こんにちは!Tamaです!
ElasticMapReduceの使い方は以前当レシピで紹介させて頂きましたがコンソール画面や設定などアップデートにより変わっているところが多いため新しいコンソール画面と共に改めてご紹介させて頂きます!
以前と同じくAWSドキュメントの「Word Count Example」を試していきます。
準備
Amazon EMRを使用するための準備を行います。
・S3バケットの作成
・解析するデータのアップロード
・スクリプトのアップロード
S3バケットの作成
データのinputやoutputに利用するS3バケットを作成します。今回はTokyoリージョンに作成しました。
※EMRと別のリージョンにバケットを作成すると転送量が発生するため注意が必要です!
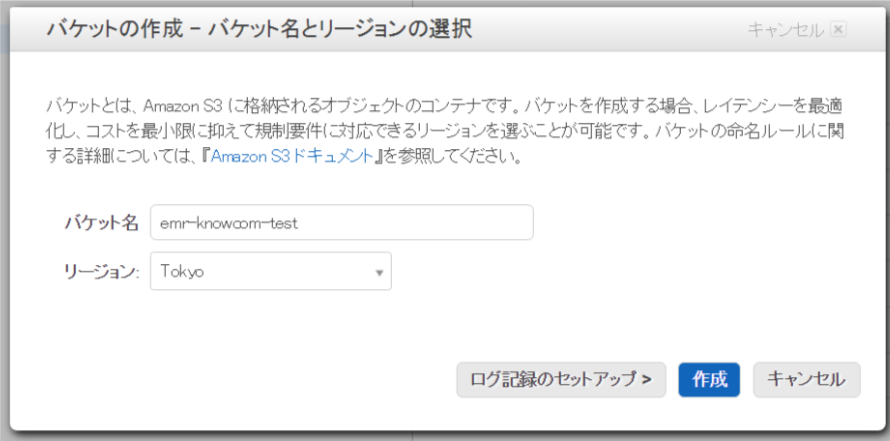
作成したバケット下にデータのinputとoutputを行うフォルダを作成します。

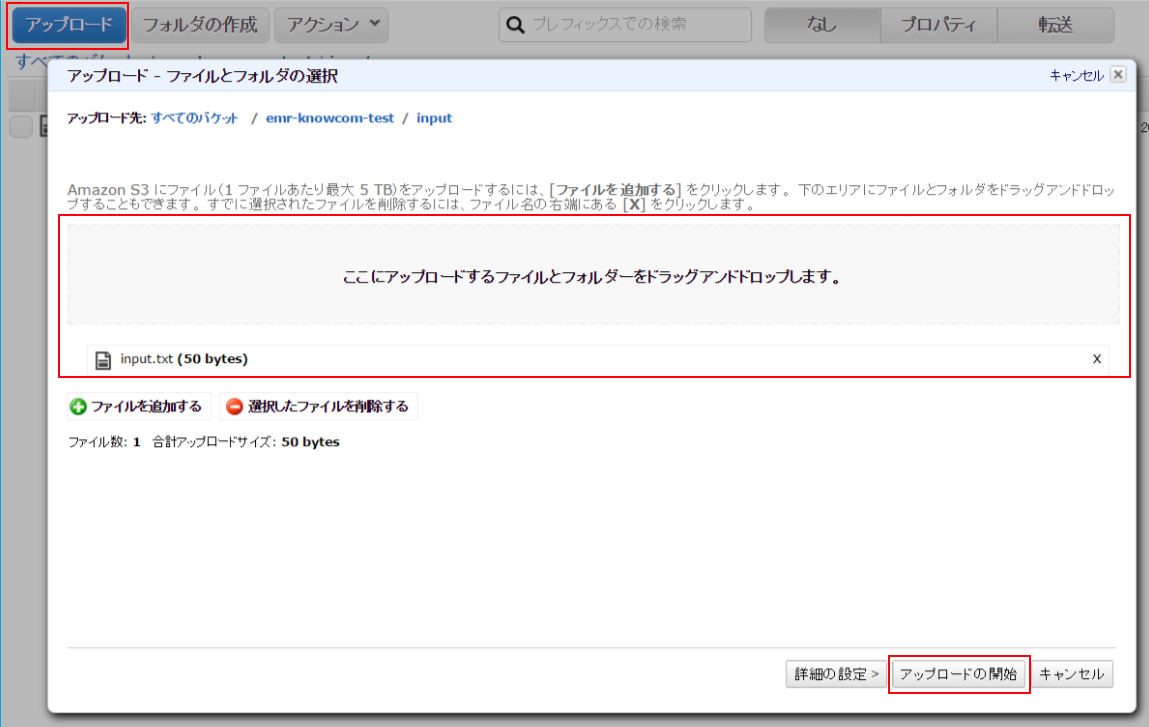
解析するデータのアップロード
アップロードするデータとしてinput.txtというタブ区切りのファイルを作成します。
|
1 2 |
two five four one four three five three three five two five five four four |
こちらを先程作成したバケットのinputフォルダにアップロードします。
スクリプトのアップロード
今回は「Streaming」というJOBタイプを利用します。
「Streaming」ではPython, Ruby, Perl, PHP, R, Bash, C++などの言語が利用可能です。
今回はPythonで記述されたサンプルスクリプトを用います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/usr/bin/python import sys import re def main(argv): pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*") for line in sys.stdin: for word in pattern.findall(line): print "LongValueSum:" + word.lower() + "\t" + "1" if __name__ == "__main__": main(sys.argv) |
[こちら]からもダウンロードが可能です。
こちらのファイルは先程作成したS3バケットの直下にアップロードします。
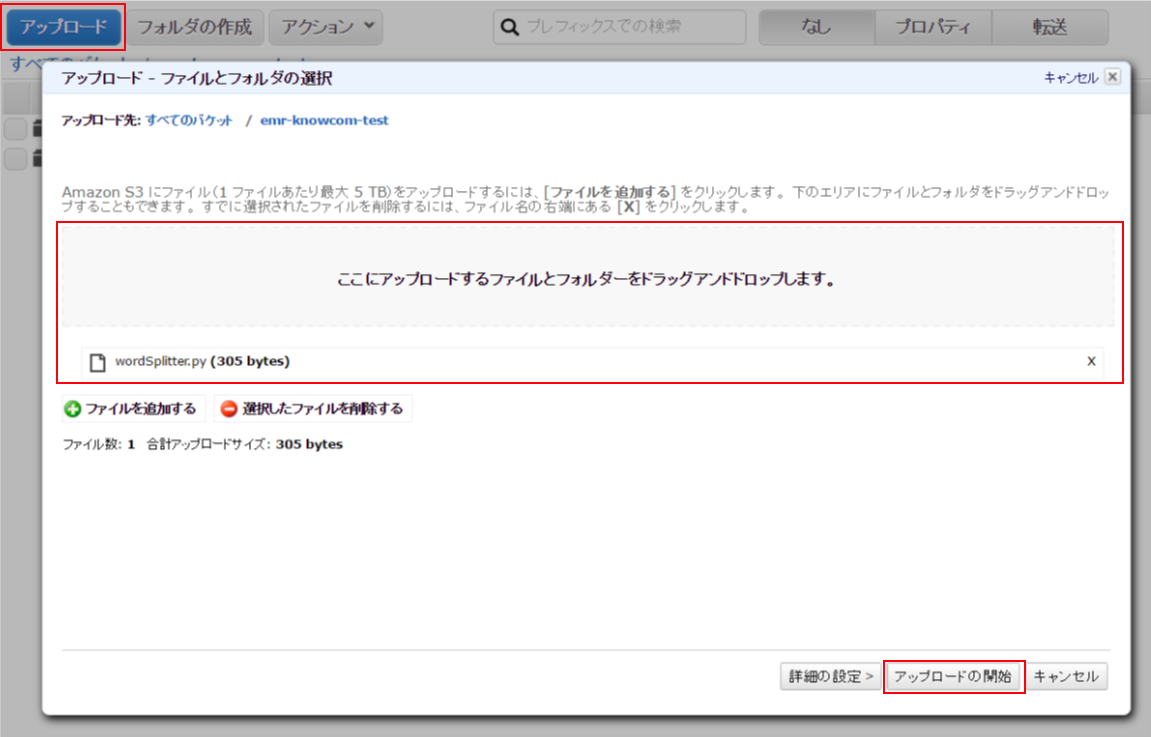
これでEMRを使用するための準備は完了です。
今回は以上になります!
お疲れさまでした!
次回はEMRを立ち上げ実際に処理を行います。
[Renewal! Amazon EMR編~ElasticMapReduceの使い方パート②~]
次回記事:Renewal! Amazon EMR編~ElasticMapReduceの使い方パート②~
またお会いしましょう!
