こんにちは!中の人です。
前回に引き続き、今回もAmazon Redshift編です!
前回のレシピでは、「Amazon Redshift編~MySQLのデータをインポートしてみよう!~」と題して、MySQLからのデータのインポート方法についてお話したかと思います。
今回は複数のファイルを一括インポートする方法について説明します。
サンプルは前回と同様に郵便番号のデータを利用します。
少し準備に時間がかかりますが、10個のファイルの一括インポートをおこなってみましょう!
事前準備
1. http://www.post.japanpost.jp/zipcode/dl/oogaki.html
上記URLより「01hokkai.lzh」~「10hokkai.lzh」をダウンロードし、解凍します。
2. 回答したファイルをテキストエディタで開き、UTF-8Nのフォーマットで保存します。
※日本語を扱う場合は必ずUTF-8Nで保存する必要があります。
3. 以下のコマンドをTSV形式で出力します。
|
1 2 |
「mysql –u [ユーザ名] -p -N –e "SELECT * FROM postcode" [データベース名] > /tmp/mysql.tsv」 ※Nオプションで項目名が表示されなくなります。 |
4. 出力したデータをRedshiftと同じリージョンのS3に対してアップロードします。
テーブルの作成
5. ここからはRedshiftに対する操作です。
SQL Workbenchを起動させ、Redshiftに対して接続します。
※前回と同様、SQL Workbenchのインストールと接続については以下の「Redshiftをはじめてみよう!」のレシピを参照してください。
■ Amazon Redshift編~Redshiftをはじめてみよう!~パート①~
■ Amazon Redshift編~Redshiftをはじめてみよう!~パート③~
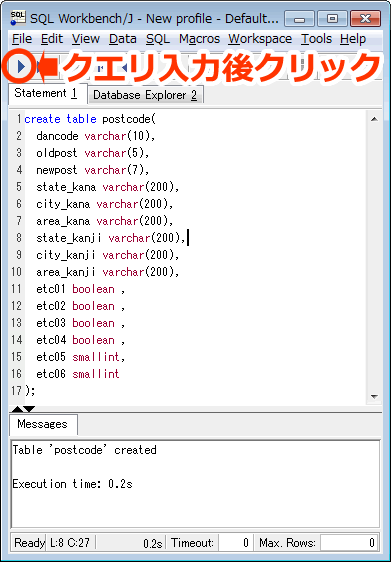
郵便番号情報用にテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
create table postcode( dancode varchar(10), oldpost varchar(5), newpost varchar(7), state_kana varchar(200), city_kana varchar(200), area_kana varchar(200), state_kanji varchar(200), city_kanji varchar(200), area_kanji varchar(200), etc01 boolean , etc02 boolean , etc03 boolean , etc04 boolean , etc05 smallint, etc06 smallint ); |
データのインポート
|
1 |
copy postcode from 's3://[s3-backet名]/ ' CREDENTIALS 'aws_access_key_id=[your access key];aws_secret_access_key=[your secret access key]' delimiter '\t'; |
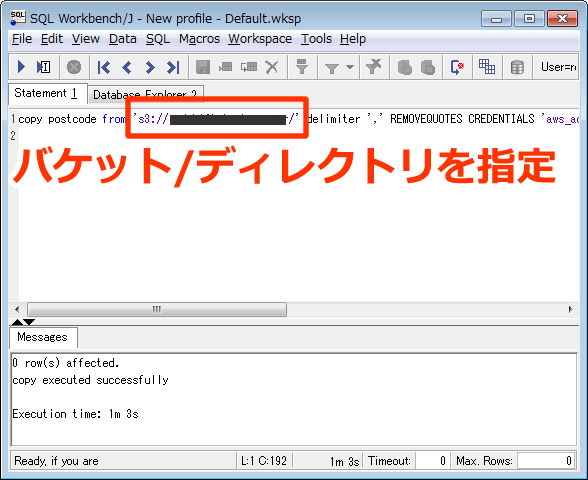
○ 前回との変更点
| copy [インポート先のtable] from ‘[インポートするバケット名 または ディレクトリ名]’ | インポートするバケット名/ディレクトリ名とデータ保存先のテーブルを指定します。 |
参照先をファイルからディレクトリに変更することで、ディレクトリにあるファイル一覧を読み取りインポートされます。
注意点としては、すべてのファイルがインポートできるフォーマットであるということです。
データの確認
6. データの確認として以下を実行してみます。
select * from postcode where state_kanji = ‘栃木県’
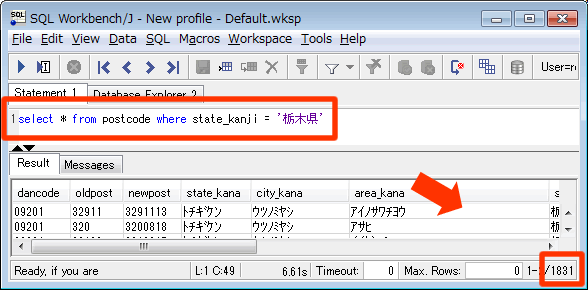
栃木県の登録データ 1831件がヒットしたことが確認できます。
いかがでしたでしょうか?
このようにバケット名・ディレクトリを指定することで、配下にあるファイルを一括して読み込むことができます。
例えば、複数あるアクセスログを一括してRedshiftにインポートするときなどに活用できます。
次回は「Amazon Redshift編~圧縮ファイルをインポートしてみよう!~」というタイトルで全国の郵便番号データを圧縮してインポートする方法を紹介します。
お楽しみに!
