はじめに
2022/6/27(月)~2022/6/30(木)に開催されたData & AI Summit 2022に関する最新情報をお知らせします。
本記事では、McAfeeがDatabricks on AWSを大規模に活用する方法を翻訳してまとめました。
アジェンダ
Databricks on AWSとはなにか?McAfeeがDatabricks on AWSをどのように運用したか、そのために何をしたか、移行と運用の両方についての話です。
・Databricks on AWSの簡単な概要
・McAfeeにおけるDatabricks on AWSの運用
・ビジネス変革、ユースケースとロードマップ
Databricks on AWSの簡単な概要
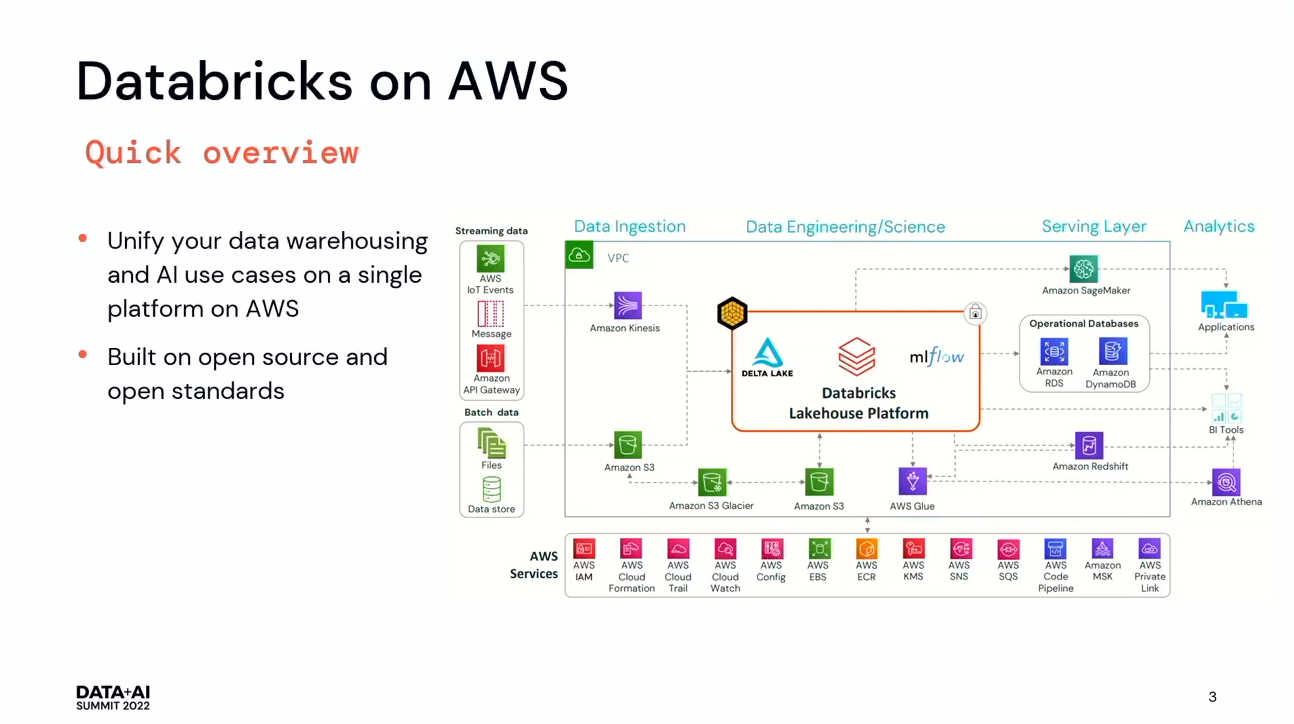
Databricks on AWSは、オープンレイクハウスアーキテクチャで構築されたオープンプラットフォームです。AWSで最適化されており、データウェアハウス、分析、AIなどのユースケースで使用できます。特にKinesisやRedshift、MLFlowを通じてSageMakerなどネイティブに統合されています。
McAfeeにおけるDatabricks on AWSの運用

McAfeeといえば、ウイルス対策・VPN・セキュリティソフトの会社ですが、1台のデバイスでお客様を保護することから、より顧客中心にすべてのやり取りでお客様を保護するよう変化してきました。そして、データを使ってビジネスを推進し、ユースケースをサポートするためのエコシステムを構築する必要がありました。
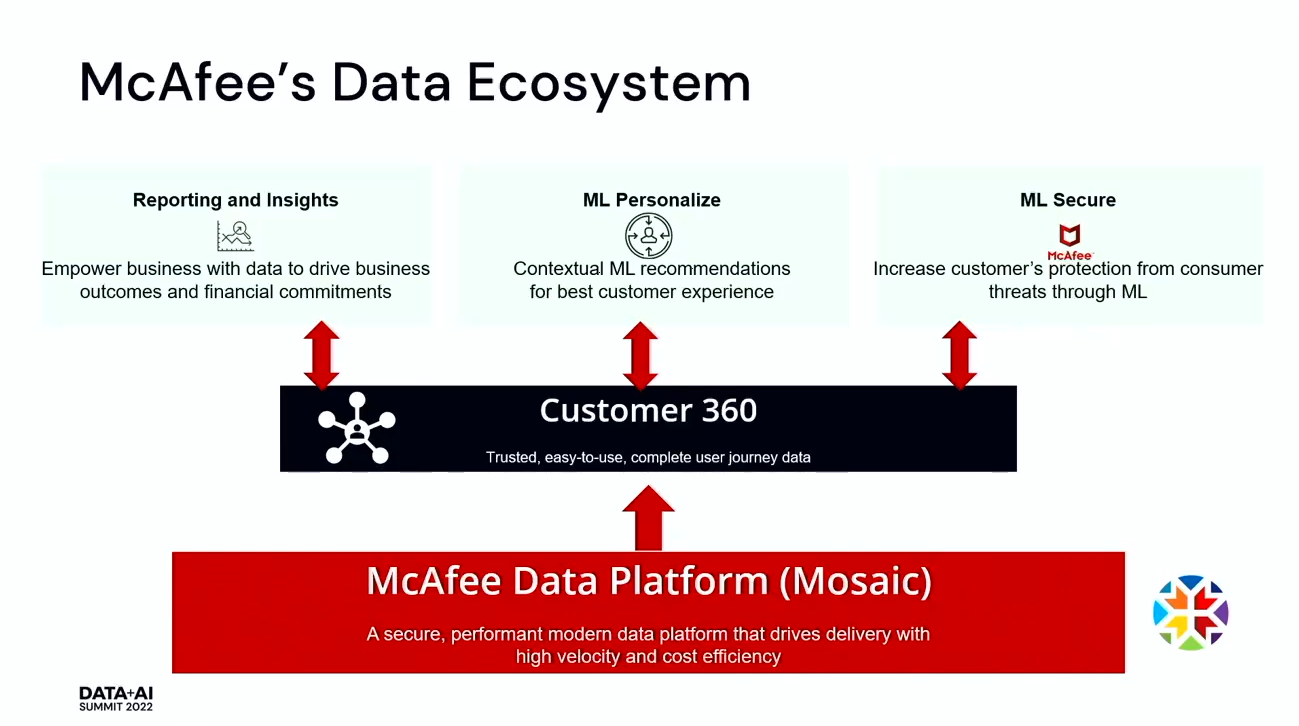
Reporting and Insights
ビジネス上の意思決定を強化するために提供されるレポートです。例えば、ABテストを実施した場合、それを追跡し、どの程度うまくいっているのかを知ることができます。ある機能がうまく動作していないときに社内に警告を出します。
ML Personalize
お客様に最適なサービスを提供するために機能をカスタマイズすることです。例えば、あるお客様がWi-Fiに接続した際に、「VPNを開いて、より安全にご利用ください」と伝えることができます。
ML Secure
MLを使って新しいパターンを検出するものです。自動的にお客様を守ることができるようになります。
Customer 360
顧客とのインタラクションを包括的に表示するものです。これは信頼でき、より使いやすい完全なデータセットでなければなりません。もしデータセットを信頼できなければ、それを使うことは非常に難しく、時には適当に判断した方が良い場合もあります。持っているデータをもとに、素早くアクションを起こせることが必要でした。そして、ユーザーの様々なタッチポイントをすべて理解する必要があります。
McAfee Data Platform
様々なユースケースに対応するために、非常に強力なデータプラットフォームを構築する必要がありました。安全で高性能かつ、大規模なユーザーを抱えているため、拡張性にも優れていないといけません。スケールアップはできても、その分コストがかかってしまうためです。プラットフォーム自体もコスト効率の良いものにしなければなりません。
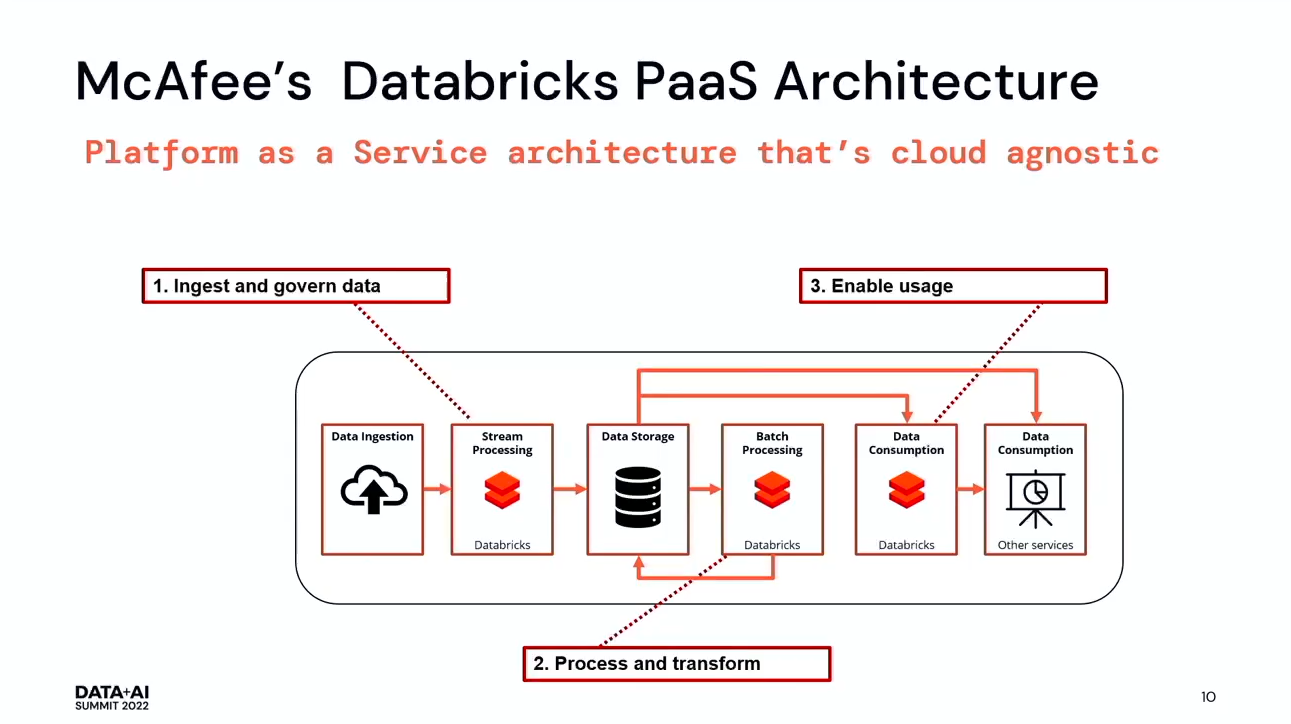
McAfeeは、このプラットフォームを設計しました。エコシステムに取り込まれたデータは、Databricksを使用して永続的なストレージにストリーミングされます。データをストリーミングする際に、いくつかの検証も行っています。その後、再びDatabricksを使ってデータのバッチ処理を行い、最後にすべての機械学習モデルを実行し、レポートやその他すべてのプロセスを実行します。
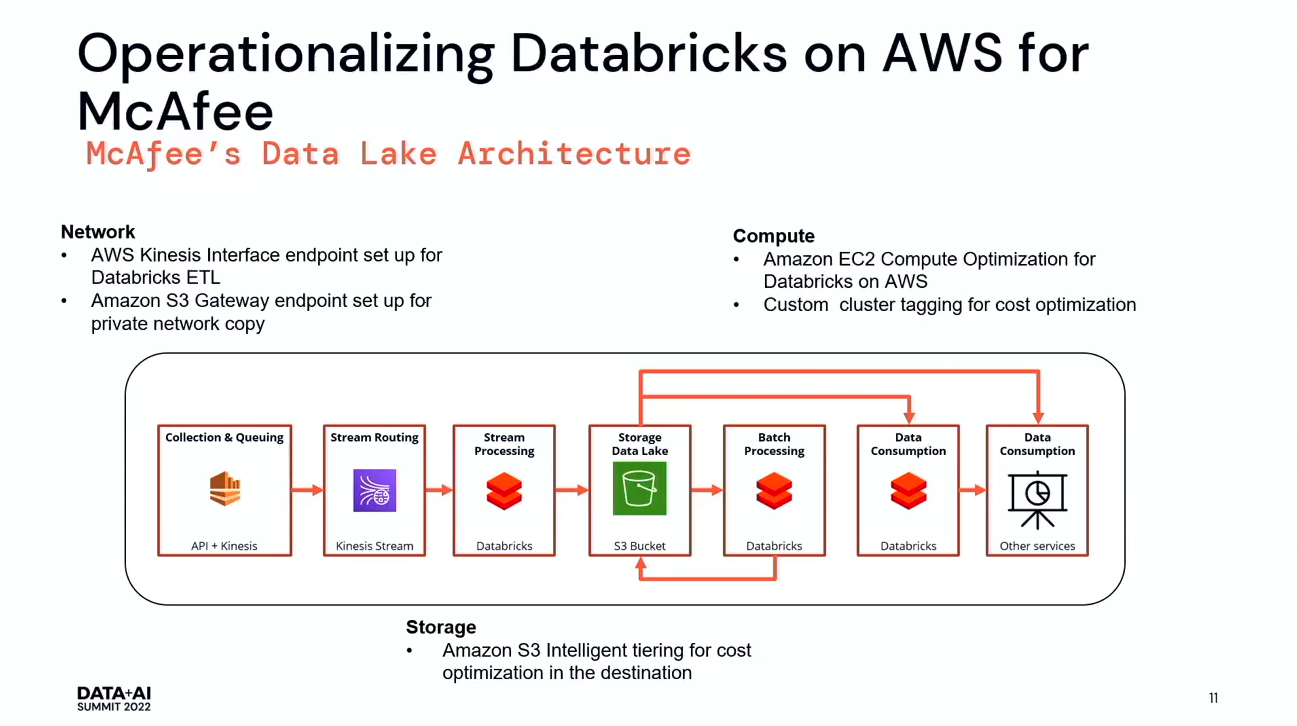
Databricksを使用するメリットは、ETLのためのライブラリを独自に作れることと、ネイティブ・ノートブックが使えることです。
iPhone、タブレットなど、何百万ものエンドポイントから遠隔測定イベントが送られてきており、1日に約20億イベントが、システムとして最適化されています。これらのイベントは、このプラットフォームに取り込まれ、ETL処理を行っています。
Kinesis自体にも制限があり、クォータも制限されています。毎秒2メガビットで毎秒5回のフェッチが可能です。これらのデータを見逃すことなく、すべてのデータを取り込むために、Databricks connector for Kinesis、またStreaming Kinesisを用います。バックグラウンドでSparkジョブを実行し、Sparkジョブがデータをプリフェッチしてキャッシュにプッシュし、Sparkエグゼキューターがキャッシュからデータを取得して処理するというものです。
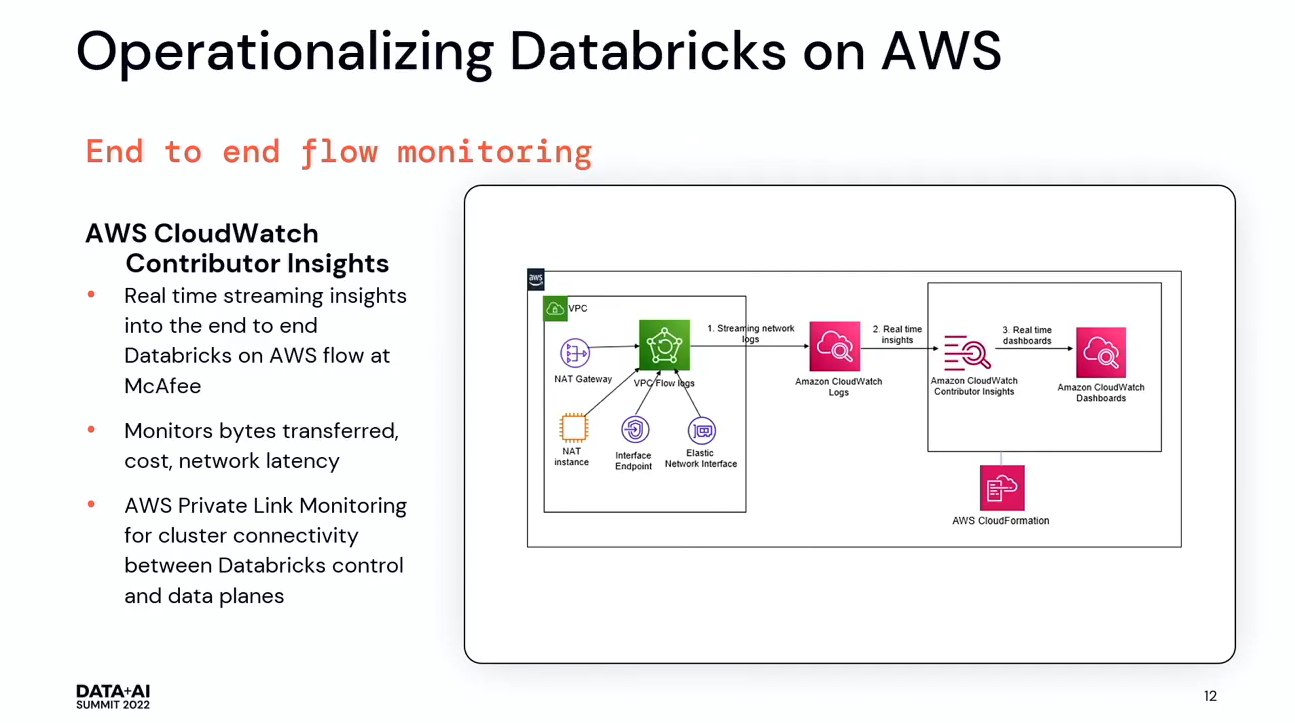
また、CloudWatchでDatabricksを監視することができます。McAfeeでは、Contributor InsightsというCloudWatchサービスを利用しました。Contributed Insightsは、データフローで何が起こっているかを、リアルタイムに把握できるようにするものです。
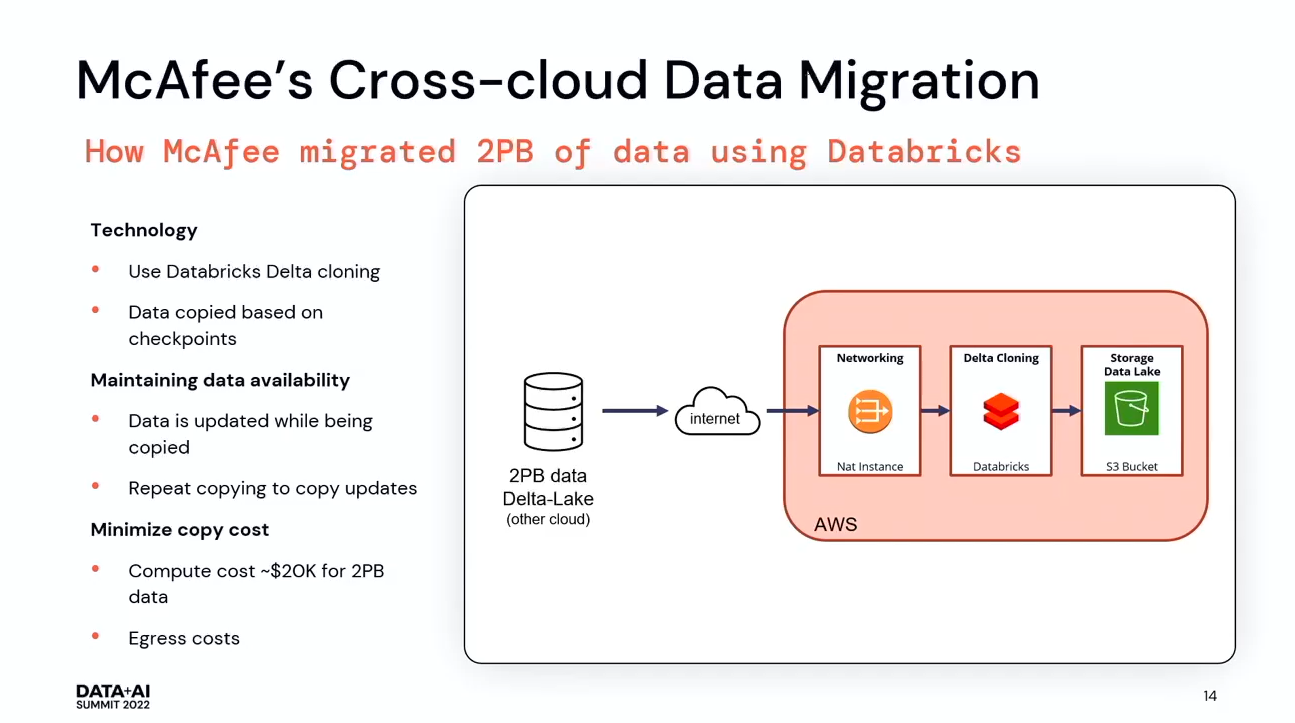
AWSを導入する前は、全てのインフラは別のクラウドにあり、そこで全てのパイプラインを稼働させ、4億台のデバイスからデータを取得し、2ペタバイト以上の履歴データを持っていたのですが、AWSで稼働させることにしました。McAfeeでは、Delta Cloningを使用することにしました。Delta Cloningは、Delta lake checkpointsを利用して、ソースからデータをコピーすることができます。そして、データが更新された後も、何度も繰り返し差分をコピーすることができます。導入前は、すべてのインフラを稼働させた後、データのコピーを繰り返し行いました。コピーに数分かかるテーブルもあれば、数日から数週間かかるテーブルもありましたが、Databricksではコピー作業を再び開始すればいいだけです。データが一致したら、新しい宛先にデータを転送してパイプラインを実行することができるようになりました。検証の結果、99.9%以上のデータの一致が確認できました。さらに、2ペタバイトのデータをコピーするのにかかった費用は2万ドル程度と費用対効果が非常に高いです。
ビジネス変革、ユースケースとロードマップ

現在、700人以上の社員が、Databricksを通じて当社のインフラを積極的に利用しています。毎月約8万件のクエリーを実行しています。BIツールでのクエリ数はカウントしていません。これはデータ駆動型企業への大きな一歩だと考えています。2つ目の成果はスケーリングで、現在約2ペタバイトのデータを行使していますが、そのデータサイズが増加しても心配はないです。
課題としては、カタログはすべてエコシステムの外に置かなければならず、どのデータセットを使うべきかについて、メールでのやり取りが多くなってしまうことや、1万冊を超えるノートブックがありメンテナンスが大変、どのようにクエリされているか、どの列が選択されているか、何行取得されているかなどがわからないことなどが挙げられます。
まとめ
Databricksの統合は、データ組織として大きく成長することができました。もちろん、最初のステップはプラットフォームの立ち上げと運用でしたが、それほど複雑ではありませんでした。そして、すぐにデータを検証し、データを分析して、すぐにレポートを提供できるようになりました。
私たちはこのデータを使って、カスタマーの行動を予測し、以前には見られなかったデータパターンを探そうとしています。よりお客様を守れるような新機能の開発も考えています。主な目標は、お客様を保護し、現場でどんな新しい処理があっても簡単に適応できるようにすることです。そして、それを大規模に行えるようにすることが非常に重要であり、そのためにDatabricksが非常に有効です。
