はじめに
現在、AWS re:Invent 2022 が開催されており、様々なサービスの情報が公開されております。
今回は、Amazon RedShift integration for Apache Spark の情報が公開されたので、記事の内容をまとめてみました。
本編の詳細については、下記リンクを参照ください。
■リンク
・New – Amazon Redshift Integration with Apache Spark
Amazon Redshift Integration with Apache Spark について
Apache Spark とは
Apache Spark はビッグデータのワークロードに利用される、オープンソースの分散処理システムです。
Amazon EMR、Amazon SageMaker、AWS Glue を利用する Spark アプリケーションのデベロッパーの方々は、 Redshift でデータの読み取り・書き込みができる Apache Spark コネクタというサードパーティをよく使われていると思いますが、サードパーティコネクタは、定期的なメンテナンスやサポート、そして、様々なバージョンのSpark での本番運用のテストなどはあまりしてないでしょう。
この度 AWS では Amazon Redshift integration for Apache Spark を提供する運びとなりました。
Amazon Redshift Integration with Apache Spark の特徴
Amazon Redshift Integration with Apache Spark の特徴は以下です。
- 特徴
- Amazon RedshiftおよびRedshift Serverless上でSparkアプリの構築と実行が可能
- Java、Scala、Python などの言語を利用することが可能
- アプリのパフォーマンスやデータのトランザクションの一貫性を損なわずに、Amazon Redshiftデータウェアハウスからの読み込みと書き込みが可能
Amazon Redshift Integration with Apache Spark の利用開始について
利用開始可能日
Amazon Redshift integration for Apache Spark は本日より利用が可能です。
下記の AWS サービスをサポートする全てのリージョンで利用できます。また、EMR 6.9とGlue Studio 4.0 をSpark の 新バージョン3.3.0 で使用できます。
- Amazon EMR 6.9
- AWS Glue 4.0,
- Amazon Redshift
Amazon Redshift の Spark Connector の場合
AWS Analytics と MLサービスに行き、Spark ジョブか Notebook でデータフレーム、または Spark SQL コードを使用して Amazon Redshift データウェアハウスに接続してクエリを実行することで開始できます。
Amazon EMR 6.9、EMR Serverless、AWS Glue 4.0には、あらかじめコネクタと JDBC ドライバがパッケージとしてあるので、コードを書き始めるだけでOKです。EMR 6.9、EMR Serverless それぞれでサンプルノートブック、サンプル Spark Job が提供されています。
開始にあたり、RedshiftとSpark間、Amazon Simple Storage Service (以下、Amazon S3)とSpark間、RedshiftとAmazon S3 間でAWS Identity and Access Management (AWS IAM) 認証の設定をする必要があります。Amazon S3、Redshift、Sparkドライバ、Spark エグゼキュータ間の認証については下記の図を参照下さい。
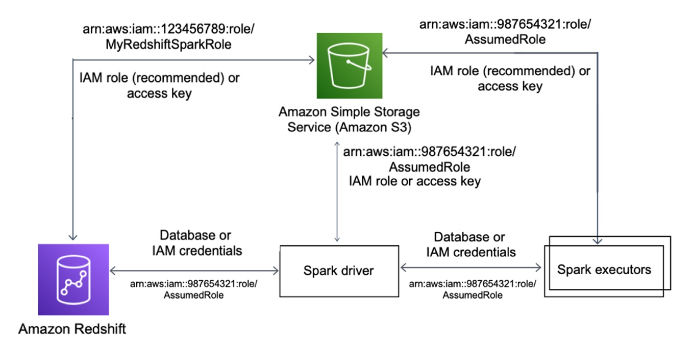
Amazon EMR の場合
Amazon Redshift のデータウェアハウスが既に存在し、データが利用可能なら、データベースユーザを作成して適切な権限を割り振ることが可能です。Amazon EMR で使用するには、パッケージ化された spark-redshift コネクタを持つ最新バージョンの Amazon EMR 6.9 にアップグレードする必要があります。Amazon EC2 上に EMR クラスタを作成する際に「emr-6.9.0 」をリリース箇所にて選択します。
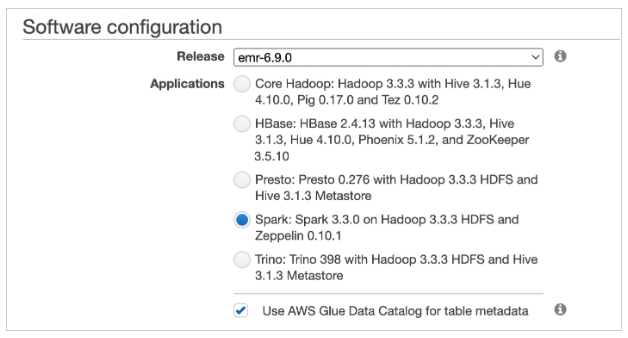
emr-6.9.0 リリースを使用してワークロードを実行するために、EMR Serverless を使用して Spark アプリケーションを作成することができます。
EMR Studio では、Amazon Redshift Serverless エンドポイントに接続するように構成された Jupyter Notebook のサンプルが用意されているので、すぐに開始することができます。
下記は、Spark Dataframe と Spark SQL の両方を使用してアプリケーションを構築するための Scala の例です。Redshift への接続には IAM ベースの資格情報を使用し、S3からのデータのアンローディングとローディングにはIAM ロールを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
scala // Create the JDBC connection URL and define the Redshift context val jdbcURL = "jdbc:redshift:iam://<RedshiftEndpoint>:<Port>/<Database>?DbUser=<RsUser>" val rsOptions = Map ( "url" -> jdbcURL, "tempdir" -> tempS3Dir, "aws_iam_role" -> roleARN, ) // Reference the sales table from Redshift val sales_df = spark .read .format("io.github.spark_redshift_community.spark.redshift") .options(rsOptions) .option("dbtable", "sales") .load() sales_df.createOrReplaceTempView("sales") // Reference the date table from Redshift using Data Frame sales_df.join(date_df, sales_df("dateid") === date_df("dateid")) .where(col("caldate") === "2008-01-05") .groupBy().sum("qtysold") .select(col("sum(qtysold)")) .show() |
Amazon Redshift と Amazon EMR が異なる VPC にある場合、VPC ピアリングを設定するか、クロス VPC アクセスを有効にする必要があります。
AWS Glue の場合
AWS Glue 4.0を使用する場合、spark-redshift コネクタはソースとターゲットの両方として利用することが可能です。Glue Studio では、組み込みの Redshift ソース、またはターゲットノード内で使用する Redshift 接続を選択するだけで、ビジュアル ETL ジョブを使用して Redshift データウェアハウスへの読み取りや書き込みが可能です。
Redshift 接続には、適切な権限で Redshift にアクセスするために必要な認証情報とともに、Redshift 接続の詳細が含まれています。
開始するには、Glue Studio コンソールの左メニューから「Jobs」を選択します。ビジュアルモードのいずれかを使用することで、ソースやターゲットノードを簡単に追加・編集し、コードを書かずにデータに対する様々な変換を定義することができます。
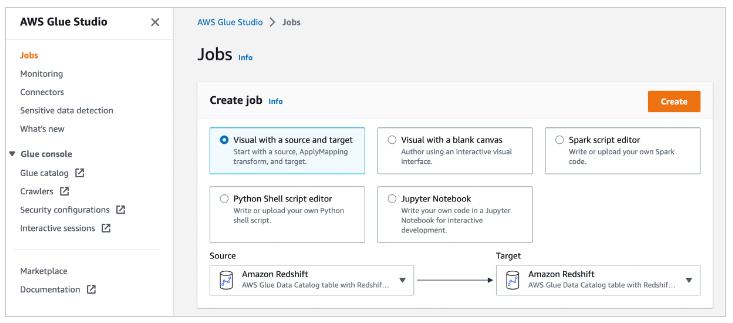
「Create」を選択すると、ジョブダイアグラムにソース、ターゲットノード、トランスフォームノードを簡単に追加、編集することができます。この時、「Source」と「Targe」として Amazon Redshift を選択します。
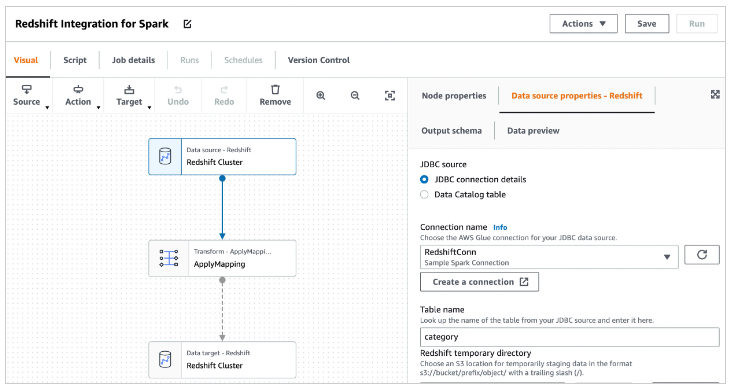
完成した Glue ジョブは、Apache Spark エンジンの Glue 上で実行することができ、自動的に最新の spark-redshift コネクタを使用することができます。
以下の Python スクリプトは、spark-redshift コネクタを使用して、dynamicframe で Redshift への読み書きを行うジョブの例です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
Python ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) print("================ DynamicFrame Read ===============") url = "jdbc:redshift://<RedshiftEndpoint>:<Port>/dev" read_options = { "url": url, "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "tempdir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "autopushdown": "true", "include_column_list": "false" } redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=read_options ) print("================ DynamicFrame Write ===============") write_options = { "url": url, "dbtable": dbtable, "user": user, "password": password, "redshiftTmpDir": redshiftTmpDir, "tempdir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "autopushdown": "true", "DbUser": user } print("================ dyf write result: check redshift table ===============") redshift_write = glueContext.write_dynamic_frame.from_options( frame=redshift_read, connection_type="redshift", connection_options=write_options ) |
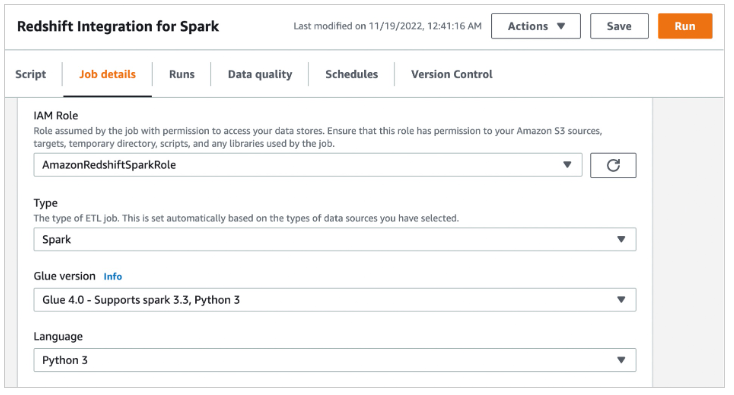
ジョブの詳細を設定する際、この統合には Glue 4.0 – Supports spark 3.3 Python 3 バージョンを使用する必要があります。
おわり
Amazon RedShift integration for Apache Spark についてのまとめは以上となります。
より詳しい情報などについては、本記事をご参照ください。
他にも様々なサービスに関する新情報が AWS re:Invent 2022 では公開されているので、そちらもぜひチェックしてみてください。
