前回は『Amazon Machine Learning編~別アカウントS3でDatasourcesを試してみる~』と題して、
Amazon Machine Learningで別アカウントS3をDatasuorcesにして試してみました。
今回は『Amazon Athena編~サンプルを試してみる~』と題して、Amazon Athenaでサンプルを試してみたいと思います。
Amazon Athenaとは
Amazon Athena はAmazon S3 内のデータを標準的な SQL を使用して簡単に分析できるサーバーレスクエリサービスで大型データセットをすばやく、簡単に分析できるようになります。
Athena はAmazon S3 にあるデータを指定して、スキーマを定義し、標準的な SQL を使ってデータのクエリを開始する事ができます。
Athenaがクエリを並列化して分散処理してるため多くの場合、数秒で結果が出てきます。
また、エンジンはPresto が使われており、CSV、JSON、ORC、Parquet などのさまざまな標準データフォーマットに対応します。
※PrestoとはFacebookが公開した新しい分散処理基盤
実行したクエリに対してのみ料金が発生します。
AthenaにはサンプルとしてELBのLOGが用意されております。
今回はそれを触ってイメージをつかみたいと思います。
1.試してみる
AthenaのサービスページでDATABASEに「sampledb」を設定してみます。
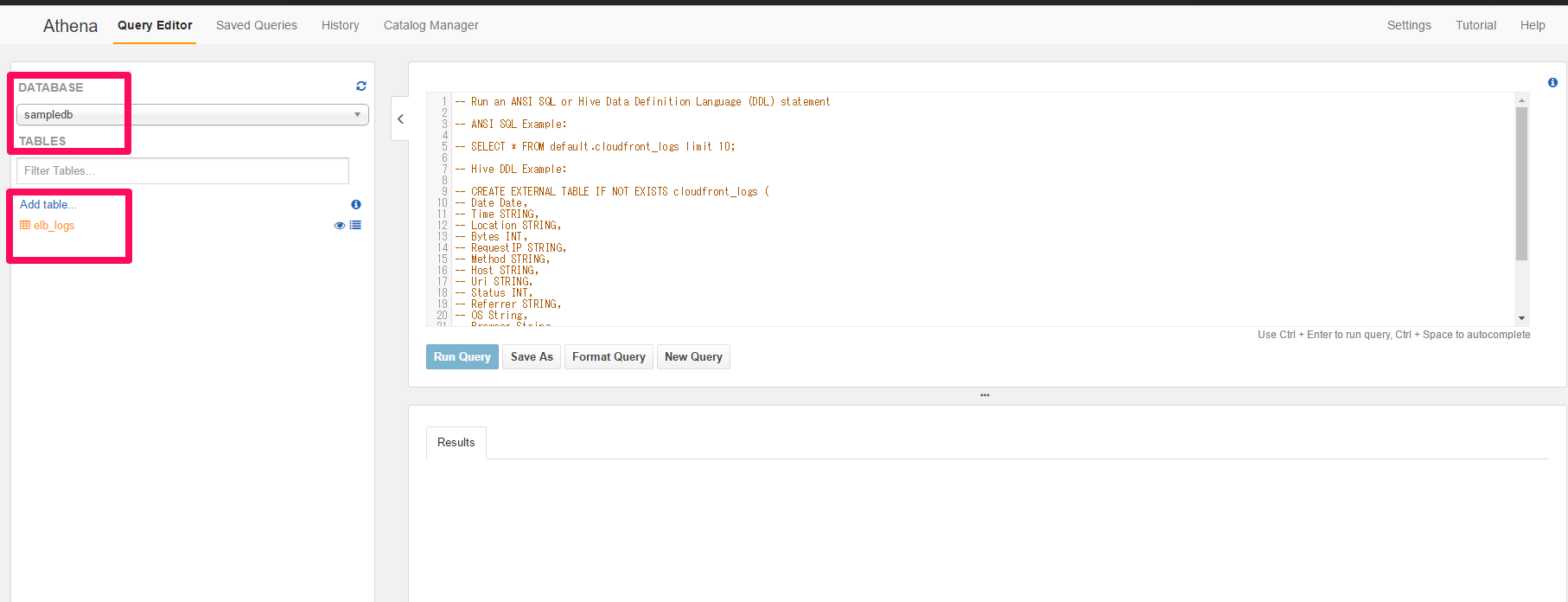
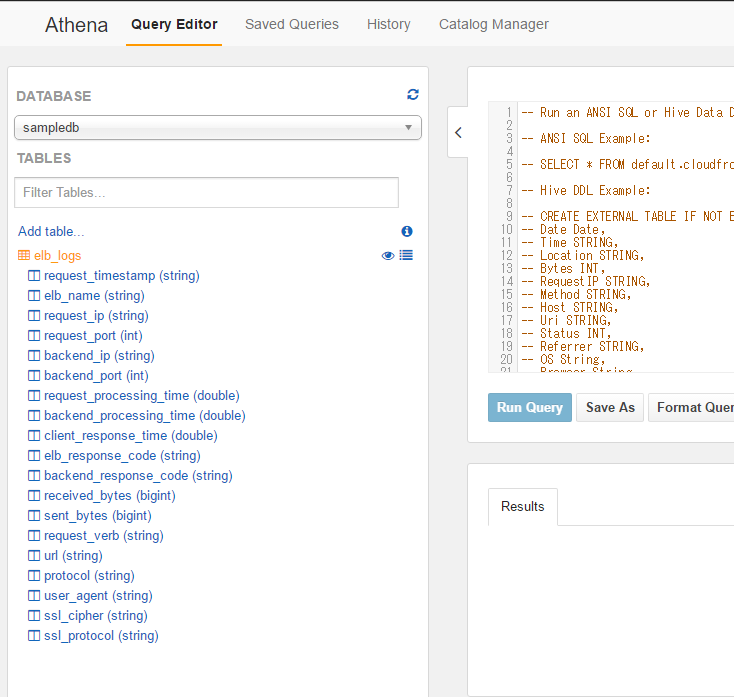
TABLESでelb_logsを選択して中身をみてみます。
各カラムが確認できます。
2.Catalog Managerをみてみる
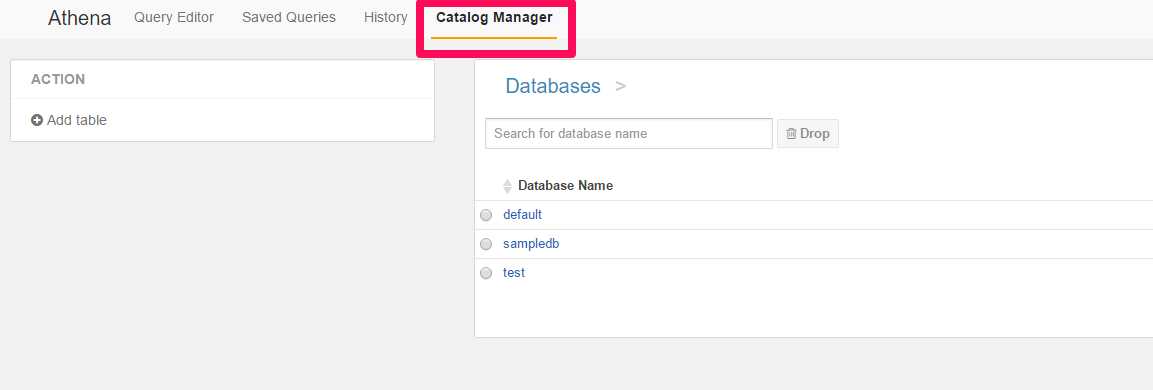
次にsampledbの情報を見てみたいと思います。
Catalog Managerのタブを選択してでたDB一覧からsampledbを選択します。
Tableでelb_logsを選択します。
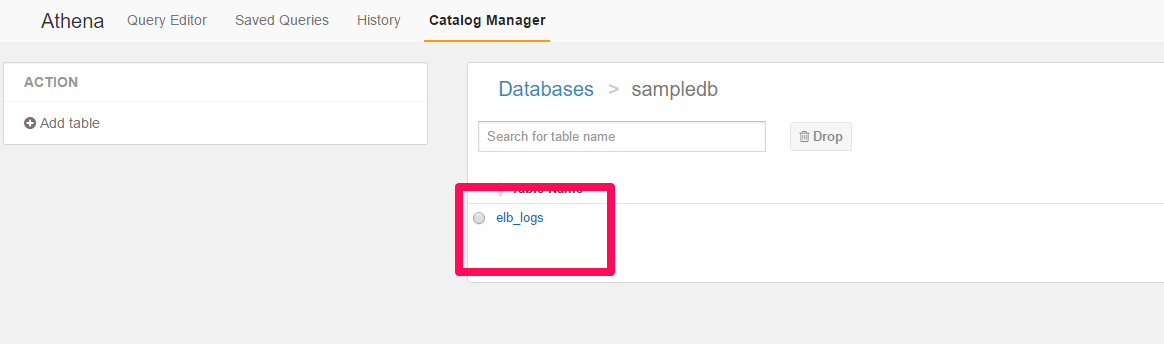
Columnsの情報が確認できます。
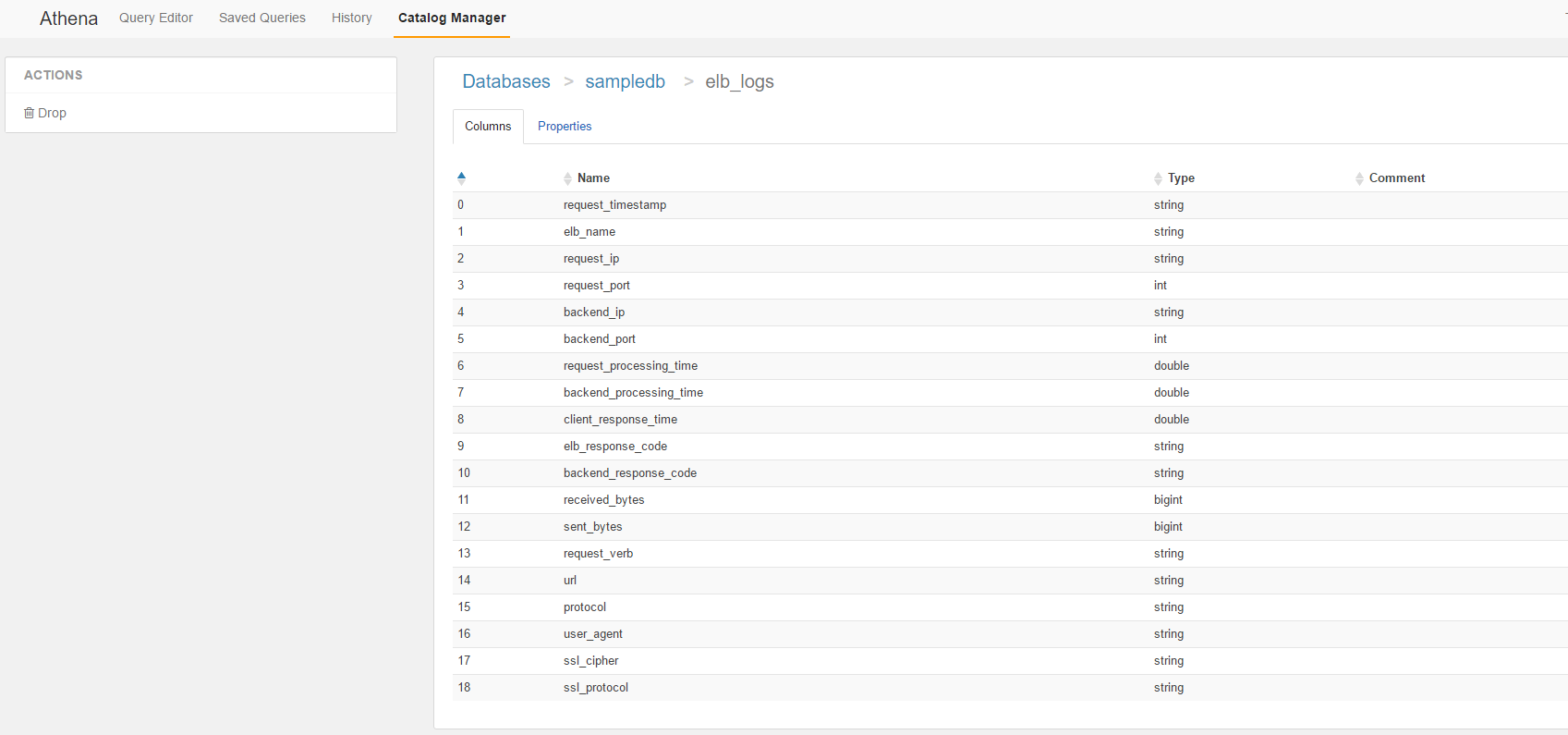
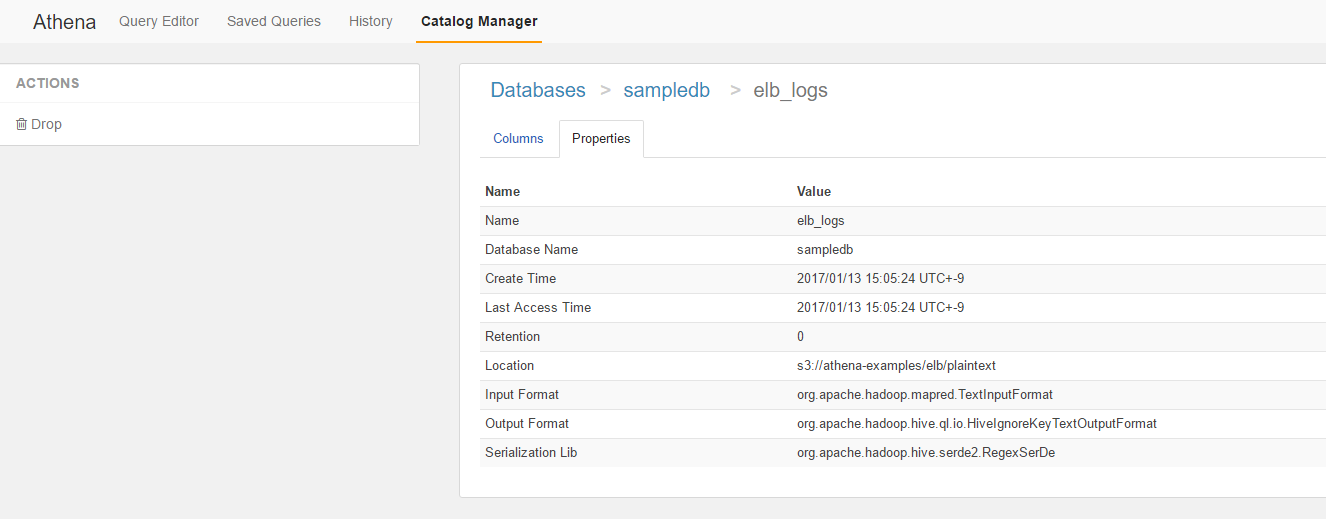
続いてPropertiesを見てみます。
LocationやFormat関連が確認出来ますね。
3.クエリーを叩いてみる
最後にクエリーを叩いてみます。
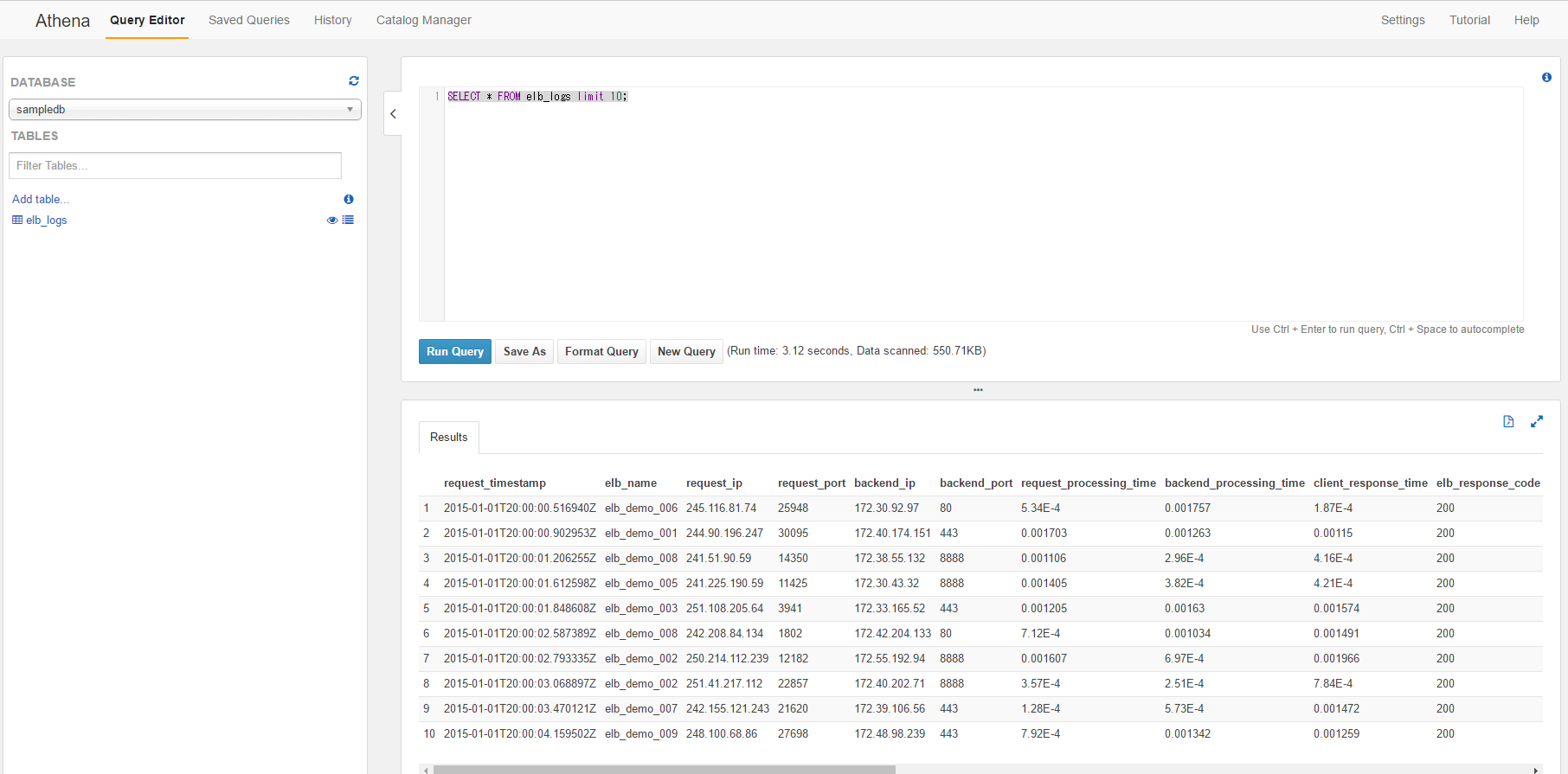
先ずは10件程度表示するクエリーを叩いてみます。
SELECT * FROM elb_logs limit 10;
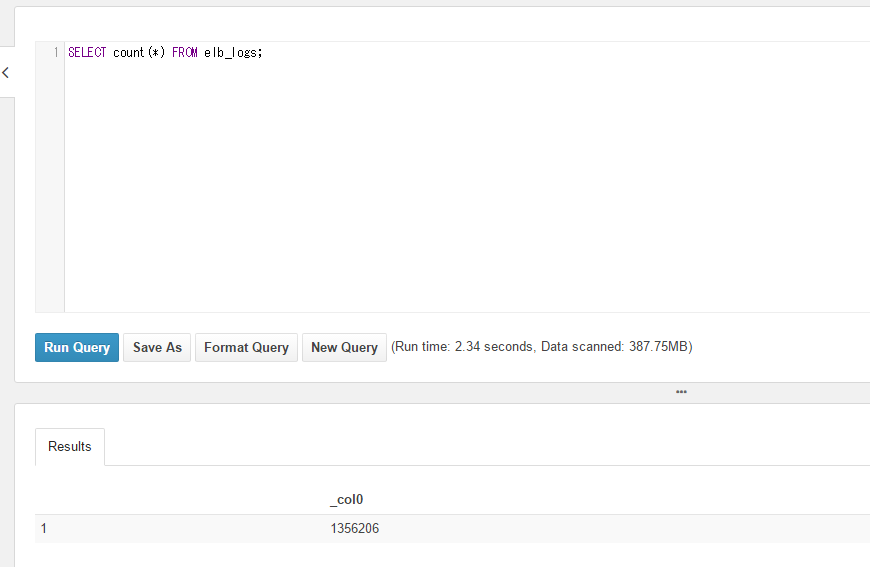
次に全件カウントを行ってみます。
2.31secondで返ってきました。
SELECT count(*) FROM elb_logs;
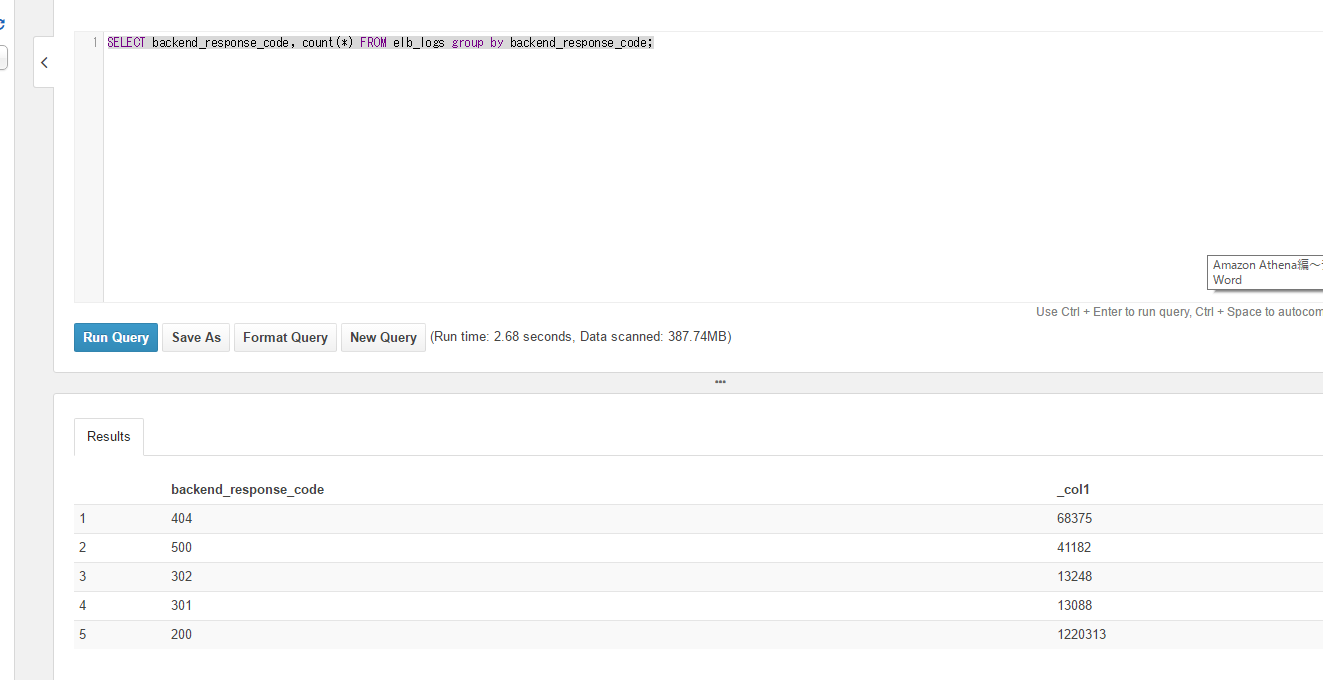
Group by も試してみます。
SELECT backend_response_code, count(*) FROM elb_logs group by backend_response_code;
いかがでしたでしょうか?
次回もお楽しみに!!!
次回記事:Amazon Athena編~JDBC接続を試してみる~
Amazon Web Serviceの構築・保守でお困りの方はこちら
