こんにちは!中の人です。
前回の『Amazon Redshift編~パフォーマンスチューニング sortkey編~』では、Redshiftのパフォーマンスチューニングとしてsortkeyの設定方法と、設定によるパフォーマンスの違いを紹介しました。
今回は『Amazon Redshift編~パフォーマンスチューニング distkey編~』と題して、Redshiftに対してdistribution keyを設定した場合のパフォーマンスについて紹介します。
テスト方法
今回は、こちらのクエリを使用します。
|
1 |
select avg(column01) from SAMPLE_TABLE where column01>5000 and date like '13-06%' |
下記の3つの内容をdistkeyに設定して速度を比較してみます。
・auto incrementされている id
・条件に使われている column01
・条件に使われている date
※distkeyは1つのみ指定可能です。
distkeyの設定方法ですが、以下の様にcreateに続けて記載します。
|
1 2 3 4 5 6 |
create table SAMPLE_TABLE ( id int, ・・・ date timestamp ) distkey(id); |
sortkey/distkeyの両方を指定する場合には、以下の様に連続して記述します。
|
1 2 3 4 5 6 7 |
create table SAMPLE_TABLE ( id int, ・・・ date timestamp ) distkey(id) sortkey(id); |
テスト結果
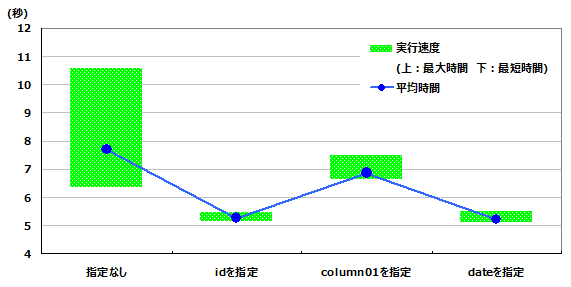
■約4000万行(10回平均)
≪ XLノード ≫
| 指定なし | idを指定 | column01を指定 | dateを指定 | |
|---|---|---|---|---|
| 平均実行速度(秒) | 7.71 | 5.28 | 6.87 | 5.22 |
| 最高実行速度(秒) | 6.37 | 5.13 | 6.65 | 5.12 |
| 最低実行速度(秒) | 10.57 | 5.48 | 7.48 | 5.52 |
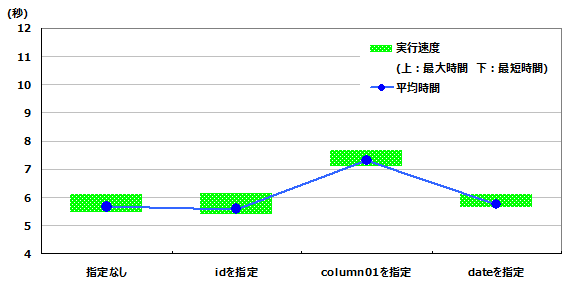
また、前回1番パフォーマンスが良かった「column01とdate」に対してsortkeyを追加した場合の結果です。
| 指定なし | idを指定 | column01を指定 | dateを指定 | |
|---|---|---|---|---|
| 平均実行速度(秒) | 5.66 | 5.59 | 7.31 | 5.76 |
| 最高実行速度(秒) | 5.47 | 5.40 | 7.11 | 5.63 |
| 最低実行速度(秒) | 6.08 | 6.15 | 7.66 | 6.12 |
いかがでしたでしょうか?
distkeyの張り方で、このようにパフォーマンスが変わってきます。またsortkeyと違いdistkeyは、検索対象ではなくidに対して設定することにより、パフォーマンスが大きく向上することがわかります。
また、sortkey/distkeyの両方を張ることで更にパフォーマンスを上げることもできますが、正しいキーを設定しないとパフォーマンスが落ちてしまうことも確認できました。
次回は『Amazon Redshift編~パフォーマンスチューニング 圧縮編~』として各カラムに対する compression type の選択方法について紹介します。お楽しみに!
——————————————————————————————————
ナレコムクラウドのFacebookに『いいね!』をクリックして頂くと
最新のお役立ちレシピが配信されます★
┏━━━━━━━━━━━━━┓
┃ナレコムクラウド Facebook┃
┗━━━━━━━━━━━━━┛
——————————————————————————————————
