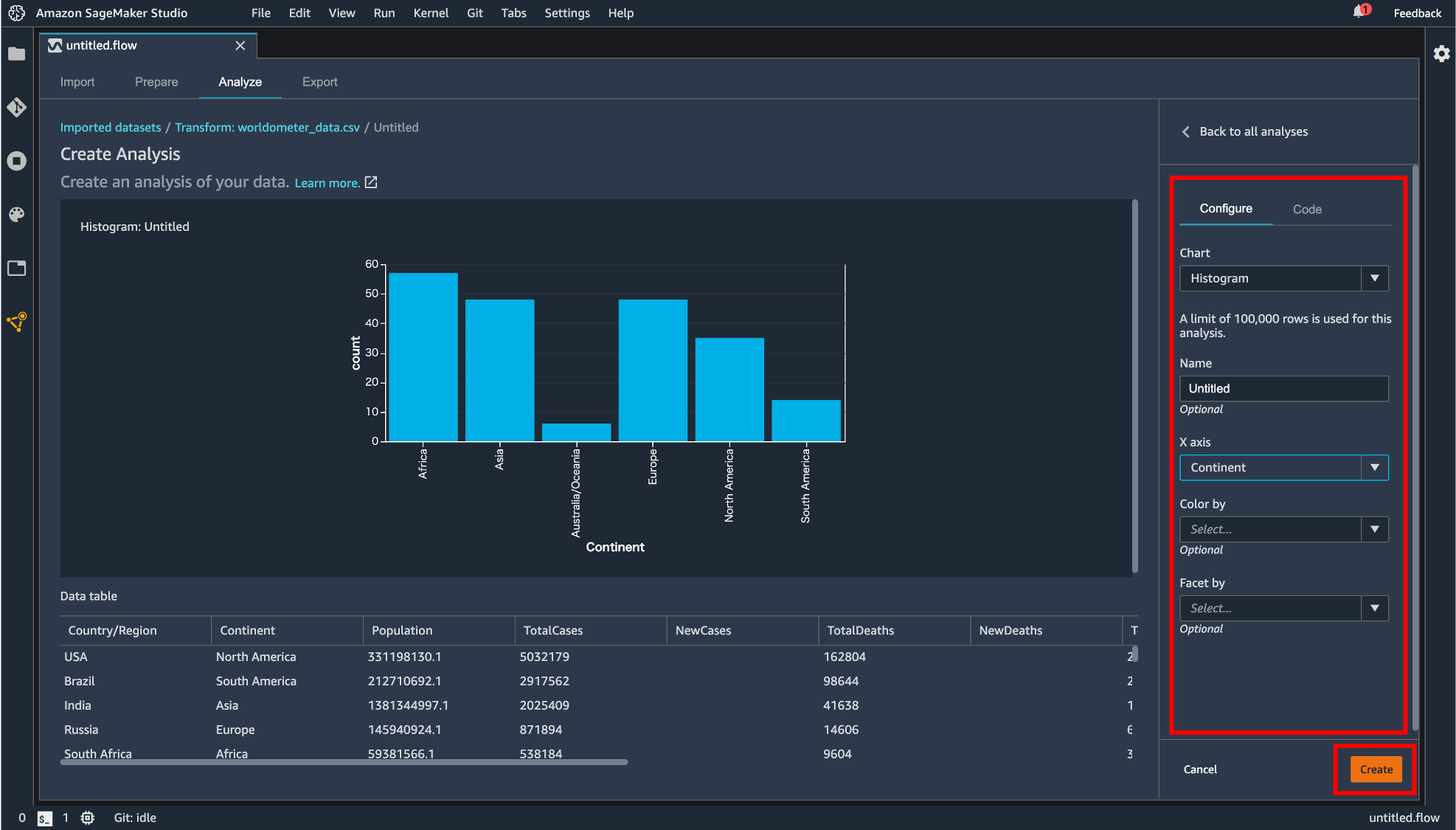
保存された図は flow ファイルの「Analyze」タブに保存されています。この画面からも「Create new analysis」から新しい図を描画できます。
join
2つのデータセットの結合が行えます。データセットが複数必要になるには「Import」タブから最初にデータをインポートした時と同じ手順で実施します。
「Join」をクリックしたデータフレームが左側として指定されます。
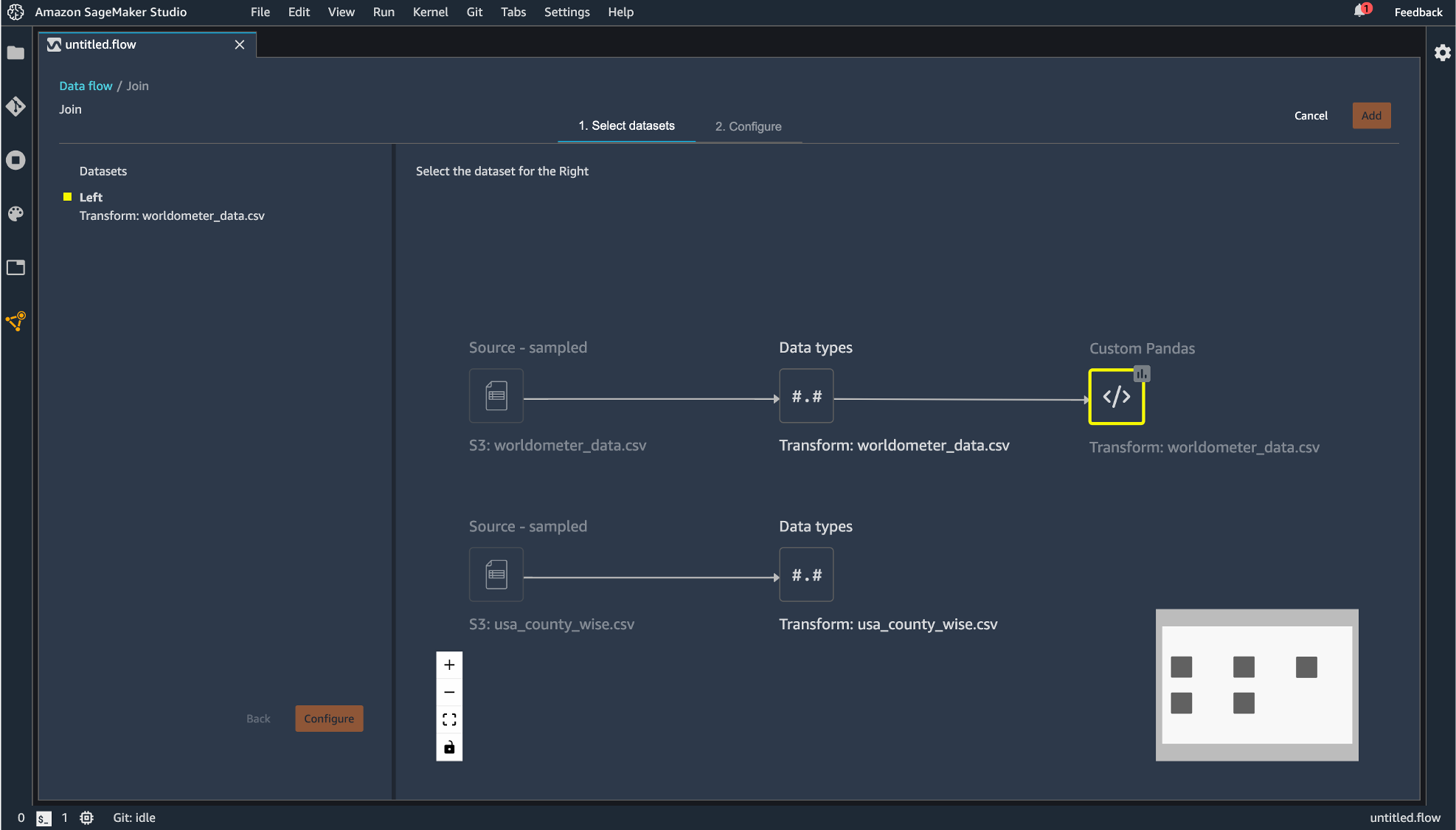
右側にのデータフレームを指定すると結合後のフローが現れるので「Configure」すると、
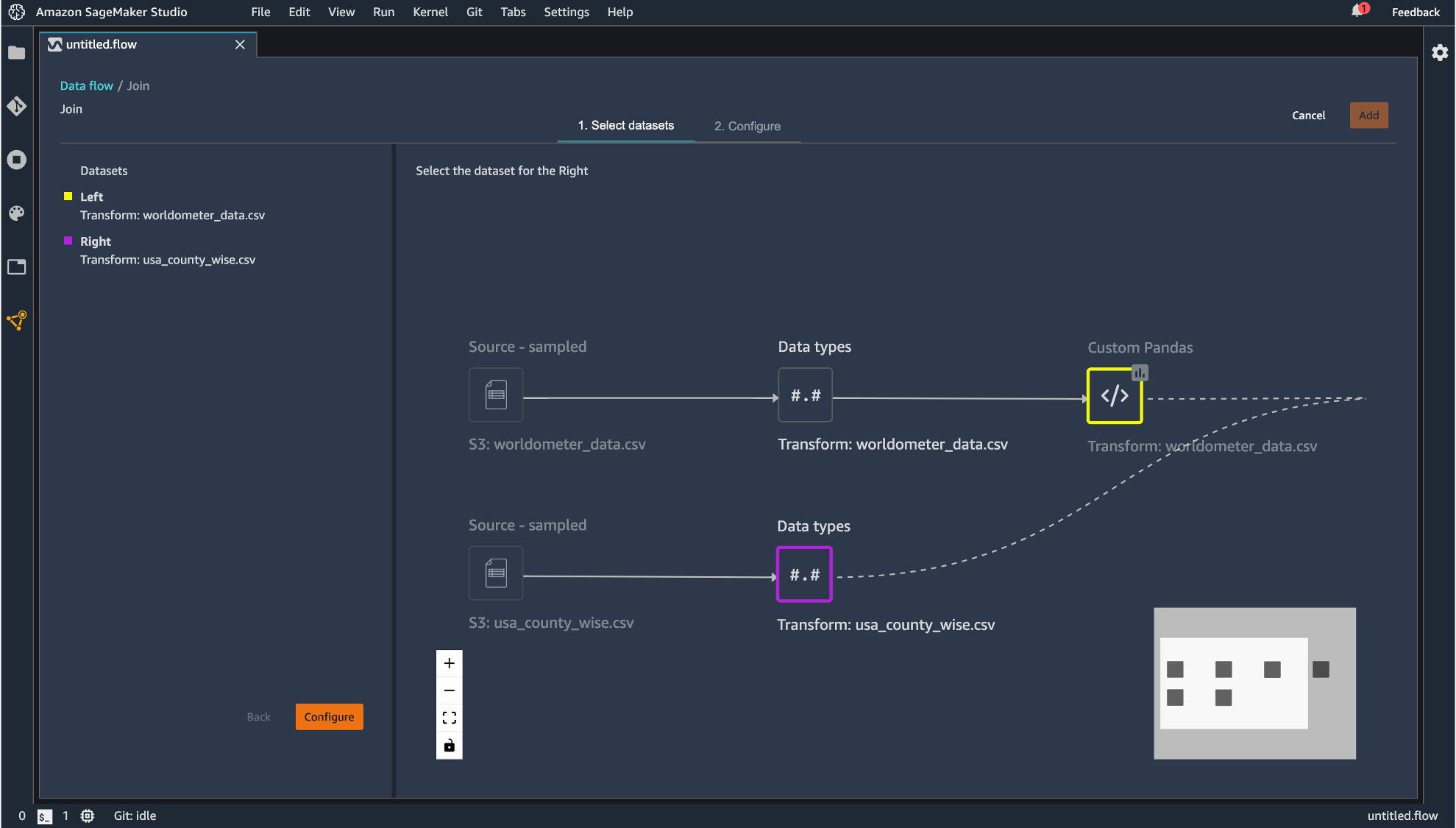
プレビュー画面が表示され、どのように結合を行うのかを指定します。設定したら「Apply」して「Add」します。
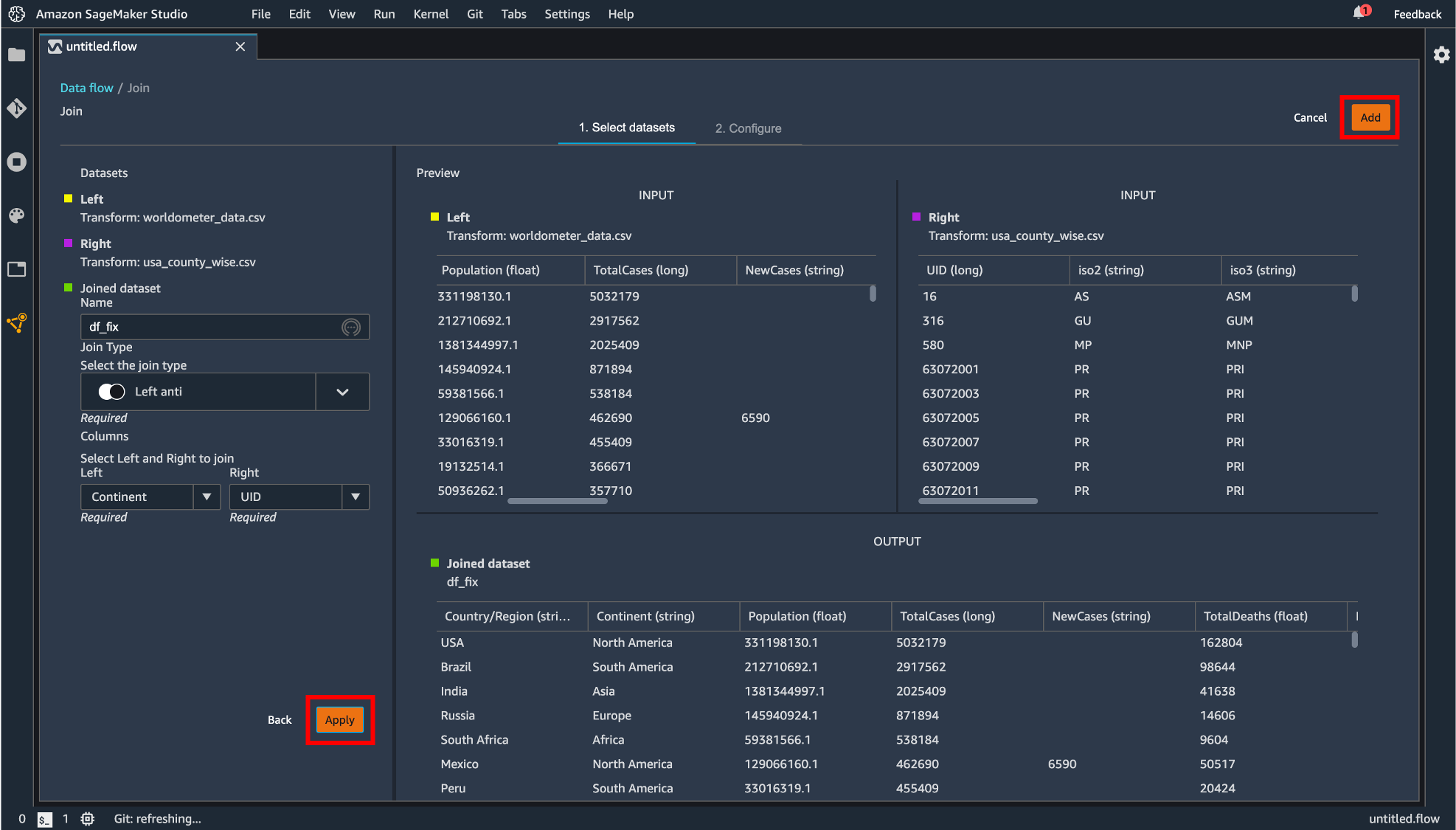
生成したデータフレームがコンポーネントとして追加されました。

concatenate
データの連結を行えます。手順としては Join の操作に準じています。
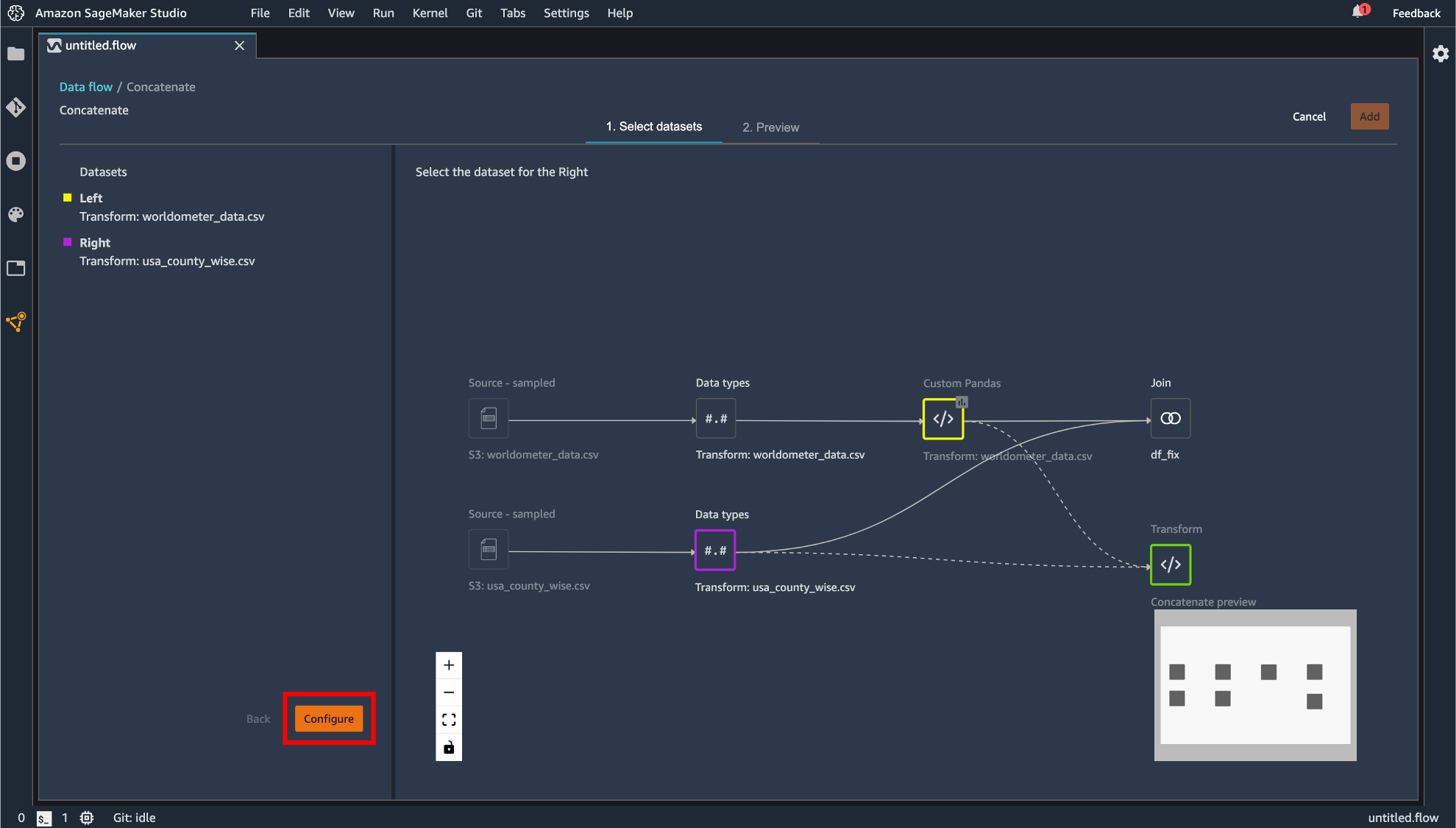
指定したら「Apply」して「Add」します。
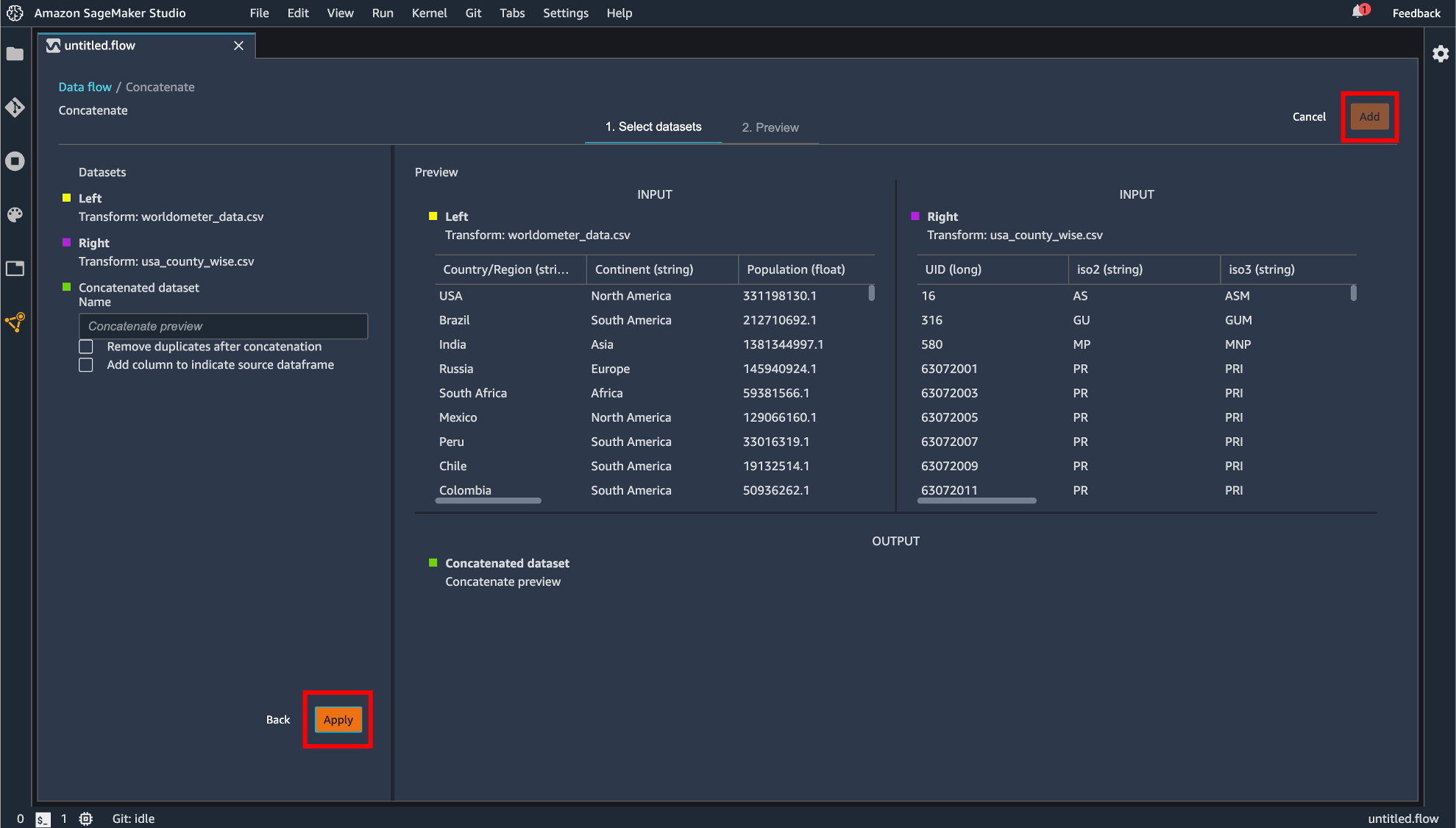
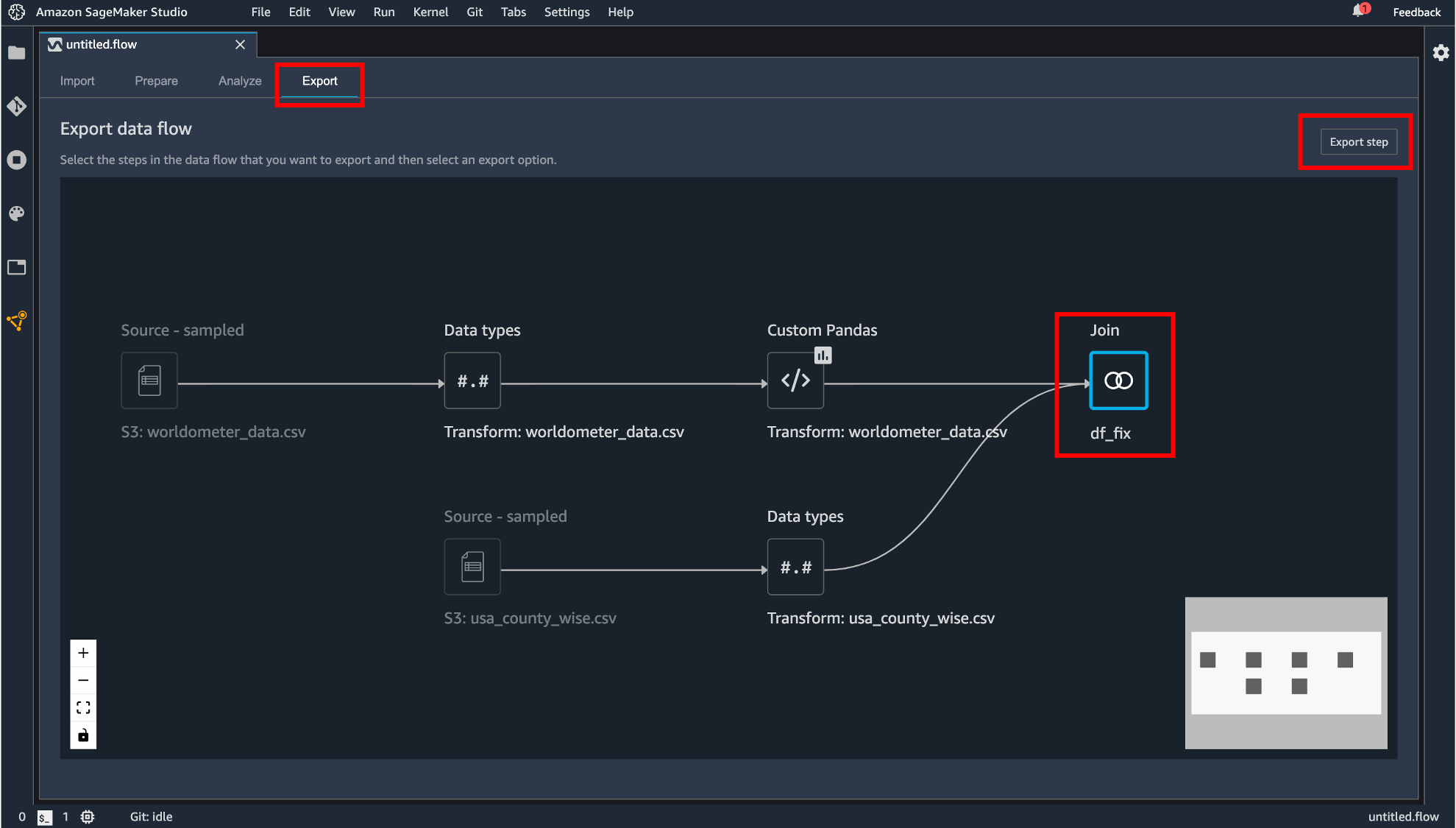
データフローのエクスポート
作成したデータフローをエクスポートします。まず「Export」タブに移動します。エクスポートしたいコンポーネントをクリックして「Export step」をクリックします。
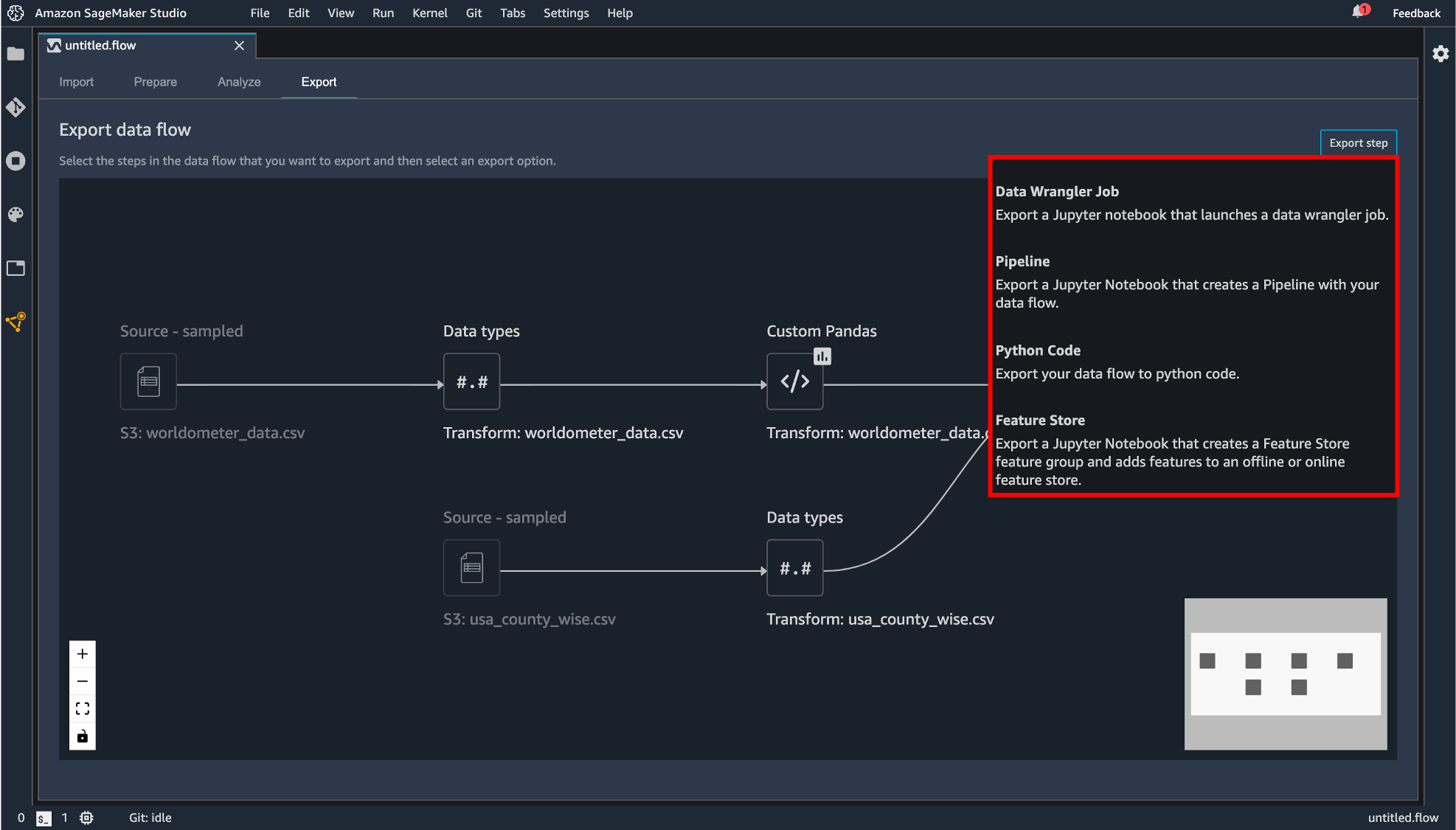
エクスポートの方法は現在4種類用意されています。
- Data Wrangler Job
- Pipeline
- Python Code
- Feature Store
Python Code では.py の拡張子を持つファイルとして生成されます。他の3つは SageMaker に統合されたノーブック形式でエクスポートします。
違いとしては、
- Data Wrangler Job
作成したデータフローを丸ごとコード化
- Pipeline
作成したデータフローのコード + Pipeline という機能への統合するためのコードが追記
- Feature Store
作成したデータフローのコード + Feature Store という機能へ統合するためのコードが追記されます。とりあえず Data Wrangler Job としてエクスポートしてみます。
無事エクスポートできました!
おわりに
データの様々な前処理が GUI 上でできるのは本当に便利だと思います。今後はこの機能を使い倒していきたいと思います。他にも機械学習が便利になるサービスがあったら紹介していきたいと思います!
