はじめに
エンジニア歴1年目の私が、機械学習について調べたことをまとめていきたいと思います。
今回は、私が分からないなりにも「これだけは覚えておきたい!!」と感じた、データ分析の超入門用語を7つピックアップしました。
ゴール
今回は以下の解説用語をざっくり解説していきます。
解説用語
- 特徴量
- 説明変数と目的変数
- データ探索
- 可視化
- 特徴量エンジニアリング
- 学習と推論
1. 特徴量
特徴量とは、対象となるデータの特徴を数値化したもの
犬を例に説明していきます。
私たち人間は犬を見ると、大きさや顔の特徴、毛並み等から「チワワ」とか「日本の犬」等を判別することができます。
ですが、コンピュータの世界ではそうはいかず、大きさや顔の特徴などを明確に数値化して始めて「犬種」を判断することが可能になります。
これらの大きさや顔の特徴などを数値化したものが「特徴量」に当たります。
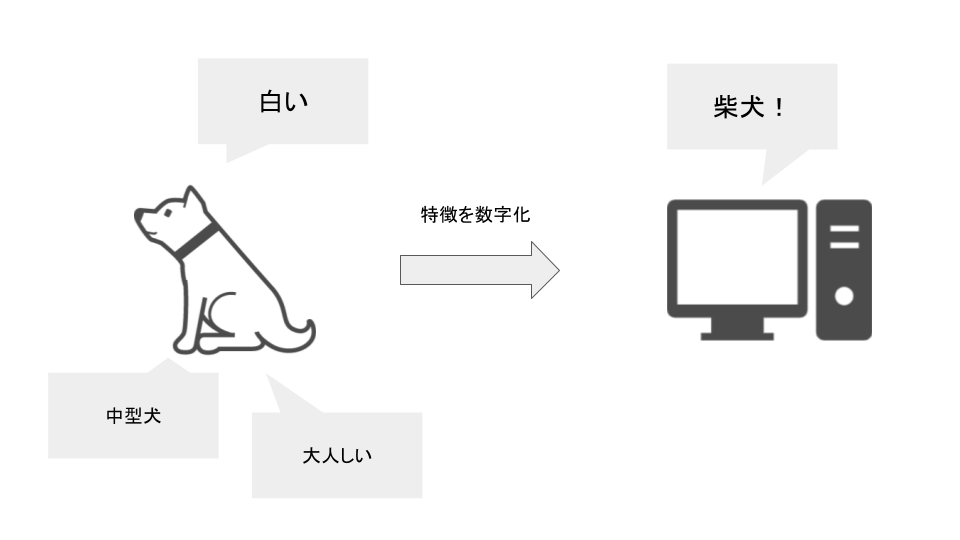
特徴量の選択は、機械学習を行うさいには最も大事なデータの質や量が求められます。つまり、良質な機械学習を行いたい場合は良質なデータの質と量が大きく影響してくると言っても過言ではありません。
ちなみに、特徴量のデータの数のことを「次元」と言います。私たちが、犬の種類を判別するときに複数の情報から判断するように、機械学習でも複数のデータをコンピュータに学習させ判断させます。
大きさや毛並みの色を特徴量にする場合は2次元、そこに顔の特徴などを加える場合は3次元といった感じですね。
2. 説明変数と目的変数
説明変数とは、予測のポイントとなるデータのこと。特徴量に当たる。
目的変数とは、予測対象の過去のデータのこと
セールスを例に説明していきます。
Aという会社でペンを販売しているとします。
セールスでは売上を管理する際に、「今期はお客様にどれだけ売れるか?」の予測がつくと便利ですよね。
この予測を行うためには、コンピューターに「過去どれくらい売上が立っているか」を学習させる必要がありますので、「過去の売り上げ」が目的変数になります。
そして、この予測の根拠となるデータ(セールスマンの人数、景気、アポイントの数、等)を学習させることによって予測の精度を上げることができます。この「根拠のデータ」にあたるのが、説明変数(特徴量)になります。

3.データ探索(EDA)
データ探索(EDA)とは、分析初期のフェーズで「データを理解するため」に行う作業のこと
データ探索を行う目的としては、まずはデータに触れてみて、データを可視化したり、データのパターンを探したりすることで、「データを見てからモデルを修正する」必要性があるからです。
少しわかりずらいですね。
図で説明しましょう。
Aさんが売上予測モデルを作ってほしいと依頼されました。
しかし、Aさんは売上のデータは扱ったことがありません。
そこで、まずは営業部から売上のデータを集めて、簡単にグラフを作ってみることにしました!
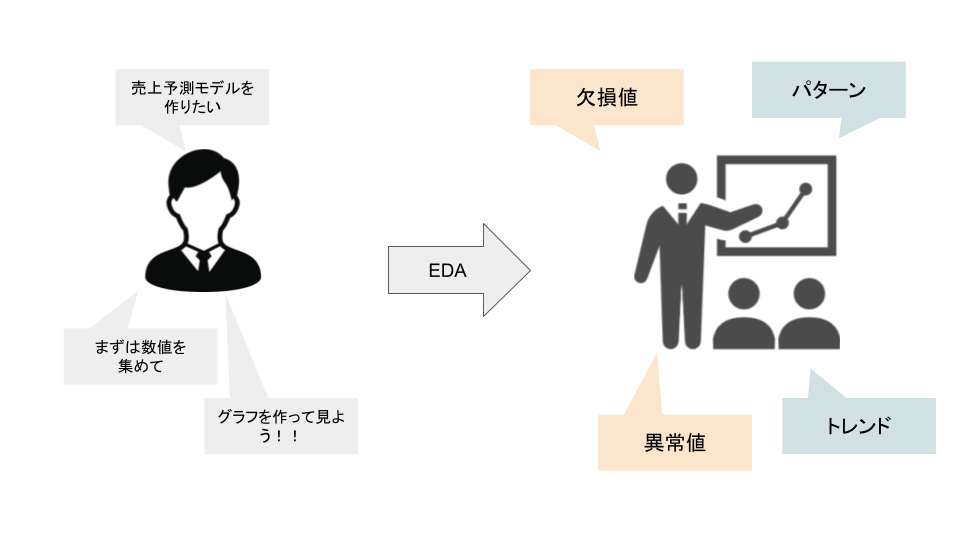
するとどうでしょう。構想段階では分からなかった「異常値や欠損値」が発見され、またデータの「トレンド・パターン」を発見することが出来ました。
この実際のデータを集めて、図や表に表してみるという行動が「探索的データ解析」に当たります。
探索的データ解析の成果によってその後の作業効率が変わるため、非常に重要な作業になります。
4.可視化
可視化とは、データを見える形で整理すること
身近な例だと、エクセルで管理している売上データや在庫の数などを表や図に変換することなどが挙げられますね。
例えば、売り上げの数字がエクセルに羅列されているとします。
ぱっと見たときに、数字が大量に並んでいるだけでは「何がどう変わっているか」って分かりづらいと思います。特に大事な意思決定の場では、数字だけ並べられても判断までに時間がかかってしまいます。さらに、そこにデータ量が1000行とかあったらどうでしょう、、、。ぞっとしますよね。
そんなときに必要になるのが可視化です。
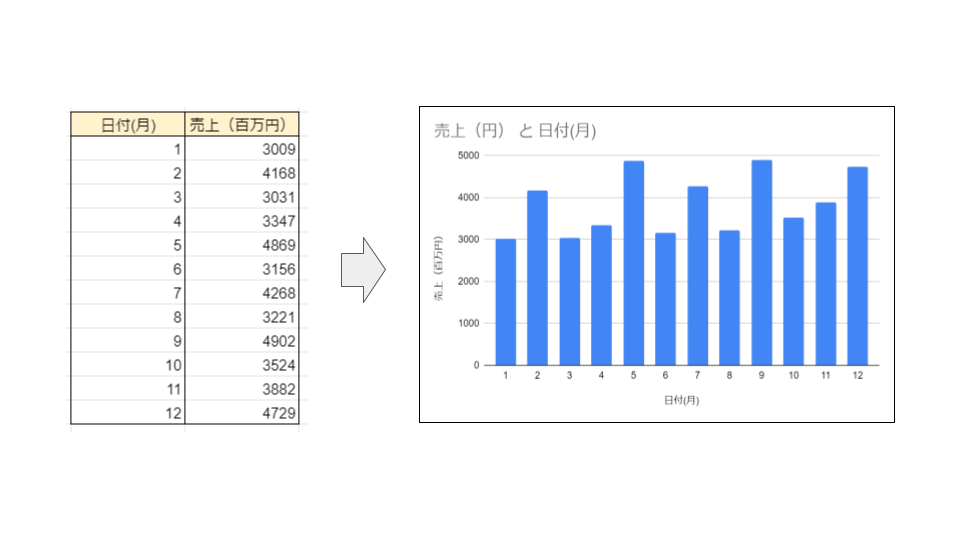
可視化は以下のようなメリットがあります。
・属人的なスキルへの依存解消
・クイックな意思決定
5.特徴量エンジニアリング
特徴量エンジニアリングとは、人為的にAIの予測精度を上げるために用いる技術のこと
データ分析ではあるあるにはなりますが、せっかくデータ分析のモデルを作成したのに、予測精度がいまいちだと利用価値がなくなってしまうことが多々あります。
上記の要因の一つとして、集めた生のデータには不良値や欠損値などが含まれている場合や、そのまま扱えない文字データ・画像データがある場合があり、より利用価値の高いモデルを作るために、人がデータを加工する必要があります。
そのデータを表形式にまとめてパターン認識できるように変換する技術を特徴量エンジニアリングと呼んでいます。
【代表的な特徴量エンジニアリング】
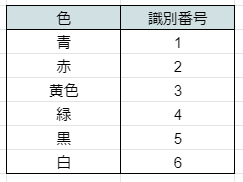
Label encoding
例えば、好きな色…青なら3、白なら1 といった感じで、好きな色を言語ではなく数値に変換する技術です。
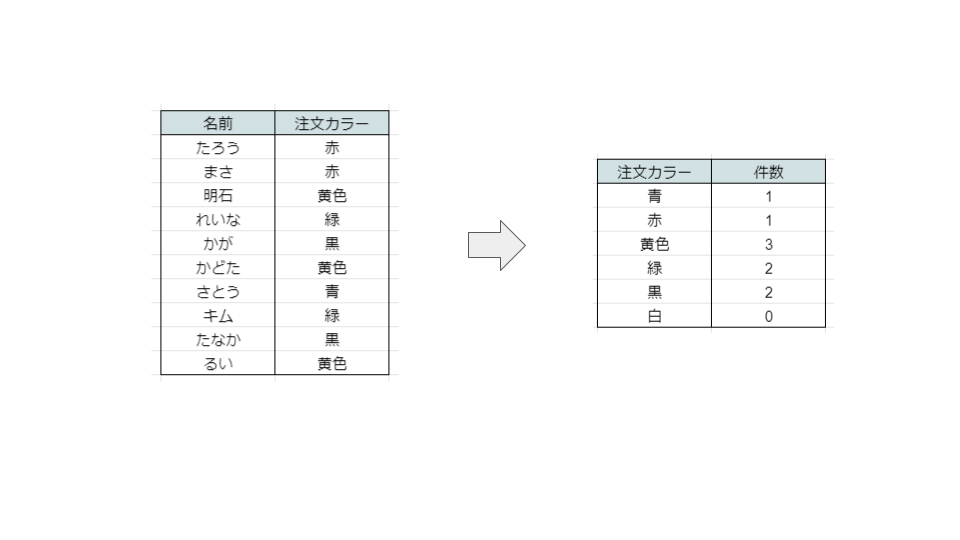
Count Encoding
例えば、好きな色を集計したデータが1000件あるとして、その中から
好きな色…青は300件、白は200件…と、そのまま集計した好きな色のデータ件数を数値に変換する技術です。
まだまだ他にもデータ分析のモデルの予測精度を上げるための特徴量エンジニアリングはたくさんありますが、
長くなるので割愛します。
6.学習と推論
そもそも、機械学習とは、大量の学習データをコンピュータに読み込ませ、そのデータを分析することで分類や識別のルールを作ろうというプログラムのことを指しています。
機械学習をするためのプロセスは、学習 と 推論 の2つに分けられます。
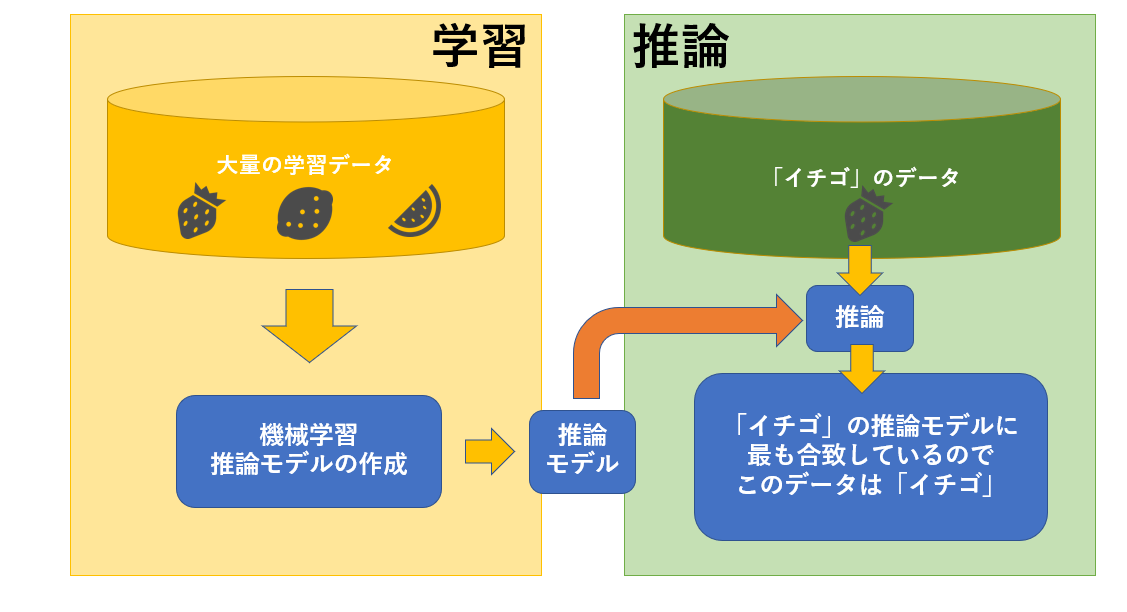
学習とは、大量の学習データの統計的分布から、特徴の組み合せパターンを作り出すプロセス
例えば、学習データである「イチゴ」「レモン」「スイカ」の画像から、コンピュータがそれぞれの画像から見つけた典型的な特徴の組み合わせパターン(=推論モデル)を作ります。
推論とは、分類や識別をしたいデータを、学習で生成しておいた推論モデルに当てはめて、その結果を導くプロセスで
例えば、未知の画像から、画像の特徴を抽出し、「イチゴ」「レモン」「スイカ」を識別する推論モデルに抽出した特徴を照合します。
そして、イチゴの特徴の組み合わせパターンから作られた推論モデルが最も抽出した特徴に近いと判断すれば、「イチゴ」という推論をコンピュータが出力してくれます。
さいごに
簡単ではありますが、データ分析に関する基礎用語について解説しました。
一つ一つをじっくり説明すると長くなってしまいますので、色々割愛させていただきましたが、調べていく中でデータ分析の奥深さと難しさを改めて感じました。
ぜひ、参考になれば幸いです。
