はじめに
前回は、Sagemakerいじってみた1としてベースとなるノートブックインスタンスを作成するところまで紹介しました。
今回はその続きで、Jupiterノートブックを使って、S3にデータをアップロードする方法を紹介したいと思います。
記事の概要
本記事の内容は以下になります
- S3の作成~データのアップロードまでを解説します
- IAMロールの取得に関しても説明しております
- 「Amazon Sagemaker」の導入時にデータアップロード方法をお探しの方やアップロード時に詰まっている方に向けて執筆しております。
S3バケット作成
まずは、データを入れるためのS3バケットを作成していきます。
S3バケットを作成するうえで、注意する点が1点あります。
それは、バケット名に「Sagemaker」を含めることです。
こうすることでノートブックインスタンスを作成する際に設定をしたデフォルトで設定されているIAMポリシーでSagemakerがS3バケットにアクセスする権限を付与することができます。
Jupiterノートブック作成
前回作成したノートブックインスタンスにJupiterノートブックを作成します。
ノートブックを作成するには、Filesタブの右上New▼をクリックします。
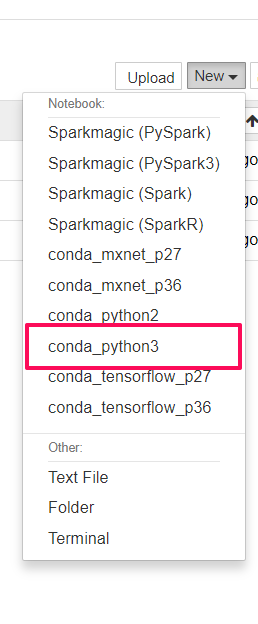
次に、今回はPython3を使うのでプルダウンから「Python3」を選択します。
これで、Python3のコードを書くためのノートブックが作成完了しました。
次に以下のコードをノートブックに入力して、先にセットアップをしているIAMロールを取得します。
|
1 2 3 4 5 |
from sagemaker import get_execution_role role = get_execution_role() bucket='bucket-name' |
‘bucket-name’
→ここに先に作成してあるSagemakerが含まれてるバケット名を入力します。
次に以下のコードを実行すると指定したWEBサイトからMNISTデータセットをダウンロードしてきます。
- ダウンロードした圧縮ファイルを解凍
- 内のモデルトレーニング用のデータセット
- モデルトレーニング後に検証するためのデータセットのデータセットをノートブックのメモリに読み込みます。
|
1 2 3 4 5 6 7 8 |
%%time import pickle, gzip, numpy, urllib.request, json # Load the dataset urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz") with gzip.open('mnist.pkl.gz', 'rb') as f: train_set, valid_set, test_set = pickle.load(f, encoding='latin1') |
次に以下のコードを入力することで先ほど読み込んだデータセットを調べることができます。
通常この段階で、データセットを調べてデータ加工を実施しますが、今回はデータセット内の画像を表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
%matplotlib inline import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (2,10) def show_digit(img, caption='', subplot=None): if subplot==None: _,(subplot)=plt.subplots(1,1) imgr=img.reshape((28,28)) subplot.axis('off') subplot.imshow(imgr, cmap='gray') plt.title(caption) show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30])) |
以下のコードでは、データフォーマットを変換し、S3にデータをアップロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
%%time from sagemaker.amazon.common import write_numpy_to_dense_tensor import io import boto3 data_key = 'kmeans_lowlevel_example/data' data_location = 's3://{}/{}'.format(bucket, data_key) print('training data will be uploaded to: {}'.format(data_location)) # Convert the training data into the format required by the SageMaker KMeans algorithm buf = io.BytesIO() write_numpy_to_dense_tensor(buf, train_set[0], train_set[1]) buf.seek(0) boto3.resource('s3').Bucket(bucket).Object(data_key).upload_fileobj(buf) |
ノートブックを使って、S3にアップロードすることができました。
終わりに
今回はS3にデータをアップロードする方法を紹介していきました。
コードをコピーして実行していくだけなので、難しいと思うポイントは少なかったです。
今後は時間のある際に、アップロードをしたデータをトレーニングしていきたいと思います。
最後まで読んでいただきありがとうございました。
